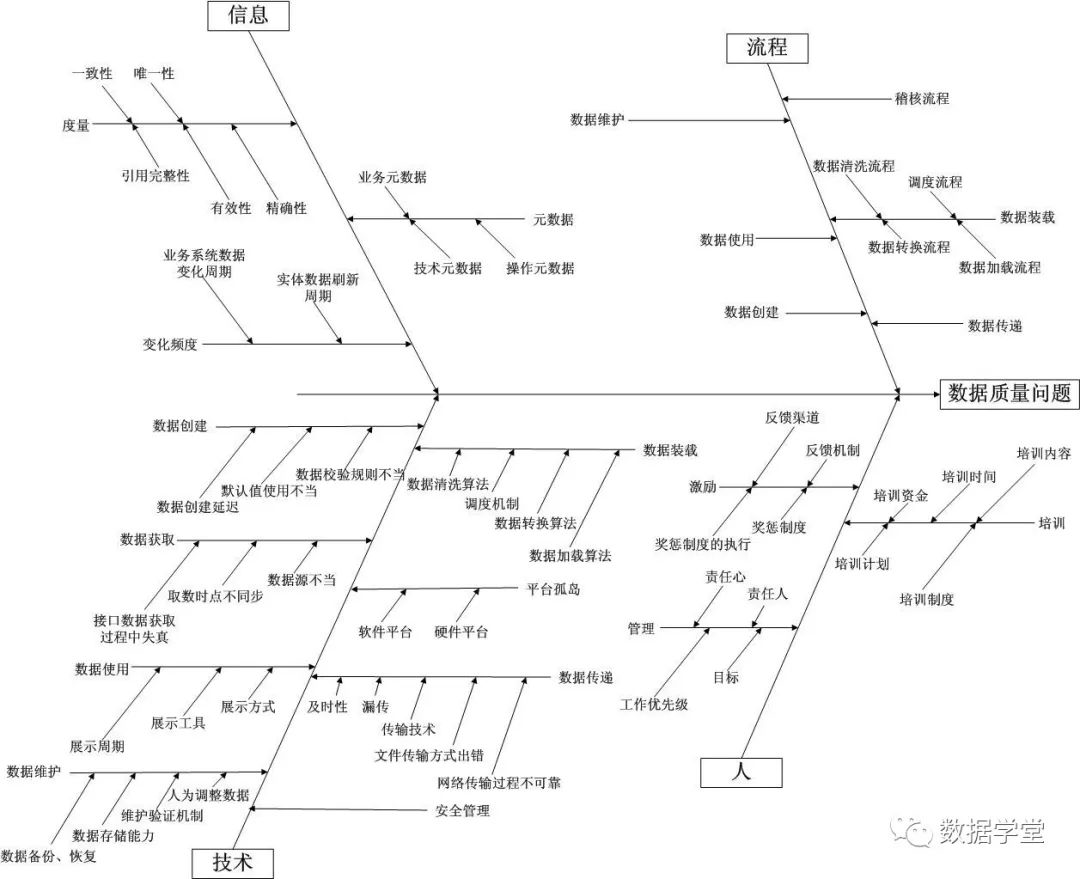
数字化转型网数据专题将关注数据治理、数据质量管理、数据架构、主数据管理、数据仓库、元数据管理、数据备份、数据挖掘、数据分析、数据安全、大数据、数据合规、等数据相关全产业链相关环节。

目前对于高质量的农业病虫害数据集评价指标尚无统一的定义,但是可以肯定的是,构建高质量的数据集对于模型的性能发挥着重要的作用。针对构建农业病虫害图像数据集面临的一些问题和挑战,本文从数据分布一致性、数据集规模和数据标注质量三个方面总结了现有的相关评价方法。
一、数据分布一致性评价
判断训练数据集和测试数据分布是否一致的度量方法常分为度量函数方法和假设检验类方法。假设检验类方法是衡量样本与样本,或者样本与总体之间差异性的一种方法,事先通过对训练和测试数据的分布进行假设,然后利用检验统计量对数据分布进行一致性检验。度量函数的方法因其简单直观,被多数文献采用。度量距离常见的有Hellinger距离、全变差距离和相对熵距离(Kullback-Leibler, KL)等,如公式(1)是用f散度度量函数计算两个分布间的距离
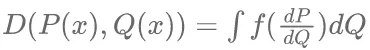
(1)
其中,P(x)和Q(x)分别为两个数据分布的密度函数,当
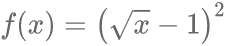
时,该度量函数度量的是Hellinger距离;当
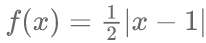
时,该度量函数度量的是全变差距离;当
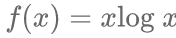
时,该度量函数度量的是KL距离。
当训练数据和测试数据存在误差时,可能导致算法性能下降的问题,因此需要对训练数据和测试数据进行校正。目前常用样本自适应分布差异校正和特征自适应分布差异校正两种方法,前者采用相关机器学习算法对模型测试效果较差的数据进行训练,还有专家利用测试集和训练集中较为重要的数据对损失进行加权对数据分布进行校正。后者经常将测试集和训练集中的数据特征进行转换,但保留数据原有的特征结构,利用新特征来代替旧特征,形成对应关系。
二、数据集规模评价
数据集规模对于模型的训练有着重要作用,模型的准确性和泛化能力与数据集的规模有着高度的相关性。公式(2)直观地表现了几个因素之间的关系。
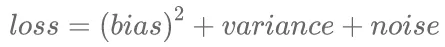
(2)其中,loss表示损失函数;bias表示模型的偏差,是真实标签与预测标签之间的偏离程度,刻画了模型的拟合能力;variance为模型的方差,刻画了模型的稳定性;noise是模型的噪声,表示当前模型所能达到的期望误差下限。
当数据量一定时,模型必须在方差和偏置之间进行权衡,根据经验法则,数据集的容量应当是提取特征数据的十倍。要使模型的泛化能力增强,其预测精度就会下降,反之提升模型的精度,其泛化能力就会下降。在保证标注噪声非常小的前提下,解决这一问题的最好方法就是提升数据集规模。
