
凡是过往,皆为序章。这是一个最好的时代,这是一个最坏的时代,这是属于金融科技的时代
一、引言
AI内容生成(AIGC)是Science杂志评选的2022年十大科学突破之一,无论是技术上还是应用上都极具潜力。但是以往的AIGC只在某一领域现象级爆火后又慢慢归于沉寂(如Stable Diffusion绘画生成),其落地应用及产生价值一直是产业界和投资界探寻的方向。直到ChatGPT的出现,AIGC才强化了内容与生产力的连接,从此AIGC不仅仅停留在表达和含义抽象的艺术类产品,也能有对内容的明确反馈和更类似于人类表达习惯的描述,从而把AIGC从玩具进化为产品,迈出了AIGC大规模推广应用的重要一步。
那么,ChatGPT是什么,ChatGPT有哪些应用,又有哪些局限性呢?
二、ChatGPT是什么
ChatGPT是OpenAI公司发布的一款AI对话机器人,一经发布就爆火网络,短短五天内已积累用户一百万,迅速冲上流量高峰。ChatGPT相较以往的对话机器人,能够更好的应对如个性化搜索任务、逻辑解析、写作内容以及辅助编程等自然语言(Nature Language Process,NLP)任务,并能够实现相对准确、完整的多轮次对话。
当然,对于一些开放式问题,如复杂逻辑推理、预测趋势等,ChatGPT往往给出“逻辑正确的空话”,不能完全解决问题。但是瑕不掩瑜,ChatGPT的成功仍然是AI技术的一次重大突破,这意味着AIGC具备实用价值、能够提升生产力,也意味着AI与现实世界的距离又近了一步。
关于ChatGPT的能力,下面两张图也许能够让你看到冰山一角。
那么OpenAI是如何实现这个历史级别的AI产品的呢?
三、ChatGPT的科技与狠活
ChatGPT与它的兄弟模型InstructGPT一样,都是基于GPT3.5大规模预研模型的基础上进化而来。GPT,是一种生成式的预训练模型,由OpenAI团队最早发布于2018年,比近些年NLP领域大热的Bert发布还要早上几个月。在经历了数年的时间,GPT系列模型也有了突飞猛进的发展,历代GPT模型的简要情况见下表:
表1:历代GPT模型情况
| 模型 | 发布时间 | 模型层数 | 词向量长度 | 参数量 | 使用数据量 |
| GPT-1 | 2018.6 | 12 | 768 | 1.17亿 | >5GB |
| GPT-2 | 2019.2 | 48 | 1600 | 15亿 | >40GB |
| GPT-3 | 2020.5 | 96 | 12888 | 1,750亿 | >45TB |
这其中,GPT-1使用无监督预训练与有监督微调相结合的方式,GPT-2与GPT-3则都是纯无监督预训练的方式,GPT-3相比GPT-2的进化主要是数据量、参数量的数量级提升。
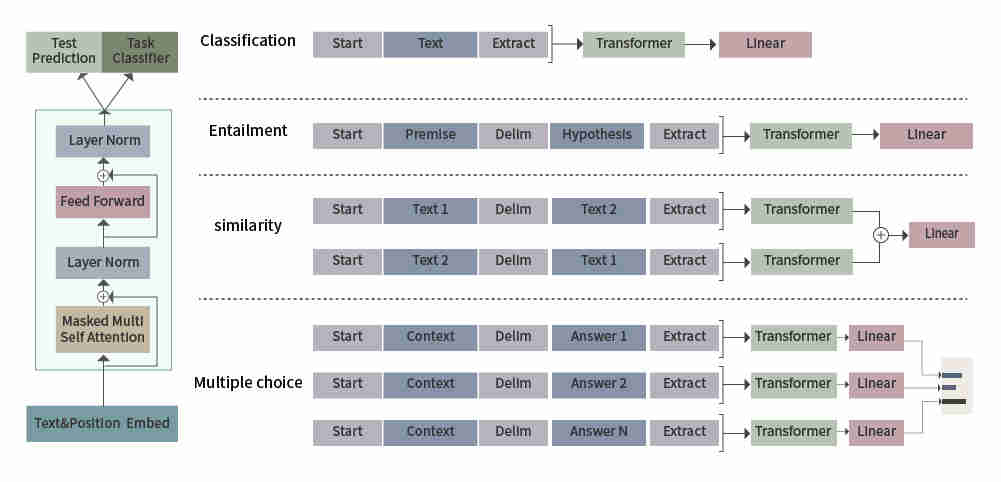
那么,有了GPT-3这样的模型为基础,是如何在其上衍生出ChatGPT的呢?OpenAI并未公布ChatGPT实现的技术细节,从网络公开信息和论文来看,ChatGPT应用带有人工标注反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),使用GPT3.5大规模语言模型作为初始网络结构,使用收集数据增强的InstructGPT进行模型训练,训练过程可以大致分为三个步骤:
