刚刚NeurIPS 2025上,清华大学和上海交通大学的一篇研究《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》拿到了罕见的满分评价:四个6分。
他们就为了搞清楚强化学习是否真的能让大语言模型拥有更好的思考能力。
答案有些扎心:不能。
研究聚焦于”带可验证奖励的强化学习”(RLVR)。结论很直接:RLVR在小规模数据上能提升答案准确性,但并未产生新的推理模式。模型的推理能力上限,依然由它的基础模型决定。https://wxa.wxs.qq.com/tmpl/ok/base_tmpl.html
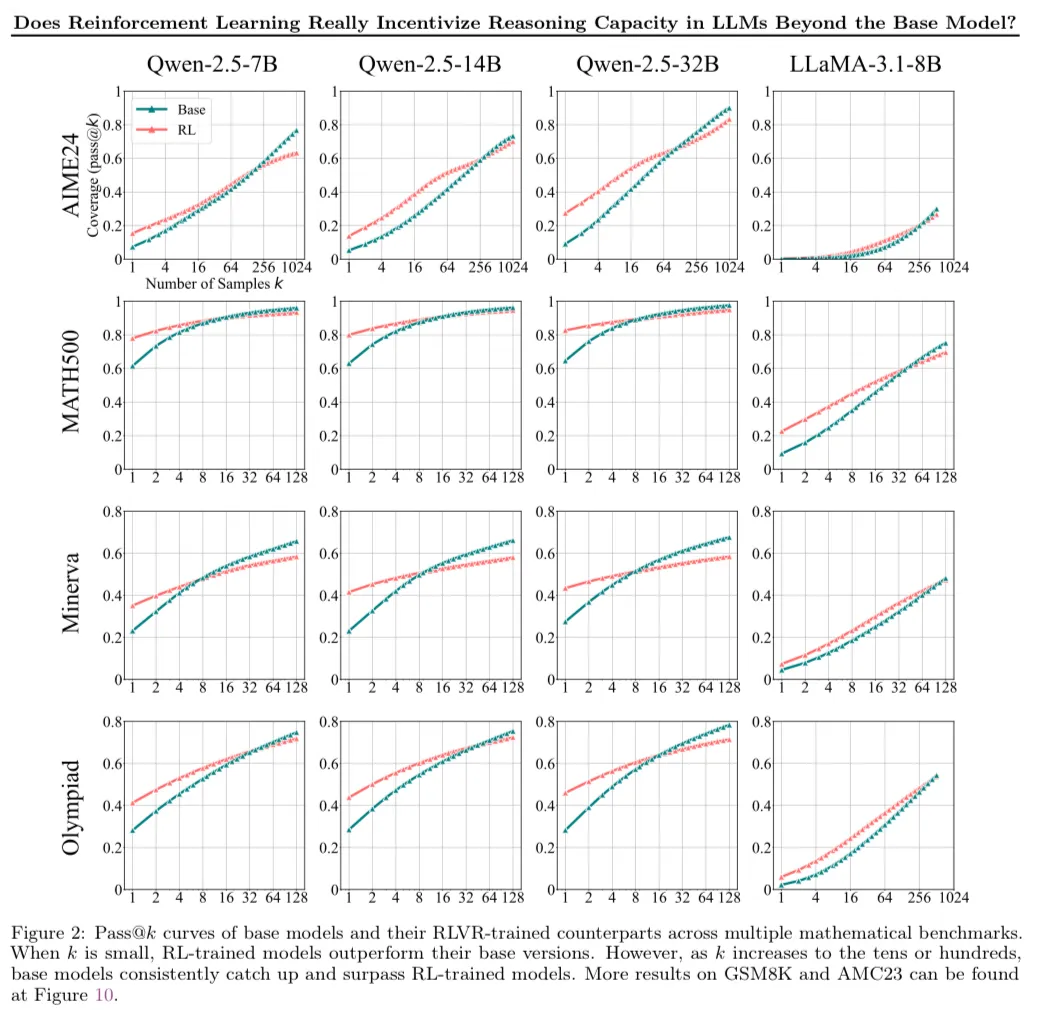
研究人员测试了六种RLVR变体,发现性能提升很快达到平台期。这意味着强化学习主要作用是对已有推理能力进行微调、优化,而非从根本上重塑或创造新的推理路径。
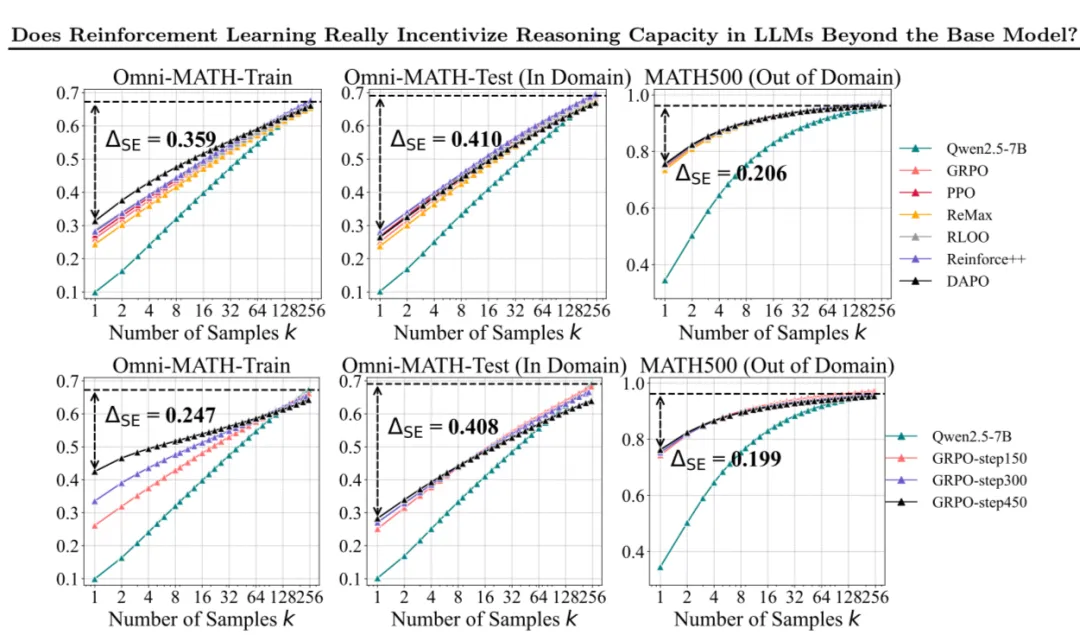
更有意思的是,真正显示出推理能力”涌现”迹象的,是知识蒸馏技术,而非强化学习。
强化学习更像是巩固已有的知识先验,而非在全新概念上实现迭代改进。不过这也不得不让大家重新思考:如何构建真正能够自我改进的大模型。
值得一提的是,这是今年NeurIPS唯一获得满分的论文,恭喜这些研究者。但对于那些指望强化学习让AI突然变聪明的人来说,这个结果可能不太友好。
若您对人工智能感兴趣,可添加数字化转型网小助手思思微信加入人工智能交流群。若您在寻找人工智能供应商,可联系数字化转型网小助手思思(17757154048,微信同号)

若您为人工智能服务商,可添加数字化转型网小助手Nora,加入人工智能行业交流群。

若您为人工智能创业者,可添加数字化转型网社群主理人Carina,加入人工智能创业交流群。

声明:本文来自网络,版权归作者所有。文章内容仅代表作者独立观点,不代表数字化转型网立场,转载目的在于传递更多信息。如有侵权,请联系我们。数字化转型网www.szhzxw.cn

本文由数字化转型网(www.szhzxw.cn)转载而成,来源于网络;编辑/翻译:数字化转型网(Professionalism Achieves Leadership 专业造就领导者)默然