随着金融机构传统批处理及大数据处理业务的持续增长,调度工具在支撑平台数据处理任务安全稳定运行方面发挥着日益重要的作用。本文结合建设银行自研企业级调度系统的建设过程,对大型金融机构如何构建企业级调度能力提出了可行的路径与方法,并详细介绍了调度系统在性能提升、可靠性、智能化、主机与开放平台一体化、统一资源调度等细分领域的方案设计。
作为数据类平台必不可少的核心工具之一,调度工具在传统数据批处理及新兴的大数据处理过程中一直扮演着十分重要的角色。尤其是伴随银行业务量的高速增长,建设银行的整体任务调度量已接近日均百万次以上,在此背景下,为解决前期痛点和满足业务发展的需要,建设银行围绕性能提升、可靠性、智能化、主机与开放平台一体化、统一资源调度几个方面重点展开相关工作,创新启动企业级调度系统自研项目,逐步推动由Control-M平台到自研调度平台的迁移工作,实现了单套调度日均170万次的调度量,累计申请相关专利15篇。本文从不同角度梳理、解析企业级调度系统设计方案,旨在为同业开展大规模分布式调度工作提供可借鉴的典型案例与路径参考。数字化转型网www.szhzxw.cn
一、千万级任务调度解决方案
为了满足千万级任务调度的容量要求,建设银行在总体架构层面设计事件驱动式调度模型,充分利用了成熟开源中间件的计算能力来提升调度性能。
1、完全分布式架构
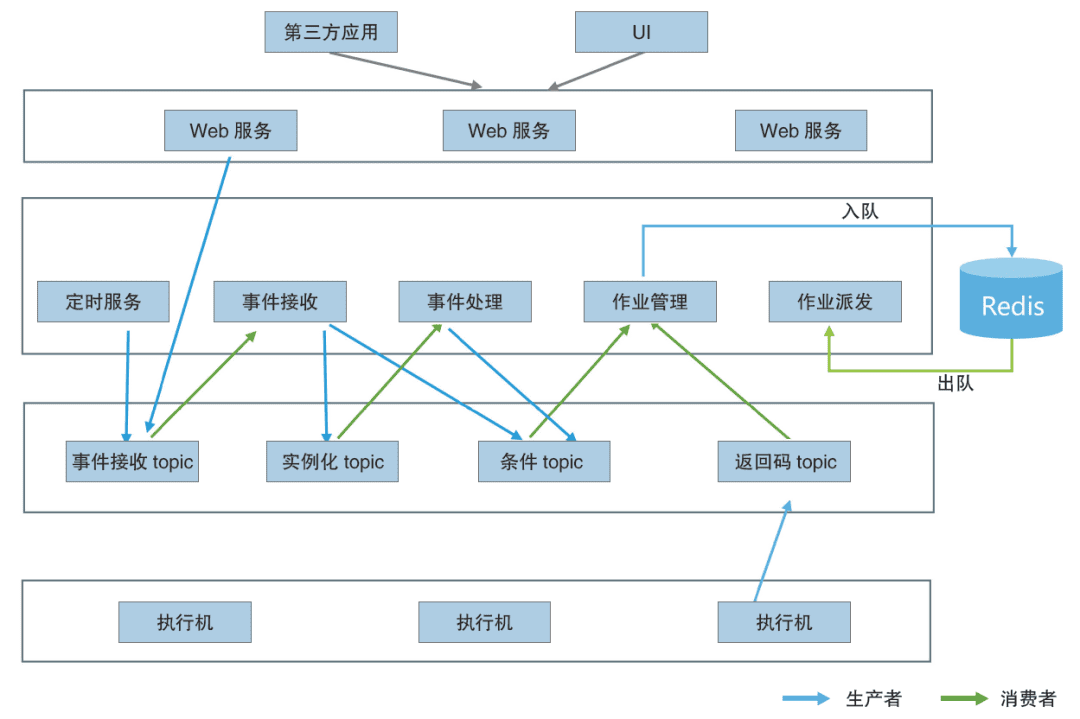
传统调度软件大多采用了“中心式”调度架构,即服务端和执行机两层模型,但该模式下服务端节点极易成为大规模任务调度的瓶颈。对此,建设银行采用完全“去中心化”的分布式架构,遵循“高内聚、低耦合”的设计原则,通过中间件Redis或者RocketMQ对后端核心组件进行解耦(从事件的接收、条件转换、工作流实例化到任务的派发、执行、状态管理,组件之间分工明确),无需额外依赖数据库进行分布式控制,而且在出现性能瓶颈时,只需要通过简单的节点扩容即可以实现性能扩展。分布式调度架构如图1所示。
2、事件驱动式调度数字化转型网www.szhzxw.cn
