
数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!

嵌入(Embedding)是机器学习中的一个基本概念,尤其是在自然语言处理 (NLP) 领域,但它们也广泛应用于其他领域。通常,嵌入是一种将离散的分类数据转换为连续向量的方法,通常在高维空间中,将复杂、难以处理的项目(如单词、图像或用户 ID)转换为机器学习模型可以理解和更有效地处理的形式。
一、什么是向量
在数学中,向量(也称为欧几里得向量、几何向量、矢量),指具有大小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。 数字化转型网(www.szhzxw.cn)
箭头所指,代表向量的方向。线段长度,代表向量的大小。与向量对应的量叫做数量(物理学中称标量),数量(或标量)只有大小,没有方向。
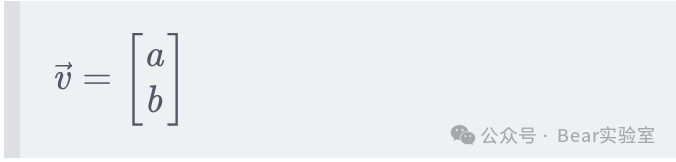
通常我们在坐标系中用一个有长度、带箭头的线段表示一个向量。一般来讲,在笛卡尔坐标(平面坐标系)中我们喜欢将向量的起点放在原点,终点就是坐标系中的某个点,然后我们从原点往那个点画一根带有箭头的线段。
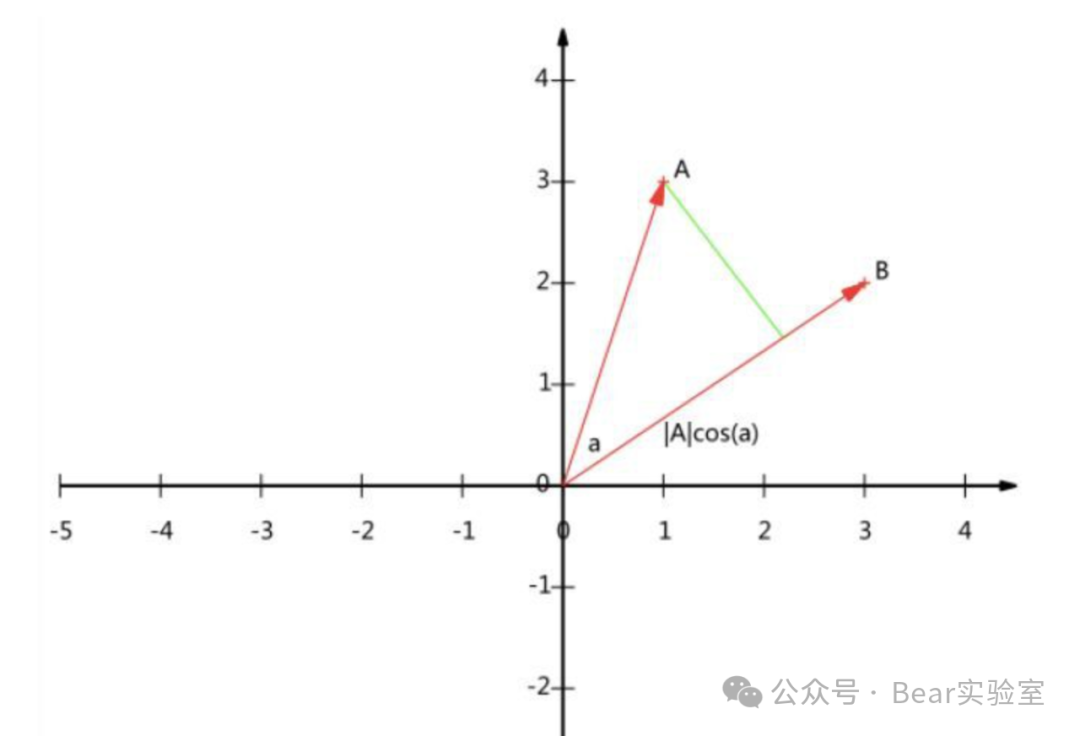
既然是两段从坐标原点出发的有长度、带箭头的线段,那么我们就可以计算两个向量的夹角。当然通常的计算机中的向量是多维的,比如OpenAI Embeddings就是1536维,但是逻辑是一致的。
向量夹角跟嵌入和搜索有什么关系?下面借用吴军老师在数学通识的讲解,通俗易懂。非常佩服吴军老师,即使我作为当年数学专业科班出身,听他的课还是收获满满,换个角度理解,可以让学识更丰满更立体。 数字化转型网(www.szhzxw.cn)
算出两个向量的夹角有什么用?它其实有很多的应用,比如可以对文本进行自动分类。这两件事情看似不相干,怎么会联系到一起呢?下面我们就大致介绍一下计算机进行文本自动分类的原理。