1、监督调优预训练模型:在少量标注数据上对预训练模型进行调优,输出SFT(Supervised Fine Tuning,即有监督策略微调)模型。
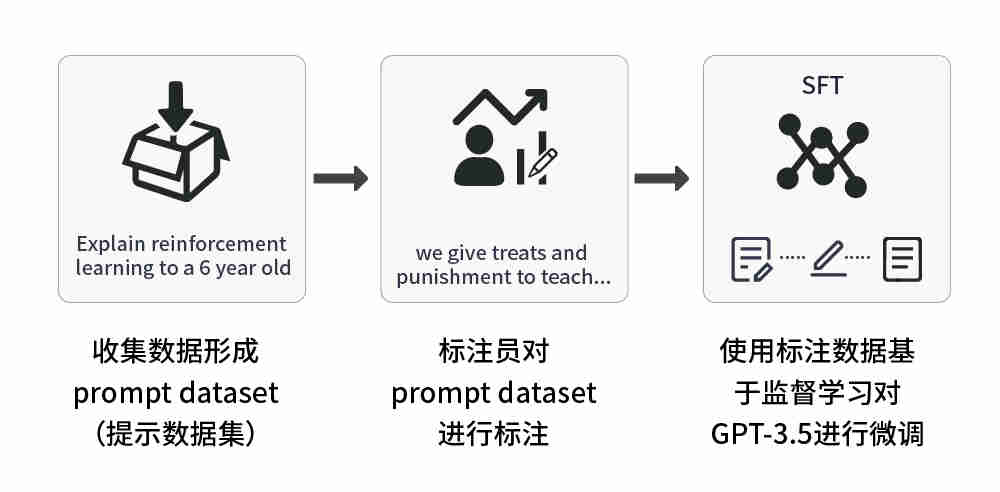
该步骤可细分为三步:
(1)收集数据形成prompt dataset(提示数据集),内含大量的提示文本用于介绍任务内容,即提问题;
(2)有标注员对提示列表进行标注,即回答问题;
(3)使用这个标注过的prompt dataset微调预训练模型。
关于预训练模型的选择,ChatGPT选择了 GPT-3.5 系列中的预训练模型(text-davinci-003),而不是对原始 GPT-3 模型进行调优。
2、训练奖励模型:标注者们对相对大量的 SFT 模型输出进行投票,这就创建了一个由比较数据组成的新数据集。在此数据集上训练的新模型,被称为RM(Reward Model,即奖励模型)模型。
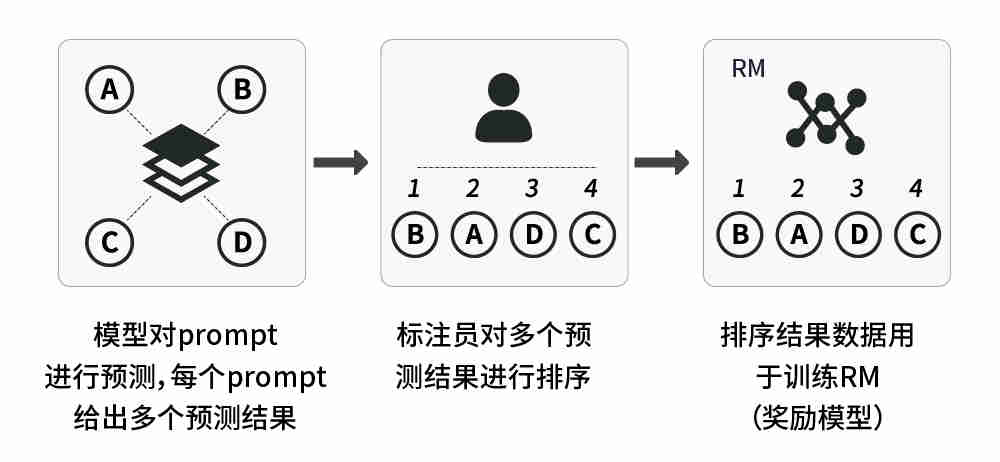
该步骤也可细分为三步:
(1)使用SFT模型预测prompt dataset中的任务,每个prompt任务生成4到9个结果;
(2)标注员对每个prompt的预测结果,按从好到坏顺序进行标注;
(3)用标注结果训练一个RM模型。
3、使用强化学习方法持续优化模型:应用强化学习中的PPO(Proximal Policy Optimization,即近端策略优化)技术,进一步优化奖励模型以实现调优SFT模型。
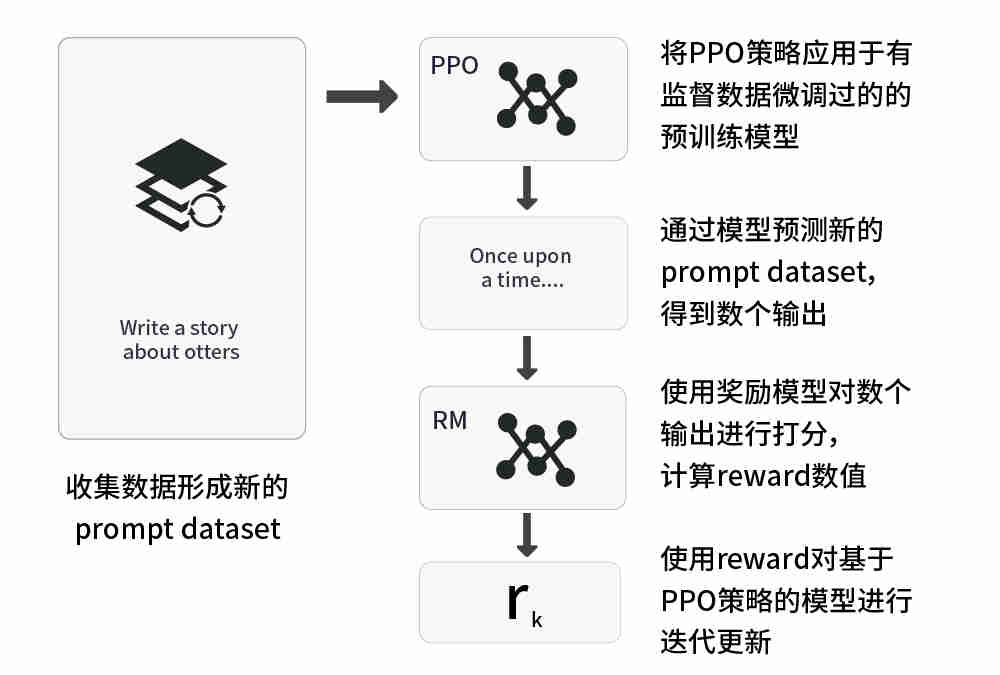
该步骤可细分为五步:
(1)收集数据形成新的prompt dataset;
(2)将PPO策略应用于有监督数据微调过的的预训练模型;
(3)通过模型预测新的prompt dataset,得到数个输出;
(4)使用奖励模型对数个输出进行打分,计算reward(即奖励分值);
(5)使用reward对基于PPO策略的模型进行迭代更新。
以上三个步骤中,步骤一只进行一次,步骤二和步骤三持续重复进行,直至最终形成一个成熟稳定的模型。
ChatGPT模型构建过程值得借鉴的有两点:一是在强化学习中使用奖励模型,训练过程更稳定且更快收敛,在传统NLP任务中,在对话模型的设计一直是个难点。引入了强化学习后,虽然可以解决对话问题,但如何建模奖励机制又成为了设计难题。ChatGPT采用训练奖励模型并不断迭代的方案,训练以一个提示词和多个响应值作为输入,并输出奖励模型,实现了训练的收敛。二是使用SFT策略微调模型,有效利用大模型能力,同时避免过拟合,GPT-3用对应的SFT数据集训练16次完整数据集,每一次都是一个输入对应一个输出,对比奖励模型,给与奖励或者惩罚;但是这样训练的过拟合程度较高,甚至在第一次完整数据集训练后已经存在过拟合现象。ChatGPT在GPT-3基础上进行了优化,每个输入对应多个输出,人工进行输出结果排序,这样就能够让训练过程更接近人类思维模式,也有效避免了过拟合。