传统调度软件通常采用轮询式的触发方式,如轮询判断条件到达、轮询修改任务状态等,从而在很大程度上影响了调度性能。为规避轮询操作,建设银行在系统中将调度过程涉及的驱动工作流实例化、条件就绪、资源释放、告警触发等一系列场景全部抽象成了具体“事件”。其中,一类是与任务运行相关的任务运行类事件,如自定义事件、文件到达事件、时间就绪事件、任务依赖事件等;另一类是为了实现特定功能场景的控制类事件,如资源释放事件、告警触发事件等。上述事件将由生产方先存入RocketMQ,再由其他组件进行分布式消费,从而大幅提升事件处理效率。截至目前,整个系统日均处理的各类消息总量近千万条,并实现了毫秒级延迟。
3、高效缓存
考虑调度系统自身场景的复杂性,随着调度任务量的持续上升,大量的状态流转和逻辑控制易使数据库成为整个系统的瓶颈,而传统的分库分表解决方案会增加逻辑控制上的复杂性。对此,建设银行基于Redis丰富的数据结构,选择将数据库中的高频操作转化为Redis操作,以进一步降低数据库热表的操作频度,提升整个系统的性能。例如,在常见的场景任务重跑中,利用Redis提供的有序集合(Zset),将任务的重跑时间作为分值,每次定时线程只要处理时间分值超过当前时间的记录即可,避免了常规做法中利用定时线程对整库进行重跑扫描产生的大量排序和无效扫描操作。数字化转型网www.szhzxw.cn
二、金融级可靠性解决方案
调度系统的可靠性直接关系到上层业务加工的时效性(如银行开门报表生成、监管数据报送等)。为此,除依托分布式架构带来的无单点故障优势外,建设银行着重考虑企业级调度系统的异常处理机制,实现了多租户隔离、中间件高可靠、任务断点恢复等多项特性。
1、多租户隔离
多租户隔离主要包含两个层面:一是任务实例的多租户隔离,即将不同租户的任务在条件就绪后放置到不同的租户队列中,由多线程并发进行处理。按照租户划分队列之后,不同租户的任务实例信息即可实现隔离,并支持对不同租户的队列采用不同的处理策略。二是底层运行的计算资源实现多租户资源隔离,以容器任务为例,通过对不同租户任务使用不同的资源组,利用Namespace实现该资源组的任务管控。
2、中间件高可靠
调度系统的各个组件通过RocketMQ进行消息流转,因此需要着重考虑RocketMQ异常时对业务处理可靠性的影响,即在充分衡量RocketMQ自身可靠性的同时,还需考虑消息在处理过程中遇到异常时的可靠性,比如数据库连接异常、IO异常等,此时如果直接确认MQ的消息,即意味着该消息的“丢失”。