我们知道一篇文章的主题和内容,其实是由它所使用的文字决定的,不同的文章使用的文字不同,但是主题相似的文章使用的文字有很大的相似性。
比如讲金融的文章里面可能会经常出现“金融”、“股票”、“交易”、“经济”等词,讲计算机的则会经常出现“软件”、“互联网”、“半导体”等词。假如这两部分关键词没有重复,那么我们很容易把这两类文本分开。
假如它们有重复怎么办?那么我们就要看这两类文章中,各个词的频率了。根据我们的经验,即使在金融类的文章中混有一些计算机类的词,那么它们的词频不会太高,反之亦然。
为方便说明如何区分这两类文章,我们就假设汉语中只有“金融”、“股票”、“交易”、“经济”、“计算机”、“软件”、“互联网”和“半导体”这八个词。假设有一篇经济学的文章,这八个词出现的次数分别是(23,32,14,10,1,0,3,2),另一篇是计算机的文章,这八个词出现的次数是(3,2,4,0,41,30,31,12),这样它们就各自形成一个八维的向量,我们称之为V1和V2。
如果我们能够在八维空间中将它们画出来,你就会发现它们之间的夹角非常大。我算了一下,大概是82度,近乎垂直,或者说正交。由于这些向量每一个维度都是正数,因此它们最大的夹角就是90度,不会更大了。这说明两类不同文章所对应的向量之间的夹角应该很大。
如果我们再假设另有一篇文章,八个词的词频是V3=(1,3,0,2,25,23,14,10),那么它和上述第二篇文章对应的向量的夹角只有7.5度。我用二维的坐标将这三个向量的关系大致示意如下。
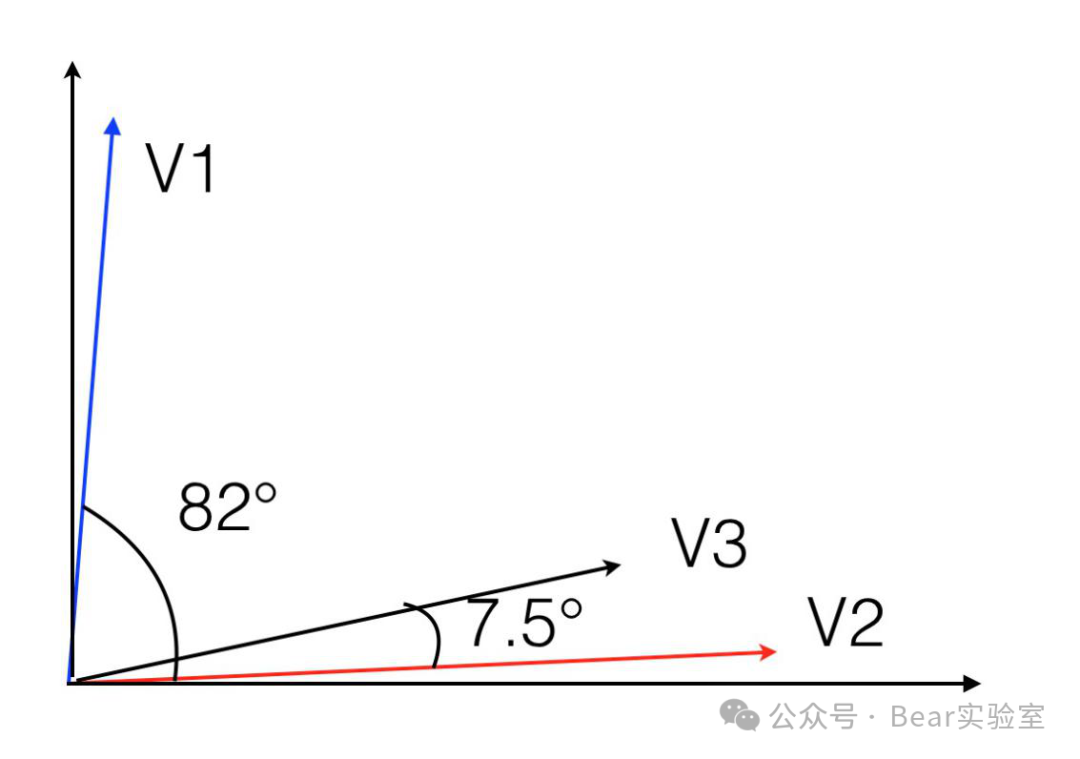
从图中可以看出第一个和第二个向量的角度很大,而第二个、第三个的夹角很小。由此,我们大致可以判定第三篇文章应该和第二篇主题相近,也属于计算机类的。
接下来我们需要思考一个问题,什么样的向量之间夹角会比较小,什么样的会几乎正交呢?