四、ChatGPT的局限性分析
当然,就像前文提到的,ChatGPT也并非完美,其仍有一定的优化空间,从技术角度尝试进行初步分析:
1、不可信性
对于AI对话生成模型而言,可解释性很重要,尤其是在推理、反馈等场合更需要严谨可追溯的解答,但是ChatGPT并没有针对问题来源做解释说明,这会导致其答案在部分场景中不可信,在部分领域的应用中受限。
2、诱导立场
可能是由于提示学习的原因,ChatGPT 在对话中对提问词的内容比较敏感,容易被提示词诱导,若初始提示或问题存在歧义或者伦理、道德层面的瑕疵,则模型会按照当前理解给出答案而不是反馈和纠正问题,这可能会导致ChatGPT强大的能力被用于一些非法、违规的场景,带来不必要的损失。
3、信息误判
ChatGPT的热启动虽然在大部分内容生成中能够给出大体上完整的答案,但是一部分回答会存在事实性错误,同时为了使得答案看起来更完整,ChatGPT会根据提示词生成冗余的内容用以修饰。在辅助决策的场景中,这种错误回答被淹没在大量冗余修饰之中,更不容易被察觉,这导致的信息误判也限制了ChatGPT应用于类似场景。
4、迭代成本
ChatGPT虽然具备内容生成能力,但是由于其本身基于大模型+人工标注训练的模式,对于新的信息采纳需要对大模型进行重新训练,这导致模型迭代训练成本过高,也间接导致ChatGPT对于新知识的学习更新存在一定时间区间的断档,这尤其限制了其在实时搜索领域的进一步发展。
五、ChatGPT带来的启示
ChatGPT引起的轰动是由于人们惊讶于它远超出前辈的泛用性和大幅度提升的回答问题能力,但这背后的影响其实远远不止这些:
1. 有可能带来NLP研究范式的变革
ChatGPT迅速走红的背后,可以说是GPT类的自回归类语言模型的一次翻身仗。NLP领域近些年来另一热门的模型当属Bert。Bert与GPT都是基于Transformer思想产生的大型预训练模型,但二者之间存在不少差异,简单的说,Bert是双向语言模型,其更多应用于自然语言理解任务,而GPT则是自回归语言模型(即从左到右单向语言模型),其更多应用于自然语言生成任务。
ChatGPT所表现出的强大能力有理由让人相信,自回归语言模型一样能达到甚至赶超双向语言模型的路线,甚至在未来统一理解、生成两类任务的技术路线也未可知。
2. LLM(Large Language Model,大型语言模型)交互接口的革新
如果归纳下ChatGPT最突出特点的话,可以概括为:“能力强大,善解人意”。“能力强大”归功于其依托的GPT3.5,巨量语料、算力的结晶使模型蕴含的知识几乎覆盖了各个领域。而“善解人意”则有可能要归功于其训练过程中加入的人工标注数据。这些人工标注数据向GPT3.5注入了“人类偏好”知识,从而能够理解人的命令,这是它“善解人意”的关键。
ChatGPT的最大贡献在于:几乎实现了理想的LLM交互接口,让LLM适配人的习惯命令表达方式,而不是反过来让人去适配LLM,这大大提升了LLM的易用性和用户体验。而这必将启发后续的LLM模型,继续在易用人机接口方面做进一步的工作,让LLM更听话。
3. LLM技术体系将囊括NLP外更多领域
