数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!

一、EMO
1. 概述
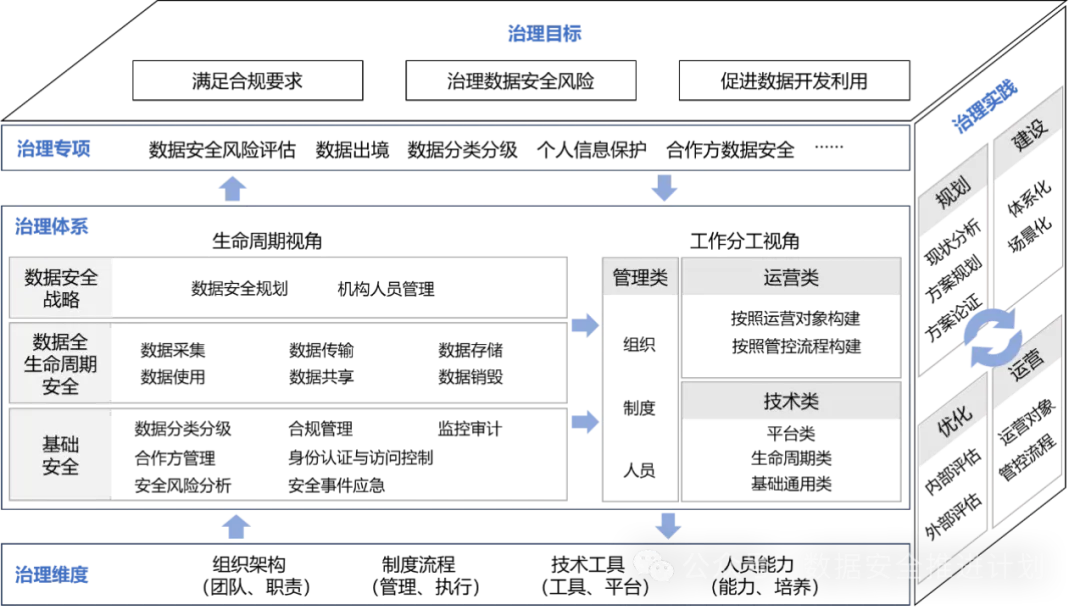
EMO:EmotePortraitAlive是由阿里巴巴的HumanAIGC团队开发的一种新型生成式AI模型。该模型能够生成具有丰富面部表情和头部姿势的声音肖像视频,输入一张参考图像和声音音频,就可以生成相应的视频内容。该模型不仅能生成说话视频,还能生成各种风格的歌唱视频,无论是在表现力还是真实感方面都显著优于现有先进方法。数字化转型网www.szhzxw.cn
2. 核心技术
EMO的整体框架与DiffusionTalk和DiffusionHead类似,都是利用Diffusion来生成,也是根据一个参考图像来逐帧生成图片,最后得到视频。但是,EMO的工作过程分为两个主要阶段:首先,利用参考网络(ReferenceNet)从参考图像和动作帧中提取特征;然后,利用预训练的音频编码器处理声音并嵌入,再结合多帧噪声和面部区域掩码来生成视频。此外,EMO还采用了两种形式的注意力机制:参考注意力和音频注意力,以及时间模块,以调节角色的动作并与音频信号相匹配。
3. 性能与优势
EMO能够生成与输入音频同步且在表情和头部姿势上富有表现力的肖像视频,超越了传统技术的限制,创造出更加自然和逼真的动画效果。它的出现解决了在说话头部视频生成中增强现实性和表现力的挑战,传统技术往往无法捕捉人类表情的全部范围和个人面部风格的独特性。EMO通过直接的音频到视频合成方法, bypassing the need for intermediate 3D models or facial landmarks,从而提高了生成视频的质量和真实性。数字化转型网www.szhzxw.cn
4. 应用领域
EMO技术不限于特定语言或音乐风格,能够处理多种语言的音频输入,并且支持多样化的肖像风格,包括历史人物、绘画作品、3D模型和AI生成内容等。它能够实现不同演员之间的表现转换,使得一位演员的虚拟形象能够模仿另一位演员或声音的特定表演,拓展了角色描绘的多样性和应用场景。
5. 开发团队