如果你对比上面三个向量,就会发现这样一个特点:当两个向量在同样的维度上的分量都比较大时,它们的夹角就很小。反之,当两个向量在不同维度上分量较大时,就近乎正交。比如第二个、第三个向量,它们在后四个维度分量值都较大,因此它们的夹角就小。而第一个向量在前四个维度的分量较大,在后四个很小,和第二个向量的情况正好错开,因此就近乎正交。关于向量的夹角,有两个特殊情况大家需要留心一下: 数字化转型网(www.szhzxw.cn)
- 如果两个向量在各个维度的分量成比例,则它们的夹角为零。
- 如果一个向量在所有的维度都相等,比如像(10,10,10,10,10,10,10,10)这样的向量,它可能和任何一个向量都不太接近。这个性质我们后面还要用到。
当然,在真实的文本分类中不止这8个词,有10万这个数量级的词汇,因此每一篇文章对应的向量大约有10万维左右,这些向量我们称之为特征向量。
通过利用余弦定理计算特征向量之间的夹角,我们就能判断哪些文本比较接近,该属于同一类。向量不仅可以对文章进行分类,而且还可以对人进行分类。今天很多大公司在招聘员工时,由于简历特别多,会先用计算机自动筛选简历,其方法的本质,就是把人根据简历向量化,然后计算夹角。
二、One-hot独热编码
接下来讲讲把文本变成向量的方法,一种常见且众所周知的表示分类数据的方法是独热编码。此方法将数据集中的每个项目转换为一个由零和一个“1”组成的向量。想象一个词汇表,其中每个单词在向量中都被分配一个唯一的位置。例如,在一个由三个单词“苹果”、“香蕉”、“樱桃”组成的简单词汇表中,“苹果”一词可能表示为 [1, 0, 0],“香蕉”表示为 [0, 1, 0],“樱桃”表示为 [0, 0, 1]。这种方法简单易懂,但它有很大的局限性。
独热编码的主要问题是效率低下,尤其是在词汇量较大的情况下。每个单词都需要一个与整个词汇量一样长的向量,这会导致内存消耗高和表示稀疏。此外,这种方法无法捕捉单词之间的任何语义关系。“Apple”和“banana”可能比“apple”和“cherry”更相似(都是水果),但在独热编码中,所有单词彼此等距。
这正是嵌入发挥作用的地方,它提供了一种更细致、更高效的数据表示方式。嵌入将独热编码向量映射到低维空间,其中相似的项目会更紧密地放在一起。这种转换是从数据中学习而来的,使模型能够辨别和编码数据中的关系和模式。例如,在嵌入空间中,“苹果”和“香蕉”可能会更紧密地放在一起,反映出它们作为水果的语义相似性,与其他非水果词不同。
通过利用嵌入,机器学习模型可以更深入地了解数据,从而获得更准确、更有洞察力的结果。无论是捕捉 NLP 任务中的语言细微差别,还是识别用户行为模式,嵌入都提供了一种更高效、更复杂的处理复杂数据的方法。 数字化转型网(www.szhzxw.cn)
三、嵌入如何工作?