Sun等选择了分别包含128万张图像、1400万张图像和3亿张图像的不同数据集探究计算机视觉模型的容量和数据集规模之间的关系,实验结果表明,增加数据规模的同时,扩大模型的容量,模型的准确性会得到不断提升,模型的性能表现随着数据规模的增大呈对数关系提升。当数据量一定时,对于深度学习模型而言,选择与模型的深度相匹配的数据集规模很重要。当前根据比较著名的VC维(Vapnik-Chevronenkis Dimension)来评估模型需要的训练数据规模,训练数据的规模与VC维之间存在一个特定的函数关系,如公式(3)所示。
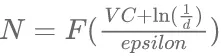
(3)其中,N为与模型匹配的数据集规模;利用函数F(x)对模型进行计算可以得到与之匹配的数据集规模;VC维表示模型的复杂程度,模型复杂度越高,VC维也越大;d是模型的错误率;epslion是模型的误差率。可以看到,利用VC维对数据集规模进行评价的过程中,数据集规模与模型的复杂程度相关。
三、图像标注质量评价
图像标注质量的好坏与特征提取是否全面相关。农业病虫害图像识别算法是根据图像中的像素点进行训练的,因此标注者能否准确地判定像素点关系到整张图像标注的质量优劣,标注的像素越接近于物体的真实边缘,标注的难度越大,标注的质量相应越高,反之标注质量越差。想要保证标注的准确性达到100%,则标注的范围应当与将要识别的真实物体边缘相差不超过1个像素。Gupta等定义了像素精度误差(Pixel-wise Accuracy)ε来计算像素级标注质量,如公式(4)所示。
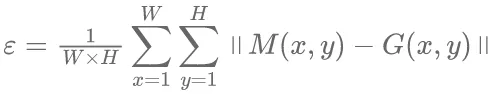
(4)其中,M(x,y)为标注后的区域像素;G(x,y)为图像中真实的目标区域对应的像素;W和H分别为图像的宽度和高度,通过公式(4)计算出M和G的像素精度误差ε。当ε越接近于1,表明标注像素和图像目标实际像素相差越大,标注质量较差;当ε越接近于0,表明标注质量越好。标签的正确性也是图像标注的质量好坏的重要方面,常用的评价指标主要有多数投票算法(Majority Voting,MV)、期望最大值算法(Expectation Maximization,EM)以及RY算法。MV算法的主要策略是选择大多数标注者都认为正确的结果,如公式(5)所示。
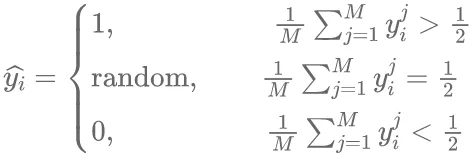
(5)其中,
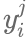
表示标注者对样本图像的预测标签,例如在数据样本中有待标注的图像有m个,每一个图像都对应着一个二元分类,将这些图像样本通过众包分配给M个标注者进行标注,则每个标注者j都会对图像i作出预测,得到
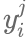
预测值,最终得到该图像的所有标签为

