与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!

一、美国代表性人工智能AI大模型有哪些?
1、GPT-4
OpenAI的GPT-4模型是2023年最好的AI大模型,没有之一。GPT-4模型于2023年3月发布,展示了其强大的能力,包括复杂的推理能力、高级编码能力、多种学术学习能力、可媲美人类水平表现的能力等。
GPT-4模型已经在超过1万亿个参数上进行了训练,支持32768个令牌的最大上下文长度。最近的报道透露,GPT-4是一个混合模型,由8个不同的模型组成,每个模型都有2200亿个参数。
2、PaLM 2 (Bison-001)
谷歌的PaLM 2 AI模型,它也是2023年最好的大型语言模型之一。Google在PaLM 2模型上专注于常识推理、形式逻辑、数学和20多种语言的高级编码。据说,最大的PaLM 2模型已经在5400亿个参数上进行了训练,最大上下文长度为4096个令牌。
它也是一个多语言模型,可以理解不同语言的习语、谜语和细致入微的文本。这是其他大模型难以解决的问题。PaLM 2的另一个优点是它的响应速度非常快,可以同时提供三个响应。
3、Claude v1
Claude是一个强大的大模型,由谷歌支持的Anthropic开发。它是由前OpenAI员工共同创立的,其方法是构建有用、诚实和无害的人工智能助手。在多个基准测试中,Anthropic的Claude v1和Claude Instant模型显示出了巨大的前景。事实上,Claude v1在MMLU和MT-Bench测试中的表现要好于PaLM 2。
它接近于GPT-4,在MT-Bench测试中得分为7.94,而GPT-4得分为8.99。在MMLU基准测试中,Claude v1获得75.6分,GPT-4获得86.4分。Anthropic也成为第一家在其Claude-instant-100k模型中提供10万代币作为最大上下文窗口的公司。你基本上可以在一个窗口中加载近75000个单词。
4、Cohere
Cohere是一家人工智能初创公司,由曾在谷歌大脑团队工作的前谷歌员工创立。它的联合创始人之一Aidan Gomez参与了Transformer架构的“Attention is all you Need”论文的撰写。与其他AI公司不同,Cohere为企业服务,并为企业解决生成式AI用例。Coherence有很多模型,从小到大,从只有6B个参数到训练了52B个参数的大模型。
5、Gemini
Gemini 是最新、功能最强大的大型语言模型 (LLM),由 Google 子公司 Google Deepmind 团队开发,Gemini 是一个“原生多模态 AI 模型”,它被从头开始设计为包含文本、图像、音频、视频的多模态模型,和代码,一起训练形成一个强大的人工智能系统。
6、LLaMA
LlaMA是Meta AI开发的一种新的开源大语言模型。它正式发布了各种类型的LLaMA模型,从70亿个参数到650亿个参数。LLaMA 65B模型在大多数用例中都显示出了惊人的能力。它在Open LLM排行榜上名列前十。Meta表示,它没有进行任何专有训练。相反,该公司使用了来自CommonCrawl、C4、GitHub、ArXiv、维基百科、StackExchange等网站的公开数据。
7、Guanaco-65B
LLaMA衍生的模型中,Guanaco-65B被证明是最好的开源大模型,Guanaco有四种类型:7B、13B、33B和65B型号。Tim Dettmers和其他研究人员在OASST1数据集上对所有模型进行了微调。
8、 Vicuna 33B
Vicuna是LMSYS开发的另一个强大的开源大模型。它也是从LLaMA衍生而来的。它使用监督指导进行了微调,训练数据是从sharegpt.com网站上收集的。这是一个自回归的大模型,基于330亿个参数进行训练。
9、MPT-30B
MPT-30B是另一个与LLaMA衍生模型竞争的开源大模型。它是由Mosaic ML开发的,并对来自不同来源的大量数据进行了微调。它使用来自ShareGPT Vicuna、Camel AI、GPTeacher、Guanaco、Baize和其他的数据集。这个开源模型最棒的部分是它有8K令牌的上下文长度。
二、美国人工智能AI大模型发展状态如何?
从2012年AI萌芽时期,到2022年ChatGPT带来的AI浪潮,美国一直是AI领域的破局者,引领着全世界AI的进一步发展。无论是算力、算法,还是数据,美国都牢牢占据主导地位。
现在几乎所有AI大模型训练时采用的Transformer网络结构,是谷歌在2017年提出的,它具有优秀的长序列处理能力,更高的并行计算效率,无需手动设计以及更强的语义表达能力等特征。Transformer的提出让大模型训练成为可能。
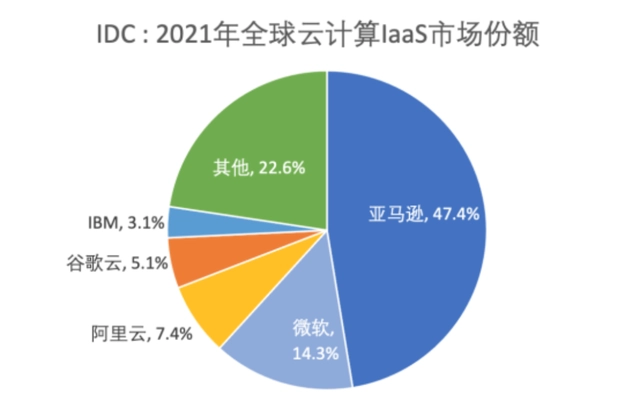
算力是保证AI大模型出现在美国的另一个关键。美国拥有世界上最大的云计算企业。IDC数据显示,2021年全球IaaS市场中,包括亚马逊、微软、谷歌、IBM在内的美国企业合计占比近70%。
算力的另一个维度是芯片,高性能的芯片可以提供更加高效的计算能力,从而加速训练过程。
2016年,黄仁勋亲手将世界第一台DGX-1(英伟达计算平台)捐献给了OpenAI,DGX-1是3000人花费3年时间才研发出来的首个轻量化的小型超算,计算和吞吐能力相当于 250台传统服务器。有了DGX-1,OpenAI之前一年的计算量只要一个月就能完成。
目前为止,英伟达的A100芯片仍然是唯一能够在云端实际执行任务的GPU芯片。最近的GTC2023上,黄仁勋又更新了新芯片H100的进度。H100配有Transformer引擎,可以专门用作处理类似ChatGPT的AI大模型,由其构建的服务器效率是A100的十倍。
从经济、文化、政策、人才,到资金、硬件、软件、环境,几乎在每个方面都领先其他人一大截,这也导致目前行业最具代表性的AI大模型都集中在美国。
数字化转型网人工智能研习社
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!

本文由数字化转型网(www.szhzxw.cn)转载而成,来源于网络;编辑/翻译:数字化转型网默然。