- 表示:在 NLP 中,语言中的每个唯一单词都表示为连续向量空间中的密集向量。这些向量通常具有固定大小(如 100、300 或 512 维),与词汇量大小无关。
- 语境含义:与提供稀疏且无信息量的独热编码(其中每个单词只是长向量中的不同索引)不同,嵌入可以捕获有关单词的更多信息。具有相似含义或在相似语境中使用的单词在嵌入空间中往往更接近。例如,“国王”和“王后”可能由彼此接近的向量表示。
- 训练:可以使用 Word2Vec、GloVe 等算法或 BERT(用于上下文嵌入)等更高级的方法在大型文本语料库(如新闻文章、维基百科或网页)上对嵌入进行预训练。该模型会学习将具有相似含义的单词放在这个高维空间中。
- 降维:此表示允许降维。该模型不再处理数千或数百万个唯一单词,而是处理维度空间小得多的向量。
- 模型中的使用:这些向量表示随后可以被输入到各种机器学习模型(如神经网络)中,用于情感分析、机器翻译或内容推荐等任务。
- 超越词语:嵌入的概念超越了词语,包括句子、段落、用户 ID、产品等,其中相似的项目由嵌入空间中的接近的向量表示。 数字化转型网(www.szhzxw.cn)
它为什么有用:
- 效率:它们提供了紧凑、密集的表示。
- 语义含义:它们捕捉单词或事物的深层语义含义。
- 灵活性:可以用于各种机器学习任务。
- 迁移学习:预先训练的嵌入可用于提高数据有限任务的性能。
让我们以词嵌入的简单例子来说明嵌入的工作原理。假设我们的词汇量非常小,只有五个单词:[“cat”、“dog”、“fish”、“run”、“swim”]。在传统方法中,我们可能使用独热编码来表示这些单词,其中每个单词都由一个向量表示,该向量在与该单词对应的位置上为“1”,其他地方为“0”。例如:
cat = [1, 0, 0, 0, 0]dog = [0, 1, 0, 0, 0]fish = [0, 0, 1, 0, 0]run = [0, 0, 0, 1, 0]swim = [0, 0, 0, 0, 1]
在独热编码中,每个单词与其他单词的距离相等;没有相似性或上下文的概念。
四、嵌入过程
- 训练:我们使用模型来学习嵌入。假设我们的模型学习二维嵌入(实际上,它们的维度要高得多,但为了简单起见,我们使用二维)。 数字化转型网(www.szhzxw.cn)
- 得到的嵌入:模型可能会学习以如下方式表示这些单词:
cat=[0.9,0.1]dog = [0.85, 0.15]fish = [0.1, 0.8]run = [0.2, 0.7]swim = [0.15, 0.85]
嵌入提供了一种捕捉单词之间语义关系和相似性的方法,这是独热编码所不具备的,现在我们有了:
- 相似性:请注意“cat”和“dog”在这个嵌入空间中彼此接近(两者在第一个维度上的值都较高,在第二个维度上的值较低)。这反映了它们作为宠物的相似性。
- 差异性:相比之下,“cat”和“swim”相距较远,表明相似性较低。
- 上下文分组: “rum”和“swim”等活动彼此之间距离更近,并且与“fish”(在上下文上与游泳相关)的距离比与“cat”或“dog”的距离更近。
五、嵌入工作原理的简单示例
让我们通过一个简化的过程来了解如何使用基本的机器学习概念开发这样的模型。我们将使用一种非常基本的方法,重点是清晰度而不是性能或可扩展性。
假设你有一小部分句子,每个句子都包含“cat”、“dog”、“fish”、“run”和“swim”等单词。这些句子形成一个语料库,一个微型世界,其中“cat and dog are pets”或“fish swim in water”是典型的场景。
现在,考虑分析这些句子,将它们分解成单个单词。这有点像标记化,每个单词都独立存在。你甚至可以决定放弃一些常用词,那些没有增加太多趣味的词,比如“and”或“are”。
接下来,以二维向量的形式赋予每个单词自己的身份。这些向量最初是随机的,有点像不假思索地为每个单词分配一个独特的指纹。
真正的魔力始于你为每个单词定义上下文。想象一下选择一个窗口大小,比如说目标单词两侧的两个单词。这是每个单词的直接邻域,是它们在句子世界中的社交圈。
然后,你开始一个简单的学习过程。目标是让共享上下文的单词也共享相似的向量。这有点像在数值空间中将它们推得更近。你可以通过调整单词的向量来做到这一点,使其更像其邻居的向量。同时,将其推离不共享其上下文的随机单词的向量。 数字化转型网(www.szhzxw.cn)
这个过程不是一次性的事情。它更像是一个循环。你浏览语料库中的每个单词,根据其邻居更新其向量。有时,你还会让它与随机的、不相关的单词略有不同。
随着你不断重复这个过程,迭代一次又一次,向量开始稳定下来。它们会找到一种平衡点,在这个点上调整会变得越来越小。这就是收敛,向量现在不仅代表随机分配,还代表基于单词出现的上下文的有意义的关系。这个过程重复足够多次后,就会揭示出你的语料库中隐藏的结构,即从头开始构建的单词关系图。
六、在 GPT 等大型模型中的工作原理
与 Word2Vec 等模型中的传统词嵌入相比,GPT 等模型中的嵌入工作方式有所不同。GPT 是一种基于转换器的模型,它使用更复杂且更能感知上下文的方法进行嵌入。以下是OpenAI Embedding之后转化成的向量示例

想象一下,GPT 是一位语言大师,首先将文本分解成标记。与使用整个单词的简单方法不同,GPT 通常选择子词单元,例如字节对编码。这种细致入微的方法使其能够高效处理大量单词,即使是那些罕见或从未见过的单词。 数字化转型网(www.szhzxw.cn)
然后,每个 token 都会被赋予一个初始身份,即以嵌入向量形式呈现的数字 DNA。这些嵌入并不是随机分配的;它们是在 GPT 训练过程中精心学习的,为每个 token 提供了基础理解。
现在,让我们来思考一下理解语言的挑战:这不仅关乎单词,还关乎单词的顺序。GPT 通过在其嵌入中注入位置编码来解决这个问题。这些就像秘密信号,对于序列中的每个位置都是唯一的,确保单词的顺序永远不会丢失。
当这些初始嵌入和位置编码进入 GPT 的转换层时,真正的语境化就开始了。在这里,在并行处理过程中,模型会在每个其他标记的上下文中检查每个标记。这是通过自注意力机制完成的,这是一种复杂的工具,可以让每个标记了解其与其他标记的相关性。
