
继ChatGPT之后,OpenAI又推出一款震惊科技圈的产品。2月16日凌晨,OpenAI宣布推出文生视频大模型——Sora,黑客帝国世界来临!
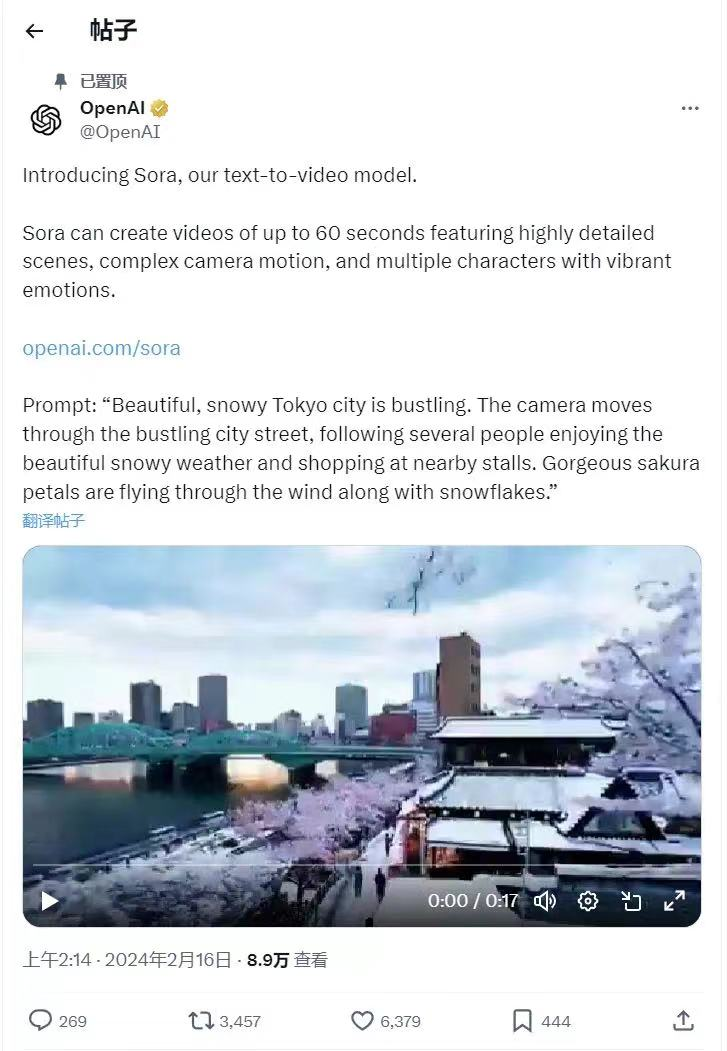
Sora是基于过去对DALL·E和GPT的研究基础构建,利用DALL·E 3的重述提示词技术,为视觉模型训练数据生成高描述性的标注,因此模型能更好的遵循文本指令。通过文本指令,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。
对于OpenAI视频生成模型的出现,业内其实早有预期,但仍有人评价称“比想象中来得更快”,亦有人振奋地表示“我们真的看到新工业革命来临”。 数字化转型网(www.szhzxw.cn)
据OpenAI官网介绍,OpenAI正在教人工智能理解和模拟运动中的物理世界,目标是训练模型,帮助人们解决需要现实世界交互的问题。也就是说,OpenAI最终想做的,其实不是一个“文生视频”的工具,而是一个通用的“物理世界模拟器”。也就是世界模型,为真实世界建模。
OpenAI发布的文生视频模型Sora能够生成具有多个角色、特定类型的运动以及主题和背景的准确细节的复杂场景。不仅了解用户在提示中要求的内容,还了解这些东西在物理世界中的存在方式。
该模型对语言有深刻的理解,使其能够准确地解释提示并生成表达生动情感的引人注目的角色。
Sora还可以在单个生成的视频中创建多个镜头,以准确保留角色和视觉风格。
那么,Sora的出现,对人工智能的整体发展,到底意味着什么?