理想的LLM模型所能完成的任务,不应局限于NLP领域,而应该是领域无关的通用人工智能模型,它现在在某一两个领域做得好,不代表只能做这些任务。ChatGPT的出现,证明了AGI(Artificial General Intelligence,通用人工智能)是有可行性的。
ChatGPT除了展示出以流畅的对话形式解决各种NLP任务外,也具备强大的代码能力,可以预见,之后越来越多其它的研究领域,也会被逐步纳入LLM体系中,成为通用人工智能的一部分。这个方向方兴未艾,未来可期。
六、ChatGPT的应用展望
ChatGPT使用了当下先进的AI框架,相较于其他产品具备较高的成熟度,是AI技术发展浪潮中产生的优秀产品。但是正如前文分析,ChatGPT也有其自身的局限性。农业银行基于大数据体系、AI平台所提供的数据+AI能力,结合ChatGPT的相关技术,同时设法规避ChatGPT的固有问题,逐步赋能场景,有着巨大的想象空间。
营销自动化,综合使用AIGC技术,结合现有的个性化推荐、实时计算能力以及AutoML等技术,可以解决线上线下协同营销过程中的自动化断点问题,实现营销策略自动生成和迭代、自动AB实验、渠道自动分流,并实现自动生成营销话术、广告头图等运营内容,从而实现完整的自动化营销闭环。
风险识别,基于ChatGPT背后的GPT等LLM模型技术,可实现对关键要素提取、资料自动化审核、风险点提示等风控领域的业务流程,提升风控相关业务的自动化水平。
个性化搜索引擎,以GPT生成式问答为主体,结合现有的NLP、搜索引擎、知识图谱和个性化推荐等AI能力,综合考虑用户的提示词标注、知识结构、用户习惯等进行应对用户对应问题的内容生成和展示,并可以给出索引URL,这样既能解决现有检索引擎的准确性、个性化难题,又能弥补GPT的可信、更新问题,在技术上形成互补,在用户使用过程中实现完整的、一致的搜索体验。
增强知识图谱,使用GPT生成技术,结合知识图谱技术,可从当前实体关系图中生成扩展图,在知识图谱引擎原有的隐性集团识别、深度链扩散、子图筛选等能力基础上,扩展出更高维度、更大范围的隐性关系识别,能够提升风险识别、反欺诈的识别范围和准确程度。
内容创作,ChatGPT技术,结合行内语料进行适应性训练,可面向资讯、产品、广告提供便捷且高质量的内容生成能力,既能提升内容运营的效率,又能帮助用户更快地获取、理解和分析复杂的信息,从而进一步提升用户运营转化率。
辅助编程,相对于Copilot珠玉在前,ChatGPT类似技术的迭代反馈能力更为强大,能够通过提示、辅助、补充等方式生成部分代码,能够在简单逻辑代码实施中有效减少重复劳动,在复杂架构设计中铺垫微创新的基础。如应用得当,应会提升开发效率和交付质量。
智能客服,AI生成的对话可以快速应用于问题解答、营销话术等,能够提升问题解答的准确程度、给出相对靠谱的回答,并能结合个性化推荐系统的应用给出用户的营销线索,实现更标准、更贴心的用户服务。
ChatGPT乘风而来,农业银行在探索AI新技术、追逐AI新应用的脚步也从未停歇。就在近期,农行正在探索基于生成式大模型,结合金融领域相关文本语料,通过AI平台-NLP智能服务引擎提供特定业务场景下的文本生成、文本理解服务,近期该服务的alpha版本也即将在AI平台的AI商店上线,面向种子用户开放试用。