随着输入文本穿过 Transformer 的连续层,嵌入也会不断演变。随着每一层,它们会吸收更多上下文,从而丰富其表示。这不仅仅是表面层次的理解;它是对每个 token 的深入、情境化的洞察,受到整个输入序列的影响。 数字化转型网(www.szhzxw.cn)
当文本到达最后一层时,每个标记都会出现一个向量表示。这些向量表示不仅仅是独立的含义,它们具有深刻的语境,不仅反映了标记本身,还反映了它与序列中其他每个标记的关系。
这些最终的嵌入可以用于多种任务 – 文本生成、语言翻译、问答等。GPT 嵌入的主要特点是:它们具有上下文感知、动态、分层,并且受益于子词标记化。这使得 GPT 对语言的理解丰富而细致入微,远远超越了更简单的模型。从本质上讲,GPT 的嵌入机制是语言学和技术的复杂融合,可以捕捉对语言的深刻而多方面的理解。
七、最后
嵌入代表了机器学习和自然语言处理领域的一项重要进步。它们提供了一种将分类数据(例如单词或图像)转换为机器学习模型可以处理的数字格式的有效方法。从基本的独热编码到更复杂的嵌入技术的转变反映了机器处理大型复杂数据集的显着改进。
随着该领域的不断发展,嵌入在处理和解释大量数据方面的作用可能会变得更加突出。它们与 GPT 等高级模型的集成凸显了它们在当前和未来 AI 技术中的重要性。因此,嵌入仍然是持续开发更复杂、更高效的机器学习系统的重要组成部分。 数字化转型网(www.szhzxw.cn)
数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!





翻译:
The basic principles of GPT Embedding are clearly stated in plain language
Digital Transformation Network Artificial Intelligence topics
Learn with the world’s top AI professionals! Digital Transformation Network has established a research and learning community dedicated to discussing artificial intelligence technology, industry, and academia, and grow together with you! Welcome to scan code to join!
Embedding is a fundamental concept in machine learning, especially in the field of natural language processing (NLP), but they are also widely used in other fields. In general, embedding is a method of transforming discrete classified data into continuous vectors, often in high-dimensional Spaces, transforming complex, difficult-to-process items such as words, images, or user ids into a form that machine learning models can understand and process more efficiently.
What is a vector
In mathematics, a vector (also called a Euclidean vector, a geometric vector, or a vector) is a quantity that has magnitude and direction. It can be visualized as a line segment with an arrow.
The arrow points to the direction of the vector. The length of the line segment represents the magnitude of the vector. The quantity corresponding to a vector is called a quantity (called a scalar in physics), and the quantity (or scalar) has only a magnitude and no direction.
Usually we represent a vector in a coordinate system by a line segment with a length and an arrow. In general, in Cartesian coordinates (plane coordinates) we like to place the vector’s starting point at the origin, the end point at some point in the coordinate system, and then we draw a line segment with an arrow from the origin to that point. 数字化转型网(www.szhzxw.cn)
Since there are two lines with length and arrows from the origin of the coordinates, we can calculate the Angle between the two vectors. Of course, the vector in a normal computer is multi-dimensional, such as OpenAI Embeddings is 1536 dimensional, but the logic is the same.