EMO是由阿里巴巴智能计算研究院的四位研究员Linrui Tian、Qi Wang、Bang Zha共同开发的。
6. 开源状态
关于开源状态,搜索结果中并未明确提及。但在搜索结果中提到,虽然HumanAIGC团队已经有一段时间没有开源代码了,但技术方向还是值得一看的。
二、AnimateAnyone
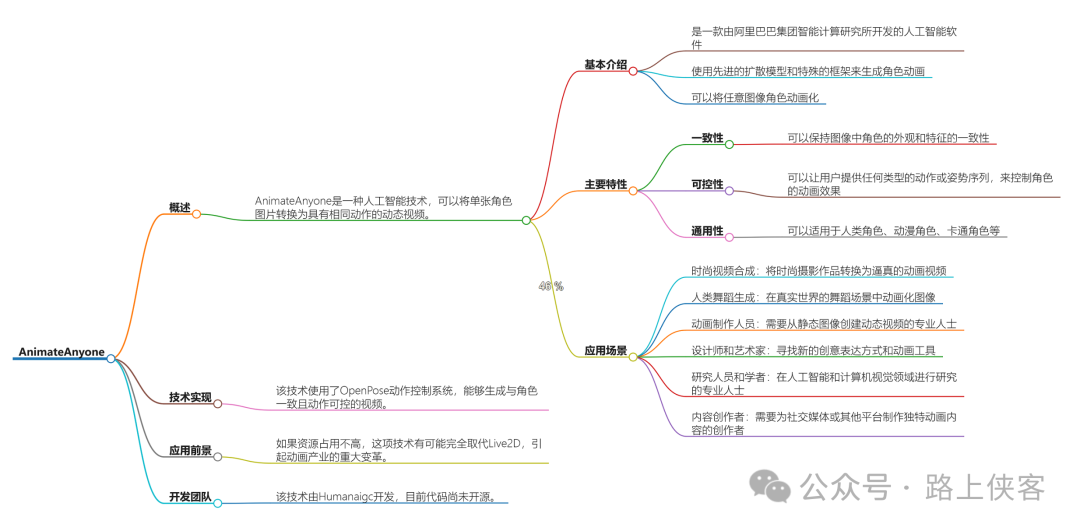
1. AnimateAnyone
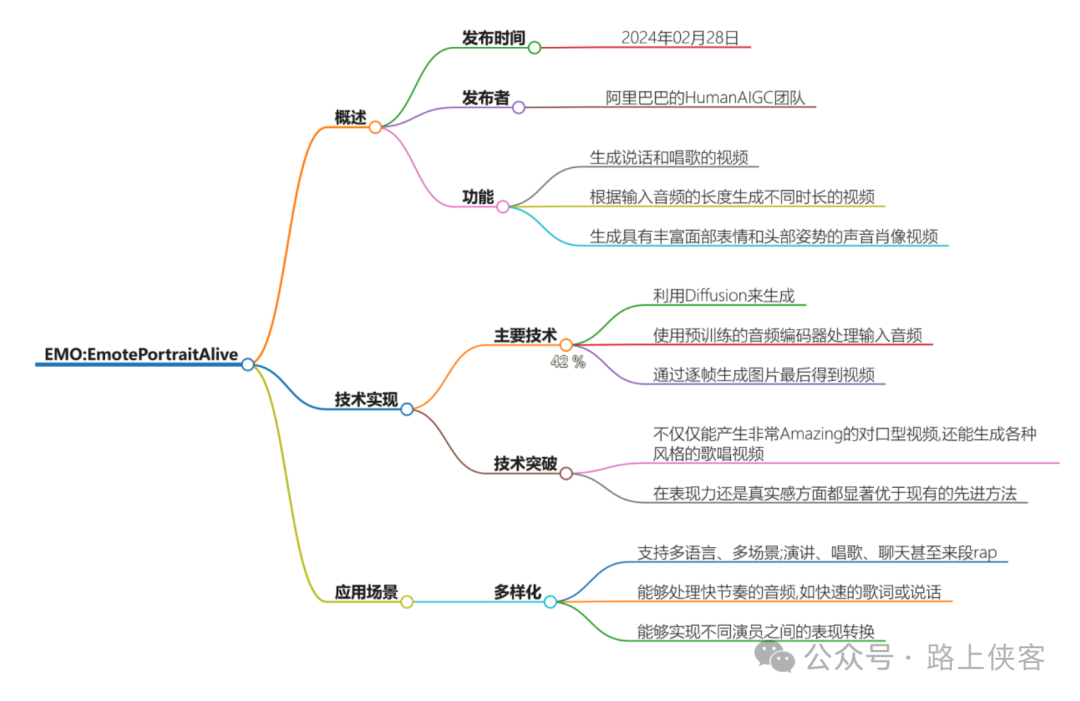
AnimateAnyone是由阿里巴巴集团智能计算研究院开发的一款人工智能软件,它能够将静态图像转化为高度逼真的动态视频。这项技术使用了先进的扩散模型,使得用户只需提供一张角色图片以及一些预设的动作序列,就能够生成生动的动画视频。此外,AnimateAnyone还可以保持图像中角色的外观和特征的一致性,适用于人类角色、动漫角色、卡通角色等多种类型。
2. 功能与特点
AnimateAnyone的主要特点是它的可控性和一致性。用户可以提供任何类型的动作或姿势序列,来控制角色的动画效果,同时它也能保持角色外观和特征的原始一致性。这种技术不仅适用于娱乐领域,还可以用于教育和营销等领域,创作出有趣、个性化的视频内容。
3. 使用与体验
AnimateAnyone的使用方法相对简单,用户只需上传一张角色图片和选择一些预设的动作序列,软件就会自动生成一个动画视频。根据搜索结果中的体验入口,用户可以通过点击特定链接来体验这款软件。尽管目前AnimateAnyone还没有正式上线,但它已经引起了广泛的关注,并在社交媒体上产生了大量的讨论。
4. 社会影响与潜在应用
AnimateAnyone的出现可能会对图像生成和视频生成领域产生深远影响。它不仅降低了视频生成的成本,还能够让实时渲染成为可能,为增强现实(AR)等领域带来新的机遇。此外,这项技术还有助于提升购物体验,通过提供个性化的服装搭配建议,帮助消费者更轻松地找到合适的服装搭配。在未来,AnimateAnyone有可能与其他行业的企业进行合作,推动更多创新应用的出现。
5. 结论