下一步,NLP智能服务引擎计划收集更多的银行业内相关的语料数据,基于大模型不断迭代优化出更具专业特色、更符合场景需求的自然语言理解与自然语言生成模型,让更多人乘上这辆急速前进、不断进化的AI快车。
七、结语
随着AI技术的深入发展和应用,定会不断诞生类似于ChatGPT的爆款产品,这类产品成功的逻辑是伴随人工智能技术的发展和创新,绑定具体场景应用,以满足用户的认知和期待。农业银行遵循这一规律,在AI技术创新、AI应用创新方面不断探索,以用带建,螺旋上升,在数字化转型的浪潮中,以数据为基础要素,以AI为重要抓手,逐步赋能总分行场景应用,让大家了解AI,用上AI,用好AI,充分挖掘数据和AI的价值,让数据和AI在银行业务经营管理活动中起到更加基础和重要的作用。
翻译:
The past is a prologue. It’s the best of times, it’s the worst of times, it’s the age of fintech
Introduction
AI content generation (AIGC) is one of the top 10 scientific breakthroughs of 2022 selected by Science magazine, which holds great potential both in terms of technology and application. But in the past, AIGC only became a phenomenon in a certain field and then slowly fell silent (such as Stable Diffusion painting generation), and its application and value have been the direction of the industry and investment circles to explore. It was not until the appearance of ChatGPT that AIGC strengthened the connection between content and productivity. Since then, AIGC was not only an artistic product with abstract expression and meaning, but also a clear feedback on the content and a description more similar to human expression habits. Thus, AIGC evolved from a toy to a product, and took an important step for the large-scale promotion and application of AIGC.