What does the Angle between vectors have to do with embedding and search? The following borrow teacher Wu Jun in mathematics general explanation, easy to understand. I admire teacher Wu Jun very much. Even though I was a mathematics major at that time, I still gained a lot from listening to his class. Understanding from another Angle can make my knowledge more full and three-dimensional.
What’s the use of figuring out the Angle between two vectors? It actually has many applications, such as the automatic classification of text. These two things seem unrelated, how can they be connected? Here we will introduce the principle of automatic text classification by computer.
We know that the theme and content of an article are actually determined by the words used in it. Different articles use different words, but the words used in articles with similar themes have great similarities.
For example, there may be words such as “finance”, “stock”, “trading”, and “economy” in articles about finance, and words such as “software”, “Internet”, and “semiconductor” often appear in articles about computers. If these two parts of the keywords are not repeated, then we can easily separate the two types of text. 数字化转型网(www.szhzxw.cn)
What if they duplicate? So we’re going to look at the frequency of each word in these two types of texts. In our experience, even if there are some computer words mixed in a financial article, their word frequency will not be too high, and vice versa.
To illustrate how to distinguish between these two types of articles, let’s assume that there are only eight words in Chinese: “finance”, “stock”, “trading”, “economy”, “computer”, “software”, “Internet” and “semiconductor”. Suppose you have an article about economics with the number of occurrences of these eight words (23, 32, 14, 10, 1, 0, 3, 2), and another article about computers with the number of occurrences of these eight words (3, 2, 4, 0, 41, 30, 31, 12), so that they each form an eight-dimensional vector, which we call V1 and V2.
If we could draw them in eight dimensions, you would see that the Angle between them is very large. I did the math, it’s about 82 degrees, almost vertical, or orthogonal. Since these vectors are positive in every dimension, the maximum Angle between them is 90 degrees, no greater. This means that the Angle between the vectors corresponding to the two different types of articles should be large.
If we assume another article with an eight-word frequency of V3= (1,3,0,2,25,23,14,10), then the Angle between it and the corresponding vector in the second article is only 7.5 degrees. The relationship between these three vectors is outlined in two-dimensional coordinates as follows.
As can be seen from the figure, the angles between the first and second vectors are large, while the angles between the second and third vectors are small. From this, we can roughly determine that the third article should be similar to the second topic, also belongs to the computer class.
Now we have to think about the question, what are the angles between vectors that are small, and what are the angles that are almost orthogonal?
If you compare the above three vectors, you will find this characteristic: when two vectors have larger components in the same dimension, their Angle is small. Conversely, when two vectors have large components in different dimensions, they are nearly orthogonal. For example, the second and third vectors have larger component values in the last four dimensions, so their Angle is small. The first vector has a large component in the first four dimensions and a small component in the last four, which is just staggered from the second vector, so it is almost orthogonal. There are two special cases of angles between vectors that you need to be aware of:
If the components of two vectors are proportional in each dimension, the Angle between them is zero.
If a vector is equal in all dimensions, such as (10, 10, 10, 10, 10, 10), it may not be very close to any of them. We’re going to have to use this property later.
Of course, in the real text classification, there are more than these 8 words, there are 100,000 words of this order of magnitude, so the corresponding vectors of each article are about 100,000 dimensions, and these vectors are called feature vectors.
By using the law of cosine to calculate the Angle between the eigenvectors, we can determine which texts are close and belong to the same class. Vectors can classify not only articles, but also people. Today, many large companies in the recruitment of staff, due to the large number of resumes, will first use the computer to automatically screen resumes, the essence of the method is to quantify people according to the resume, and then calculate the Angle.
2. One-hot unique heat coding
Moving on to the method of turning text into vectors, a common and well-known method of representing classified data is unique thermal coding. This method converts each item in the data set to a vector consisting of zeros and a “1”. Imagine a vocabulary in which each word is assigned a unique position in a vector. For example, in a simple vocabulary consisting of three words, “apple,” “banana,” and “cherry,” the word “apple” might be represented as [1, 0, 0], “banana” as [0, 1, 0], and “cherry” as [0, 0, 1]. This approach is simple to understand, but it has major limitations.
The main problem with monothermal coding is its inefficiency, especially in the case of large vocabularies. Each word requires a vector as long as the entire vocabulary, which results in high memory consumption and sparse representation. In addition, this approach fails to capture any semantic relationships between words. “Apple” and “banana” may be more similar than “apple” and “cherry” (both fruits), but in unique heat coding, all words are equidistant from each other.
