
9月1日,阶跃星辰正式发布最强开源端到端语音大模型Step-Audio2mini。该模型在多个国际基准测试集上取得了SOTA(State-of-the-Art)成绩,将语音理解、音频推理与生成统一建模,在音频理解、语音识别、跨语种翻译、情感与副语言解析、语音对话等任务中表现突出,并率先支持语音原生的Tool Calling能力,可实现联网搜索等操作。Step-Audio2mini被形容为“听得清楚、想得明白、说得自然”,其模型现已上线GitHub、Hugging Face等平台,供用户下载、试用并反馈。
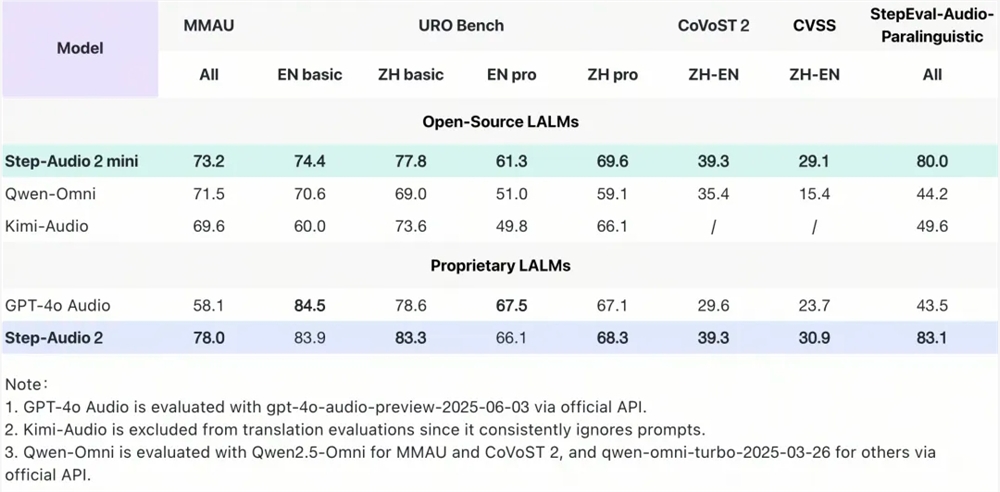
Step-Audio2mini在多个关键基准测试中取得SOTA成绩,在音频理解、语音识别、翻译和对话场景中表现卓越,综合性能超越Qwen-Omni、Kimi-Audio等所有开源端到端语音模型,并在大部分任务上超越GPT-4o Audio。在通用多模态音频理解测试集MMAU上,Step-Audio2mini以73.2的得分位列开源端到端语音模型榜首;在衡量口语对话能力的URO Bench上,Step-Audio2mini在基础与专业赛道均拿下开源端到端语音模型最高分;在中英互译任务上,Step-Audio2mini在CoVoST2和CVSS评测集上分别取得39.3和29.1的分数,大幅领先GPT-4o Audio和其他开源语音模型;在语音识别任务上,Step-Audio2mini取得多语言和多方言第一,其中开源中文测试集平均CER(字错误率)3.19,开源英语测试集平均WER(词错误率)3.50,领先其他开源模型15%以上。
Step-Audio2mini通过创新架构设计,有效解决了此前语音模型存在的问题,做到“走脑又走心”。它采用真端到端多模态架构,突破传统ASR+LLM+TTS三级结构,实现原始音频输入到语音响应输出的直接转换,架构更简洁、时延更低,并能有效理解副语言信息与非人声信号。此外,Step-Audio2mini在端到端语音模型中首次引入链式思维推理(CoT)与强化学习联合优化,能对情绪、语调、音乐等副语言和非语音信号进行精细理解、推理并自然回应。模型还支持包括web检索等外部工具,有助于解决幻觉问题,并赋予模型在多场景扩展上的能力。
Step-Audio2mini的能力在案例中得到了生动展示。它能精准识别大自然的声音、精湛的配音,还能实时搜索获得行业最新资讯。此外,Step-Audio2mini还能控制语速,轻松应对不同场景的对话需求。当被问及哲学难题时,Step-Audio2mini能将抽象问题转化为极简方法论,展现强大的逻辑推理能力。
声明:本文来自AI新闻资讯,版权归作者所有。文章内容仅代表作者独立观点,不代表数字化转型网立场,转载目的在于传递更多信息。如有侵权,请联系我们。数字化转型网www.szhzxw.cn

本文由数字化转型网(www.szhzxw.cn)转载而成,来源于AI新闻资讯;编辑/翻译:数字化转型网(Professionalism Achieves Leadership 专业造就领导者)萍水