AnimateAnyone是一项令人兴奋的技术,它将静态图像转化为动态视频的能力为创意产业带来了新的可能性。尽管目前它还处于开发阶段,但已经吸引了大量关注,并有望在未来对社会产生积极影响。如果您对这项技术感兴趣,可以通过访问其官方网站或关注相关的社交媒体账号来获取更多关于AnimateAnyone的信息和发展动态。数字化转型网www.szhzxw.cn
三、OutfitAnyone:AI虚拟换装技术
1. OutfitAnyone的基本介绍
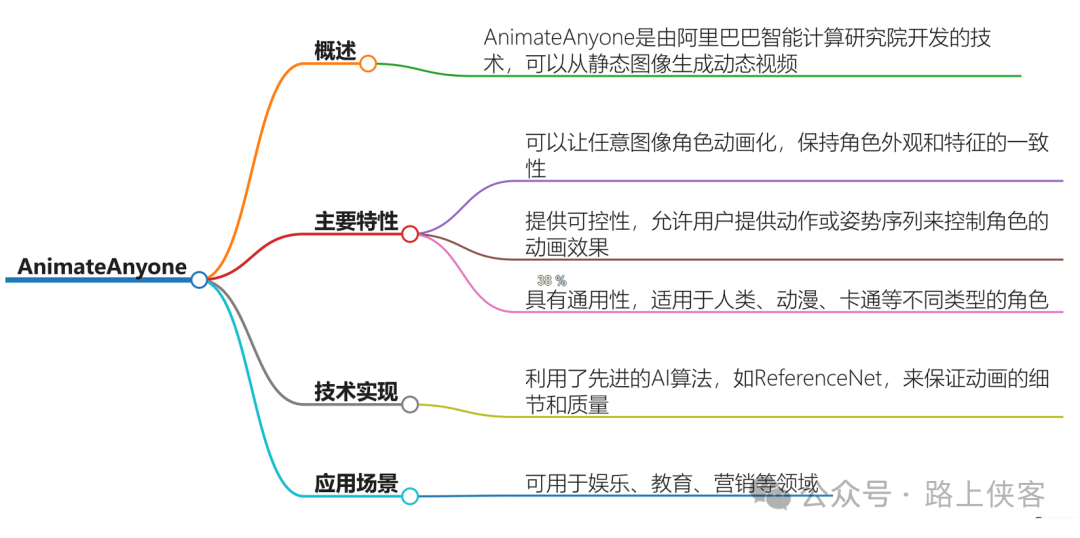
OutfitAnyone是由阿里巴巴推出的高质量虚拟换装技术,它采用了先进的深度学习和计算机视觉方法,能够通过用户的全身照和服装照片,生成高分辨率、高质量、高逼真的虚拟试穿图像。这项技术的厉害之处在于它的可扩展性,无论是改变姿势、调整身体形状,还是异形的服装,它都能应对自如。用户可以通过上传全身照片和想要试穿的服装照片,体验逼真的虚拟试穿效果。
2. OutfitAnyone的主要功能
OutfitAnyone的主要功能包括虚拟试穿、搭配建议和购物功能。在虚拟试穿功能中,用户只需上传自己的照片,然后选择不同款式的服装,生成穿着这些服装的虚拟形象。该功能可以帮助用户在购买服装之前,先进行虚拟试穿,避免买错尺码或不合身的问题。搭配建议功能可以根据用户的照片和个人喜好,分析用户的穿搭风格,并提供搭配建议,帮助用户快速找到适合自己的服装款式。此外,OutfitAnyone还内置了购物功能,用户可以直接在软件中购买自己喜欢的衣服,提供便利的购物体验。
3. OutfitAnyone的技术实现
OutfitAnyone是基于双流条件扩散模型和虚拟试穿技术实现的,它能够灵活处理衣物变形,并生成更逼真的效果。该技术具有极高的可扩展性,可以适用于从动漫角色到真实人物的各种图像,同时调整姿势和身体形状等因素。OutfitAnyone的虚拟试穿功能采用了基于生成式对抗网络(GAN)的技术,该技术可以将服装的图案纹理与用户的照片进行融合,生成逼真的虚拟形象。
4. OutfitAnyone的应用场景