This is where embedding comes into play, providing a more nuanced and efficient representation of data. Embedding maps unique thermal coding vectors to low-dimensional Spaces, where similar items are placed more closely together. This transformation is learned from the data and enables the model to discern and encode relationships and patterns in the data. For example, in an embedded space, “apple” and “banana” might be placed closer together, reflecting their semantic similarity as fruits, unlike other non-fruit words. 数字化转型网(www.szhzxw.cn)
By leveraging embeddings, machine learning models can gain a deeper understanding of the data, resulting in more accurate and insightful results. Whether it’s capturing linguistic nuances in NLP tasks or identifying patterns of user behavior, embedding offers a more efficient and sophisticated way to process complex data.
3. How does embedding work?
Representation: In NLP, every unique word in a language is represented as a dense vector in a continuous vector space. These vectors usually have a fixed size (such as 100, 300, or 512 dimensions), independent of vocabulary size.
Contextual meaning: Unlike unique thermal coding, which provides sparse and uninformative information (where each word is just a different index in a long vector), embedding can capture more information about the word. Words that have similar meanings or are used in similar contexts tend to be closer together in the embedding space. For example, “king” and “queen” might be represented by vectors that are close to each other. 数字化转型网(www.szhzxw.cn)
Training: Embedding can be pre-trained on large text corpora such as news articles, Wikipedia, or web pages using algorithms such as Word2Vec, GloVe, or more advanced methods such as BERT (for contextual embedding). The model learns to place words with similar meanings in this high-dimensional space.
Dimensionality reduction: This indicates that dimensionality reduction is allowed. Instead of dealing with thousands or millions of unique words, the model deals with vectors with much smaller dimensional Spaces.
Use in models: These vector representations can then be fed into various machine learning models (such as neural networks) for tasks such as sentiment analysis, machine translation, or content recommendation.
Beyond words: The concept of embedding goes beyond words to include sentences, paragraphs, user ids, products, etc., where similar items are represented by close vectors in the embedding space.
Why it’s useful: 数字化转型网(www.szhzxw.cn)
Efficiency: They provide a compact, dense presentation.
Semantic meaning: They capture the deep semantic meaning of words or things.
Flexibility: Can be used for a variety of machine learning tasks.
Transfer learning: Pre-trained embeddings can be used to improve performance for data-limited tasks.
Let’s use a simple example of word embedding to illustrate how embedding works. Suppose we have a very small vocabulary of five words: [” cat “, “dog”, “fish”, “run”, “swim”]. In traditional methods, we might represent these words using a unique thermal code, where each word is represented by a vector that is “1” in the position corresponding to that word and “0” elsewhere. For example:
cat = [1, 0, 0, 0, 0]
dog = [0, 1, 0, 0, 0]
fish = [0, 0, 1, 0, 0]
run = [0, 0, 0, 1, 0]
swim = [0, 0, 0, 0, 1]
In unique heat coding, each word is at an equal distance from the other words; No concept of similarity or context. 数字化转型网(www.szhzxw.cn)
4. The embedding process
Training: We use models to learn embeddings. Let’s say our model learns two-dimensional embeddings (in reality, they are much higher in dimensions, but for simplicity, let’s use two dimensions).
Resulting embeddings: The model might learn to represent these words in the following way:
cat=[0.9, 0.1]
dog = [0.85, 0.15]
fish = [0.1, 0.8]
run = [0.2, 0.7]
swim = [0.15, 0.85]
Embeddings provide a way to capture semantic relationships and similarities between words that single-thermal coding doesn’t have, and now we have:
Similarity: Note that “cat” and “dog” are close to each other in this embedding space (both have higher values in the first dimension and lower values in the second dimension). This reflects their similarity as pets.
Differences: In contrast, “cat” and “swim” are far apart, indicating lower similarity.
Contextual grouping: Activities such as “rum” and “swim” are closer to each other and closer to “fish” (contextually related to swimming) than to “cat” or “dog.”
5. A simple example of how embedding works
Let’s go through a simplified process to understand how to develop such a model using basic machine learning concepts. We’ll use a very basic approach that focuses on clarity rather than performance or scalability. 数字化转型网(www.szhzxw.cn)
Suppose you have a small set of sentences, each containing words like “cat,” “dog,” “fish,” “run,” and “swim.” These sentences form a corpus, a miniature world in which “cat and dog are pets” or “fish swim in water” are typical scenarios.