简单来说,Sora通过学习视频,来理解现实世界的动态变化,并用计算机视觉技术模拟这些变化,从而创造出新的视觉内容。
换句话说,Sora学习的不仅仅是视频,也不仅仅是视频里的画面、像素点,还在学习视频里面那个世界的“物理规律”。
而大部分的视频软件,并不理解“物理规律”。他们处理的对象,只是画面。而不是画面里的人和物。但是Sora,似乎是理解的。 数字化转型网(www.szhzxw.cn)
而除了对现实世界的影响,作为刚刚面世的全新技术,Sora也存在不足之处。
对于Sora当前存在的弱点,OpenAI指出它可能难以准确模拟复杂场景的物理原理,并且可能无法理解因果关系。
该模型还可能混淆提示的空间细节,例如混淆左右,并且可能难以精确描述随着时间推移发生的事件,例如遵循特定的相机轨迹。
在Sora官网,一共展示了48个文本生成的视频。我们来看一个文生视频的效果吧!
提示:一位时尚的女人走在东京的街道上,街道上到处都是温暖的发光霓虹灯和动画城市标志。她身穿黑色皮夹克,红色长裙,黑色靴子,背着一个黑色钱包。她戴着墨镜,涂着红色口红。她自信而随意地走路。街道潮湿而反光,营造出五颜六色的灯光的镜面效果。许多行人四处走动。
视频请视频号搜索数字化转型网进行查看!

翻译:
The Matrix world is here! OpenAI releases video AI model Sora
After ChatGPT, OpenAI launched another product that shocked the tech world. In the early morning of February 16, OpenAI announced the launch of Vincennes video model – Sora, the Matrix world is coming!
Sora is built on the basis of previous research on DALL·E and GPT, and uses the restatement prompt word technology of DALL·E 3 to generate highly descriptive annotations for the training data of visual models, so that the models can better follow the text instructions. Using text commands, Sora can directly output up to 60 seconds of video with highly detailed backgrounds, complex multi-angle shots, and emotional multiple characters. 数字化转型网(www.szhzxw.cn)
For the emergence of OpenAI video generation model, the industry has long been expected, but there are still comments that “faster than imagined”, and some people are excited to say that “we really see the new industrial revolution coming.”
According to OpenAI’s website, OpenAI is teaching artificial intelligence to understand and simulate the physical world in motion, with the goal of training models to help people solve problems that require real-world interaction. In other words, OpenAI ultimately wants to make, in fact, not a “Vincennes video” tool, but a general purpose “physical world simulator.” That’s world modeling, modeling the real world.
Sora, the Vincennes video model released by OpenAI, is capable of generating complex scenes with multiple characters, specific types of movement, and accurate details of themes and backgrounds. Understand not only what users are asking for in their prompts, but also how those things exist in the physical world.
The model has a deep understanding of language, allowing it to accurately interpret cues and generate compelling characters that express vivid emotions.
Sora can also create multiple shots within a single generated video to accurately preserve character and visual style. 数字化转型网(www.szhzxw.cn)
So what does the emergence of Sora mean for the overall development of artificial intelligence?
In simple terms, Sora learns video to understand the dynamics of the real world and uses computer vision technology to simulate those changes to create new visual content.
In other words, Sora is not only learning the video, nor is it just learning the images and pixels in the video, but also learning the “physical laws” of the world in the video.
Most video software, however, does not understand the “laws of physics”. The objects they’re dealing with, they’re just pictures. Not the people and things in the picture. But Sora seems to understand.
In addition to its impact on the real world, Sora, as a new technology that has just been released, also has shortcomings.
Regarding Sora’s current weaknesses, OpenAI points out that it may struggle to accurately model the physics of complex scenarios and may fail to understand cause and effect.
The model can also confuse spatial details of prompts, such as confusing left and right, and may have difficulty accurately describing events that occur over time, such as following a particular camera trajectory.
On Sora’s website, a total of 48 text-generated videos are displayed. Let’s see the effect of a Vincennes video! 数字化转型网(www.szhzxw.cn)
Hint: A stylish woman walks down a Tokyo street filled with warm glowing neon lights and animated city signs. She was wearing a black leather jacket, a long red dress, black boots and carrying a black purse. She was wearing dark glasses and red lipstick. She walked confidently and casually. The streets are damp and reflective, creating a mirror-like effect of colorful lights. Many pedestrians are walking around.
本文由数字化转型网(www.szhzxw.cn)根据公开资料整理撰写而成,作者:数字化转型网小编;编辑/翻译:数字化转型网宁檬树。
免责声明: 本网站(http://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。