,然后根据这些预测值选择超过一半以上的标注者认为是正确的标签作为最终标签,但是该算法没有考虑到单独标注者的可靠性。事实上,大多数人工作出的选择不一定是正确的,基于此,Raykar等提出了一种使用最大期望值的EM算法,该算法提出在利用标注者标注错误的数据构建错误率混淆矩阵,与实际观测的结果进行比较,当比较后的差异较小时,就说明该标注的质量越高。任何一个标注者对目标对象的标注可以看作是一个二分类问题,即标注正确与标注错误。在二分类问题中常用精准率(Precision)、召回率(Recall)和F 1分数这三种指标来构建混淆矩阵,如表1所示。TP为真实的正样本被预测为正样本数量,FN为真实正样本被预测为负样本数量,FP为真实的负样本被预测正负样本数量,TN为真实的负样本被预测为负样本数量。
表1 二分类混淆矩阵

精准率定义为在所有预测结果的正样本中,真样本数量所占的比重,如公式(6)所示。
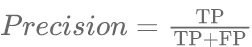
(6)精确率只能反应当预测结果为正样本时的可靠程度。但其存在的问题是。当在结果中仅仅有一个正样本被预测为正样本时,即只有一个标注者将正确的目标对象标注为正确的类别,该模型的精确率为100%。召回率定义为在所有的预测结果中预测正确的正样本数量与所有实际为正样本的数量比例,如公式(7)所示。
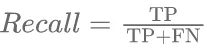
(7)当结果中所有的样本全部被预测为正样本时,即标注者将所有的目标对象都标注为同一个类别时,召回率为100%,因为召回率仅仅关注正样本的情况。F1分数调和了召回率和精准率之间的缺点,综合了两者的结果,如公式(8)所示。
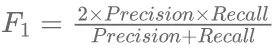
(8)F1分数表示预测的结果中真实的正样本所占的比重和其是否可靠。当召回率和精准率都比较高时,F1分数的结果才会高,当结果越高时,表明标注正确性越高。
Raykar等和于洪等结合了MV和EM算法特点,提出了RY算法,该算法利用公式(2)提出了用于表示标注者本身特征的敏感性(specificity)和特异性(sensitivity)概念,通过对标注者的敏感性和特异性进行分析,排除了不合格标注者标注的图像,从而提高了标注质量。
声明:本文来自智慧农业期刊,版权归作者所有。文章内容仅代表作者独立观点,不代表数字化转型网立场,转载目的在于传递更多信息。如有侵权,请联系我们。数字化转型网www.szhzxw.cn
数字化转型网数据专题包含哪些内容
数字化转型网数据专题将关注数据治理、数据质量管理、数据架构、主数据管理、数据仓库、元数据管理、数据备份、数据挖掘、数据分析、数据安全、大数据、数据合规、等数据相关全产业链相关环节。
数字化转型网数据专题包含: 数字化转型网(www.szhzxw.cn)
1、数据相关外脑支持:100+数据相关专家、100+数据实践者、1000+相关资料
2、数据研习社:与全球数据相关专家、实践者共同探讨相关问题,推动产业发展!
3、国际认证培训:目前已引进DAMA国际认证CDMP,其他国内外认证也在逐步引进中
4、典型案例参考:与数字化转型网数据要素X研习社社员一起学习典型案例,共探企业数据落地应用

本文由数字化转型网(www.szhzxw.cn)转载而成,来源于智慧农业期刊;编辑/翻译:数字化转型网默然。