Now, consider analyzing these sentences and breaking them down into individual words. It’s kind of like tokenization, where each word stands on its own. You may even decide to drop common words that don’t add much interest, like “and” or “are.”
Next, give each word its own identity in the form of a two-dimensional vector. These vectors are initially random, a bit like assigning a unique fingerprint to each word without thinking about it.
The real magic starts when you define context for each word. Imagine choosing a window size, say two words on either side of the target word. This is the immediate neighborhood of each word, their social circle in the sentence world. 数字化转型网(www.szhzxw.cn)
Then, you begin a simple learning process. The goal is to have words that share context also share similar vectors. It’s kind of like pushing them closer together in numerical space. You can do this by tweaking the vector of a word to make it more like its neighbor’s vector. At the same time, push it away from the vector of random words that do not share their context.
This process is not a one-time thing. It’s more of a loop. You browse through each word in the corpus, updating its vector based on its neighbors. Sometimes, you also make it slightly different from random, unrelated words.
As you keep repeating this process, iterating over and over again, the vector starts to stabilize. They find an equilibrium point at which the adjustment becomes smaller and smaller. This is convergence, where vectors now represent not only random assignments, but also meaningful relationships based on the context in which the word appears. Repeat this process enough times, and it will reveal hidden structures in your corpus, word relationships built from scratch.
6. Working principle in large models such as GPT
Compared with traditional word embeddings in models such as Word2Vec, embeddings in models such as GPT work differently. GPT is a translater-based model that uses a more complex and context-aware approach to embedding. The following is an example of the vector that OpenAI Embedding will be converted to
Imagine that GPT is a master of language, first breaking down text into markup. Unlike the simple method of using whole words, GPT usually selects sub-word units, such as byte pair encoding. This nuanced approach allows it to efficiently process large numbers of words, even those that are rare or never seen before. 数字化转型网(www.szhzxw.cn)
Each token is then given an initial identity, which is digital DNA in the form of an embedded vector. These embeddings are not randomly assigned; They are carefully learned during GPT training, providing a foundational understanding for each token.
Now, let’s think about the challenge of understanding language: it’s not just about the words, it’s about the order of the words. GPT solves this problem by injecting positional coding into its embeddings. These are like secret signals that are unique to each position in the sequence, ensuring that the order of words is never lost. 数字化转型网(www.szhzxw.cn)
When these initial embeddings and positional codes enter the transformation layer of GPT, the real contextualization begins. Here, during parallel processing, the model examines each tag in the context of each other. This is done through the self-attention mechanism, a sophisticated tool that allows each marker to learn its relevance to the others.
Embeddings evolve as input text moves through Transformer’s continuous layers. With each layer, they absorb more context, enriching their presentation. This is not just a superficial understanding; It is a deep, contextualized insight into each token, influenced by the entire sequence of inputs.
When the text reaches the final layer, a vector representation appears for each tag. These vectors represent more than just independent meanings, they have a deep context that reflects not only the marker itself, but also its relationship to every other marker in the sequence.
These final embeddings can be used for a variety of tasks – text generation, language translation, question answering, and more. The main characteristics of GPT embeddings are that they are context-aware, dynamic, layered, and benefit from subword tokenization. This gives GPT a rich and nuanced understanding of language that goes far beyond simpler models. In essence, the embedding mechanism of GPT is a complex fusion of linguistics and technology that can capture a deep and multifaceted understanding of language. 数字化转型网(www.szhzxw.cn)
7. Finally
Embeddings represent an important advance in the field of machine learning and natural language processing. They provide an efficient way to convert classified data, such as words or images, into a digital format that machine learning models can process. The shift from basic thermal coding to more complex embedding techniques reflects significant improvements in machines handling large, complex data sets.
As the field continues to evolve, the role of embeddings in processing and interpreting large amounts of data is likely to become more prominent. Their integration with advanced models such as GPT highlights their importance in current and future AI technologies. Therefore, embeddings remain an important part of the ongoing development of more complex and efficient machine learning systems.
Digital Transformation Network Artificial Intelligence topics
Learn with the world’s top AI professionals! Digital Transformation Network has established a research and learning community dedicated to discussing artificial intelligence technology, industry, and academia, and grow together with you! Welcome to scan code to join!
本文由数字化转型网(www.szhzxw.cn)转载而成,来源于Bear实验室 ,作者iBear;编辑/翻译:数字化转型网宁檬树。