OutfitAnyone适用于多个领域,包括电商平台、虚拟试衣场景、动漫角色设计等。无论是在线购物者希望提高购物体验,还是设计师希望为动漫角色设计服装,OutfitAnyone都能提供强大的支持。例如,设计师可以使用OutfitAnyone为动漫角色设计各种服装样式,只需要上传他们想要试穿的衣服的图片,OutfitAnyone将自动处理衣物与人物的匹配,展示最终效果。
5. 如何体验OutfitAnyone
如果用户想要体验OutfitAnyone,可以通过访问官方网站或点击官方体验链接来开始体验。在使用过程中,需要注意的是,模特是固定的,不能上传或修改,只支持用户上传自己的服装。
四、Cloth2Tex
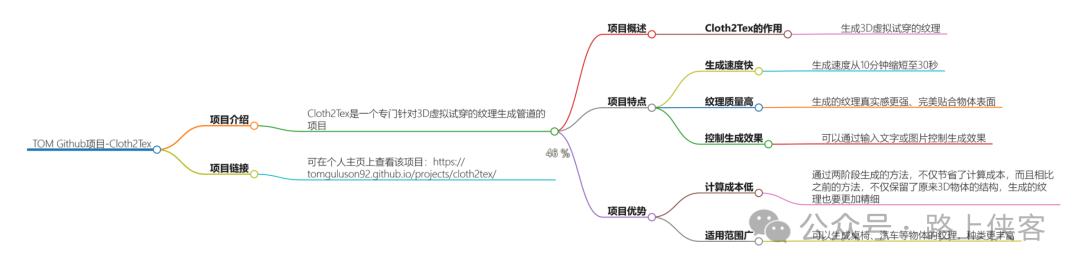
1. TOMGULUSON92 的项目 “Cloth2Tex”
TOMGULUSON92 在其个人主页 tomguluson92.github.io 上有一个名为 “Cloth2Tex” 的项目。该项目是一个定制化的布料纹理生成管道,用于3D虚拟试穿 。该项目的目标是帮助用户快速生成高质量的布料纹理,从而提高3D虚拟试穿的效果和效率。
2. 项目描述
“Cloth2Tex” 是一个针对3D虚拟试穿的应用,它提供了一个定制化的布料纹理生成管道。该管道能够生成逼真的布料纹理,从而提升3D虚拟试穿的沉浸感和真实感。该项目的主要特点是速度提升2-3倍,这表明它能够在短时间内生成大量的布料纹理,非常适合需要大量纹理数据的场景。
3. 项目成果
TOMGULUSON92 的 “Cloth2Tex” 项目已经在学术界获得了认可。该项目的相关论文已被多个知名会议收录,例如 “ACIS 2022:324” 。这表明该项目的研究成果得到了同行的肯定,具有一定的学术价值和技术水平。数字化转型网www.szhzxw.cn
4. 项目影响
“Cloth2Tex” 项目的实施,对于提高3D虚拟试穿的质量和效率具有重要的实际意义。在虚拟现实和增强现实领域,逼真的布料纹理对于提供更好的用户体验至关重要。该项目通过自动化纹理生成过程,可以帮助开发者和设计师节省大量的时间和精力,从而推动相关技术的发展和应用。
5. 项目目标
该项目的主要目标是提供一个高效、易用的布料纹理生成解决方案。通过对现有方法的优化和改进,该项目旨在大幅提高纹理生成的速度,同时保持或提高纹理的质量。此外,该项目还可能涉及布料模拟、纹理合成等方面的研究,以实现更真实的布料效果。
