
NVIDIA 开源了 Live VLM WebUI,一个让你在本地用摄像头实时测试视觉语言模型的工具。一句话说明白:把摄像头画面直接喂给 AI,实时看分析结果。数字化转型网www.szhzxw.cn
核心功能
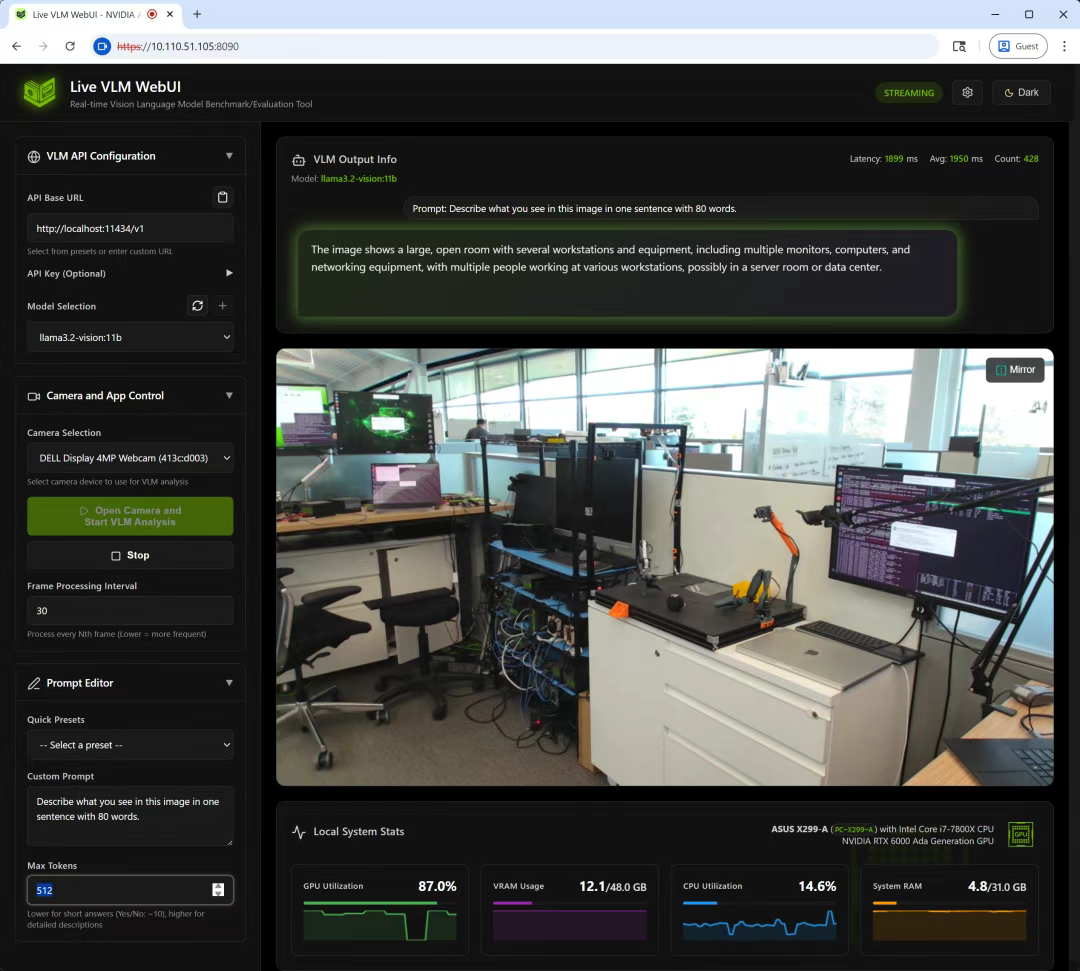
通过 WebRTC 技术将摄像头视频流实时传输给支持视觉的 Ollama 模型,AI 分析结果直接叠加在视频画面上。不是截图上传那种,是真正的视频流处理。
这个工具其实是 NVIDIA Jetson 团队之前工作的演进版本。最初他们在 Jetson 上做过 WebRTC 集成的实时摄像头流处理,但当时和特定硬件绑定太紧。数字化转型网www.szhzxw.cn
Ollama 出现后,标准化的 API 让这种实时流处理可以在任何平台上工作。所以他们把之前的经验现代化了:支持任何 VLM 后端,运行在任何平台,体验比在 Open WebUI 上传图片等响应要好得多。
技术细节:
- WebRTC 低延迟视频传输
- 实时显示处理帧率、GPU 使用率、VRAM 占用
- 支持 Ollama、vLLM、NVIDIA API Catalog、OpenAI 等多种后端
- 跨平台:Windows(WSL)、macOS、Linux、Jetson
https://wxa.wxs.qq.com/tmpl/ok/base_tmpl.html
支持的模型包括:
- Gemma 系列:
gemma3:4b、gemma3:12b - Llama Vision:
llama3.2-vision:11b、llama3.2-vision:90b - Qwen VL:从
qwen2.5-vl:3b到qwen3-vl:235b - LLaVA:
llava:7b、llava:13b、llava:34b - MiniCPM-V:
minicpm-v:8b
实际应用场景
NVIDIA 工程师分享了几个有用的场景:
模型对比测试:同一个场景下比较 gemma:4b vs gemma:12b vs llama3.2-vision 的表现差异
性能基准测试:直接看到你硬件上的实际推理速度,不用猜
实时提示工程:调整视觉提示词的同时看到实时效果,反馈循环很快
交互演示:给别人展示视觉模型能力时,比上传静态图片有说服力
安装和使用
最简单的方式:
pip install live-vlm-webui
live-vlm-webuihttps://wxa.wxs.qq.com/tmpl/ok/base_tmpl.html
然后打开 https://localhost:8090,选择后端和模型就能用。
除了 pip 安装,还支持 Docker:
docker run -d --gpus all --network host \
ghcr.io/nvidia-ai-iot/live-vlm-webui:latest对 Jetson 用户有专门的镜像标签:latest-jetson-orin 和 latest-jetson-thor。
Docker Compose 可以一键部署(VLM + WebUI):
./scripts/start_docker_compose.sh ollama
docker exec ollama ollama pull llama3.2-vision:11b硬件需求
网友测试发现,7B 参数的模型在普通笔记本上就能接近实时分析。不需要昂贵的云计算资源,本地跑就行。数字化转型网www.szhzxw.cn
界面显示详细的系统监控:GPU 利用率、VRAM 使用、CPU 和内存状态,还有推理延迟、tokens/sec 等指标。
小结
相较于传统静态图片测试,这种通过摄像头实时测试更加具有实际意义,能够更充分体现各个模型的优劣。后续,开发团队还会进一步优化对比体验,项目完全开源,感兴趣的可以使用。
若您对人工智能感兴趣,可添加数字化转型网小助手思思微信加入人工智能交流群。若您在寻找人工智能供应商,可联系数字化转型网小助手思思(17757154048,微信同号)

若您为人工智能服务商,可添加数字化转型网小助手Nora,加入人工智能行业交流群。

若您为人工智能创业者,可添加数字化转型网社群主理人Carina,加入人工智能创业交流群。

声明:本文来自网络,版权归作者所有。文章内容仅代表作者独立观点,不代表数字化转型网立场,转载目的在于传递更多信息。如有侵权,请联系我们。数字化转型网www.szhzxw.cn

本文由数字化转型网(www.szhzxw.cn)转载而成,来源于网络;编辑/翻译:数字化转型网(Professionalism Achieves Leadership 专业造就领导者)默然