So, what is ChatGPT, what are its applications, and what are its limitations?
What is a ChatGPT
ChatGPT, an AI conversation bot released by OpenAI, took the Internet by storm, accumulating more than 1 million users in just five days and quickly skyrocketing to the peak of traffic. Compared with previous conversational robots, ChatGPT can better cope with Nature Language Process (NLP) tasks such as personalized search tasks, logical analysis, content writing, and assisted programming, and can achieve relatively accurate and complete multi-turn conversation.
Of course, for some open-ended problems, such as complex logical reasoning and trend prediction, ChatGPT often gives “logically correct empty words”, which cannot completely solve the problem. But ChatGPT’s success is still a breakthrough in AI technology. It means that AIGC has practical value and can improve productivity, and it means that AI is one step closer to the real world.
In terms of ChatGPT’s capabilities, the following two charts may give you a glimpse of the iceberg.
So how did OpenAI achieve this historic level of AI product?
ChatGPT’s technology and ruthlessness
ChatGPT, like its sibling InstructGPT, is based on the large-scale prestudy model GPT3.5. GPT, a generative pre-training model, was first released by the OpenAI team in 2018, a few months before the release of Bert, one of the most popular NLP models of recent years. After several years, GPT series models have also developed by leaps and bounds. See the following table for a brief overview of GPT models in successive dynasties:
Among them, GPT-1 uses a combination of unsupervised pre-training and supervised fine-tuning, while GPT-2 and GPT-3 are both pure unsupervised pre-training. Compared with GPT-2, the evolution of GPT-3 is mainly an order of magnitude increase in the amount of data and parameters.
So, with GPT-3 as the basis, how can ChatGPT be derived from it? The technical details of ChatGPT implementation have not been released by OpenAI. from the information available online and the papers, Reinforcement Learning from Human Feedback (RLHF) has been applied in ChatGPT. The GPT3.5 large-scale language model was used as the initial network structure, and InstructGPT enhanced with data collection was used for model training. The training process can be roughly divided into three steps:
Supervised Tuning pre-training model:
Supervised Fine tuning model based on a small amount of labeled data, output SFT (Supervised Fine Tuning) model.
This step can be subdivided into three steps:
(1) Collect data to form prompt dataset (prompt dataset), which contains a large number of prompt texts for introducing task contents, that is, asking questions;
(2) Annotators annotate the prompt list, that is, answer questions;
(3) Use this annotated prompt dataset to fine-tune the pre-training model.
Regarding the choice of pre-training model, ChatGPT chose the pre-training model in the GPT-3.5 series (text-Davinc-003) instead of tuning the original GPT-3 model.
Training Reward Model:
Callers vote on a relatively large number of SFT model outputs, which creates a new data set composed of comparative data. The new Model trained on this dataset is called the RM (Reward Model) model.
This step can also be subdivided into three steps:
(1) Using the SFT model to predict tasks in the prompt dataset, each prompt task generated 4 to 9 results;
(2) The annotator marked the predicted results of each prompt in order from good to bad;
(3) Train an RM model with the annotation results.
Use reinforcement learning methods to continuously optimize the model:
Use PPO (Proximal Policy Optimization) techniques in reinforcement learning to further optimize the reward model to optimize the SFT model.
This step can be subdivided into five steps:
(1) Collect data to form new prompt dataset;
(2) Apply PPO strategy to the pre-training model fine-tuned with supervised data;
(3) Several outputs were obtained by predicting new prompt dataset through the model;
(4) Use the reward model to score the number of outputs and calculate the reward (i.e., the reward score value);
(5) Use reward to update the model based on PPO strategy iteratively.
Of the above three steps, step 1 is carried out once, step 2 and Step 3 are repeated continuously until a mature and stable model is finally formed.
ChatGPT model construction process is worth learning from two points: First, the use of reward model in reinforcement learning, the training process is more stable and faster convergence, in the traditional NLP task, the design of dialogue model has been difficult. After the introduction of reinforcement learning, the dialogue problem can be solved, but how to model the reward mechanism becomes a design challenge. ChatGPT adopts the training reward model and iterates constantly. The training takes a prompt word and multiple response values as input, and outputs the reward model, achieving the convergence of training.