6. 项目未来发展方向
考虑到 “Cloth2Tex” 项目的成功和影响力,未来的研发方向可能会包括以下几个方面:
1). 多尺度纹理生成:开发算法以生成不同分辨率的布料纹理,以适应不同的应用场景和设备性能。
2). 实时纹理生成:探索实时光线跟踪和其他实时渲染技术,以实现实时的布料纹理生成。
3). 用户交互和定制化:引入更多的用户交互元素,允许用户自定义布料的纹理和外观。
4). 跨平台支持:扩展项目,使其能够在不同的游戏引擎和3D软件中无缝集成。
通过这些方向的研发,”Cloth2Tex” 项目有望在未来继续推动虚拟现实和增强现实领域的发展。
五、MaTe3D
1. MaTe3D概述
MaTe3D是一个同时支持掩码和文本编辑的人脸编辑技术,它是由Humanaigc开发的。这项技术主要应用于人脸编辑领域,可以通过掩码和文本编辑来实现对人脸的精细操控。MaTe3D的相关论文已被发表在arXiv上,其主页和GitHub仓库也可以供用户了解和使用这项技术。
2. MaTe3D的技术特点
MaTe3D作为一种人脸编辑技术,具有以下技术特点:
掩码和文本编辑的支持:MaTe3D允许用户通过掩码和文本编辑来控制人脸的变化,这种细粒度的控制使得编辑结果更加精确和自然。数字化转型网www.szhzxw.cn
人脸编辑的创新方法:MaTe3D采用了创新的人脸编辑方法,能够在人脸图像上进行细致的编辑操作,这对于需要处理人脸图像的应用场景非常有用。
开源社区的支持:MaTe3D的代码托管在GitHub上,得到了开源社区的关注和支持。这表明该技术在开发者社区中有一定的活跃度,并且有可能不断地进行更新和优化。
3. MaTe3D的应用前景
MaTe3D在人脸编辑领域的应用前景广阔,它可以应用于视频特效、影视制作、虚拟现实等多个领域。通过对人脸的精细编辑,可以创造出各种有趣的效果和应用场景。此外,由于MaTe3D的技术特点,它也可能在人工智能生成内容(如生成逼真的视频)方面发挥重要作用。
4. 结论