The second is to use SFT strategy to fine-tune the model, effectively utilize the capacity of the large model, and avoid overfitting. GPT-3 trains the complete data set 16 times with the corresponding SFT data set, each time one input corresponds to one output, and compares the reward model to give a reward or punishment; However, such training has a high degree of overfitting, even after the first complete data set training. ChatGPT is optimized based on GPT-3 so that each input corresponds to multiple outputs and the outputs are sorted manually, which makes the training process more similar to the human mindset and effectively avoids overfitting.
Limitation analysis of ChatGPT
Of course, as mentioned above, ChatGPT is not perfect and there is still some room for improvement. Try a preliminary analysis from a technical point of view:
Untrustworthiness
For the AI dialogue generation model, interpretibility is very important, especially in reasoning, feedback and other occasions, where rigorous traceable answers are needed. However, ChatGPT does not explain the source of the question, which makes its answers untrustworthy in some scenarios and limited in some applications.
Inducing position
Possibly due to prompt learning, ChatGPT is sensitive to the content of question words in the dialogue and is easily induced by prompt words. If there is ambiguity or ethical or moral defects in the initial prompt or question, the model will give answers according to the current understanding instead of giving feedback and correcting the problem. This could lead to ChatGPT’s powerful capabilities being used in illegal and illegal scenarios, causing unnecessary losses.
Misjudgment of information
Although ChatGPT’s hot start can give a generally complete answer in most content generation, some answers may have factual errors. Meanwhile, in order to make the answer appear more complete, ChatGPT generates redundant content based on the prompt words. In decision aid scenarios, this false answer is buried in a lot of redundant embellishments and is less likely to be detected, which leads to misinformation and limits the application of ChatGPT in similar scenarios.
Iteration cost
Although ChatGPT has the ability of content generation, it is based on the model of large model + manual labeling training, so it needs to retrain the large model to adopt new information, which leads to the high cost of model iterative training, and indirectly leads to the time interval of ChatGPT’s learning and updating of new knowledge. This particularly limits its further development in the field of real-time search.
Inspiration from ChatGPT
ChatGPT caused a stir because people were surprised that it was so much more general than its predecessor and so much better at answering questions, but there was more to it than that:
It may bring about the change of NLP research paradigm
Behind ChatGPT’s rapid popularity, it can be said that the autoregressive language model of the GPT class is a turnaround. Another popular model in NLP field in recent years is Bert. Bert and GPT are both large pre-training models based on the idea of Transformer, but there are many differences between them. To put it simply, Bert is a two-way language model, which is more applicable to natural language understanding tasks, while GPT is an autoregressive language model (i.e. a one-way language model from left to right). It is more used for natural language generation tasks.
ChatGPT’s powerful capability makes it reasonable to believe that the autoregressive language model can also match or surpass the path of the two-way language model, and even the technical path of unified understanding and generation of the two types of tasks in the future is unknown.
Innovation of interactive interface of LLM (Large Language Model)
If you can summarize ChatGPT’s most distinctive features, they are: “powerful and empathetic”. “Powerful” is attributed to its reliance on GPT3.5. The huge corpus and the crystallization of computing power make the knowledge contained in the model cover almost every field. “Empathetic” is likely due to the manual data that was added to the training. This manually labelled data imbues GPT3.5 with knowledge of “human preferences” to be able to understand human commands, which is key to its “empathetic” nature.
The biggest contribution of ChatGPT is that it almost implements an ideal LLM interaction interface, enabling LLM to adapt to customary command expression rather than the other way around, which greatly improves the usability and user experience of LLM. And this will certainly inspire subsequent LLM models, continue to do further work in easy-to-use human-machine interface, and make LLM more obedient.
LLM technology system will cover more fields besides NLP
The tasks that an ideal LLM model can complete should not be limited to the field of NLP, but should be domain-independent general artificial intelligence model. It is doing well in one or two fields, but it does not mean that it can only do these tasks. The appearance of ChatGPT proves that AGI (Artificial General Intelligence) is feasible.
ChatGPT not only shows that it can solve various NLP tasks in the form of smooth conversation, but also has strong coding capabilities. It can be predicted that more and more other research fields will be gradually included in the LLM system and become a part of general artificial intelligence. This direction is in the ascendant and has a promising future.