MaTe3D是一项具有创新意义的人脸编辑技术,它通过掩码和文本编辑的支持,为人脸图像的编辑提供了新的可能性。尽管具体的使用效果和社区反馈需要进一步了解,但可以预见的是,这项技术将在未来的人脸图像处理领域中扮演重要的角色。数字化转型网www.szhzxw.cn
六、VividTalk
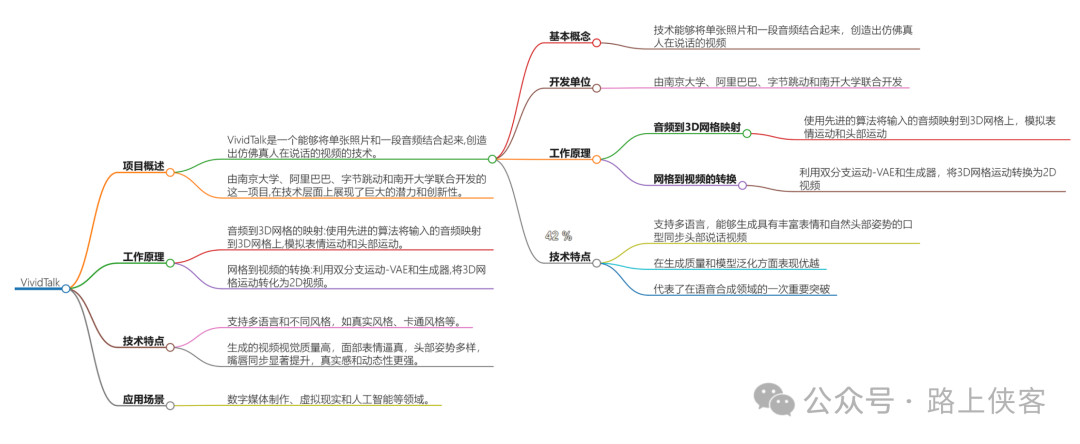
1. VividTalk
VividTalk是一个能够将单张照片和一段音频结合起来,创造出仿佛真人在说话的视频的技术项目。这项技术由南京大学、阿里巴巴、字节跳动和南开大学联合开发,展现了巨大的潜力和创新性。
2. 技术原理
VividTalk的核心功能是使用一张静态照片和音频录音,生成一个动态的、看似真实的讲话视频。这个过程涵盖了多种语言和风格,如真实风格和卡通风格,使其应用范围广泛。VividTalk的工作原理主要分为两个阶段:音频到3D网格的映射(第一阶段)和网格到视频的转换(第二阶段)。在第一阶段中,VividTalk使用先进的算法将输入的音频映射到3D网格上,模拟表情运动和头部运动。在第二阶段中,VividTalk利用双分支运动-VAE和生成器,将3D网格运动转化为2D视频。
3. 应用领域
VividTalk技术不仅有望改变数字媒体的生产方式,也为虚拟现实和人工智能的应用开辟了新的道路。它生成的视频不仅在视觉上质量高,而且在嘴唇同步和面部表情上展现了显著的提升。这意味着视频中的人物不仅看起来真实,而且他们的表情和嘴型与音频完美匹配,为观众提供了一个沉浸式的体验。
4. 开发团队
VividTalk是由南京大学、阿里巴巴、字节跳动和南开大学联合开发的项目。这些机构在技术层面上展现了巨大的潜力和创新性,同时也代表了学术界和工业界合作的巨大潜力。
声明:本文来自网络,版权归作者所有。文章内容仅代表作者独立观点,不代表数字化转型网立场,转载目的在于传递更多信息。如有侵权,请联系我们。数字化转型网www.szhzxw.cn
数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入! 数字化转型网www.szhzxw.cn
本文由数字化转型网(www.szhzxw.cn)转载而成,来源于路上侠客;编辑/翻译:数字化转型网宁檬树。