The application prospect of ChatGPT
ChatGPT uses the current advanced AI framework and has higher maturity compared with other products. It is an excellent product in the wave of AI technology development. But ChatGPT has its limitations, as discussed earlier. Based on the data +AI capabilities provided by the big data system and AI platform, combined with the relevant technologies of ChatGPT, Agricultural Bank of China managed to avoid the inherent problems of ChatGPT and gradually enabled the scene, which has a huge space for imagination.
Marketing automation, with the comprehensive use of AIGC technology, combined with the existing personalized recommendation, real-time computing power and AutoML technology, can solve the automation breakpoints in the process of online and offline collaborative marketing, realize automatic generation and iteration of marketing strategies, automatic AB experiments, automatic distribution of channels, and realize automatic generation of marketing words, advertising header graphics and other operation content. So as to achieve a complete automated marketing closed loop.
Risk identification, based on the GPT and other LLM model technologies behind ChatGPT, can realize the business processes in the field of risk control, such as key factors extraction, data automatic review, risk point prompt, and improve the automation level of risk control related businesses.
Personalized search engine takes GPT generated question and answer as the main body, combines the existing AI capabilities
Personalized search engine takes GPT generated question and answer as the main body, combines the existing AI capabilities such as NLP, search engine, knowledge graph and personalized recommendation, and comprehensively takes user’s prompt word annotation, knowledge structure and user habits into consideration to generate and display content in response to user’s corresponding problems, and can provide index URL. This can not only solve the accuracy and personalization problems of the existing search engines, but also make up for the credibility and update problems of GPT, form a complementary technology, and achieve a complete and consistent search experience in the process of user use.
Enhanced knowledge graph, GPT generation technology, combined with knowledge graph technology, can be generated from the current entity relationship graph extended graph, on the basis of knowledge graph engine’s original hidden group identification, deep chain diffusion, subgraph screening and other capabilities, to expand a higher dimension, wider range of hidden relationship identification, can improve the risk identification, anti-fraud identification range and accuracy.
Content creation, ChatGPT technology and adaptive training combined with in-line corpus can provide convenient and high-quality content generation capabilities for information, products and advertisements, which can not only improve the efficiency of content operation, but also help users to acquire, understand and analyze complex information faster, thus further improving the conversion rate of user operation.
Compared with Copilot, ChatGPT’s similar technology has stronger iterative feedback ability.
It can generate part of the code by means of prompt, assist and supplement, which can effectively reduce repetitive labor in the implementation of simple logic code and pave a new minimally invasive foundation in the design of complex architecture. If applied properly, this should improve development efficiency and delivery quality.
Intelligent customer service, AI-generated dialogue can be quickly applied to question answering, marketing skills, etc., can improve the accuracy of question answering, give relatively reliable answers, and combined with the application of personalized recommendation system to give users marketing clues, to achieve more standard, more intimate user service.
With ChatGPT, Agricultural Bank of China has never stopped exploring new AI technologies and pursuing new AI applications. Recently, Agricultural Bank of China is exploring text generation and text understanding services in specific business scenarios based on generative large model and in combination with text corpus related to the financial field through AI platforming -NLP intelligent service engine. Recently, the alpha version of this service will also be launched in AI store of AI platform and open to trial for seed users.
In the next step, NLP intelligent service engine plans to collect more corpora data related to the banking industry, constantly iterate and optimize natural language understanding and natural language generation models with more professional characteristics and more in line with scene requirements based on large models, so that more people can get on this fast moving and constantly evolving AI express train.
Conclusion
With the further development and application of AI technology, popular products similar to ChatGPT will be born continuously. The logic of success of such products is to accompany the development and innovation of artificial intelligence technology and bind to specific scenarios to meet users’ cognition and expectations. Agricultural Bank of China follows this rule and constantly explores AI technology innovation and AI application innovation, and builds with application and spirals. In the tide of digital transformation, it takes data as the basic element and AI as an important starting point to gradually enable the scene application of the head office branch, so that everyone can understand AI, use AI and make good use of AI, and fully tap the value of data and AI. Let data and AI play a more fundamental and important role in banking operations and management activities.
本文由数字化转型网(www.szhzxw.cn)转载而成,来源:我们的开心;编辑/翻译:数字化转型网宁檬树。

免责声明: 本网站(http://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。