针对上述挑战,建设银行选择利用MQ自身的确认机制,在非业务自身逻辑异常的情况下进行自动重试,并着力保证重试的幂等性,例如在消息处理过程中遇到数据库异常时,会自动回滚本次事务,保证重新拉取后能继续处理。此外,对于Redis的可靠性,除了Redis自身持久化带来的可靠性保证以外,在Redis数据丢失时,企业级调度系统还可从数据库自动重建至Redis,以保证服务不中断。数字化转型网www.szhzxw.cn
3、任务断点恢复
当任务在执行机本地运行或者容器内运行时,调度服务可能会由于各种异常情况导致自身服务中断。针对上述情况,建设银行选择在系统中根据任务运行状况实时记录临时状态文件(如执行阶段、进程信息等),并在调度服务恢复时根据这些信息直接复原成目前任务的最新状态,从而实现任务的断点恢复。此外,由于调度服务自身不断上报心跳信息,当心跳未更新时间超过阈值时,企业级调度系统还可快速感知服务异常,并及时恢复任务状态。
三、智能化解决方案
调度系统结合智能化设计可高效满足任务运行、运维过程中的诸多需求,如派发过程中高、低优先级任务的派发策略,以及辅助运维人员及时感知系统故障等。对此,建设银行在企业级调度系统中着重实现了智能化任务排程、智能化运维。
1、智能化任务排程数字化转型网www.szhzxw.cn数字化转型网www.szhzxw.cn
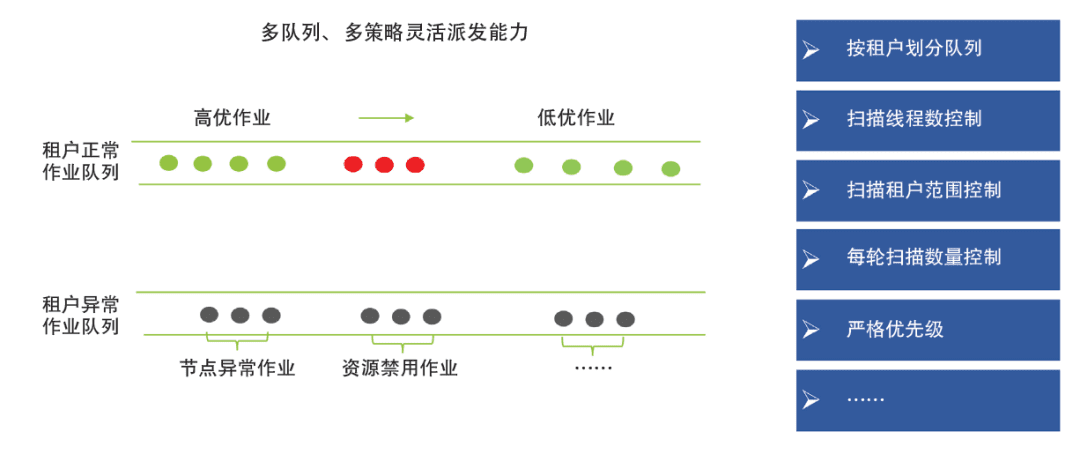
任务派发(即将任务分发到执行节点)是整个任务调度控制的核心环节,派发过程需要考虑的因素较多,如扫描策略、优先级等。在具体设计过程中,建设银行在重点考虑多租户公平性、任务优先级与任务并行度的同时,为了最大化避免无效扫描,选择将因异常情况(如任务下发失败、执行节点硬件资源不足等)导致的无法派发任务临时挪入异常队列,并在惩罚时间过后再移入正常队列。此外,对于每个派发服务,还允许设置不同的扫描策略,如设置线程数、租户扫描范围等参数。在此基础上,建设银行结合Redis构建多队列、多策略的智能派发架构,使企业级调度系统实现了500个任务/秒的派发效率和高优先级任务毫秒级的派发延迟,为海量任务调度打下了坚实基础。智能化任务排程如图2所示。
2、智能化运维
鉴于调度系统在整个数据类平台中处于较底层的位置,智能化排障能力将直接影响运维人员的使用体验。对此,建设银行选择从任务维度梳理出目前调度场景中的常见问题,对核心业务流程进行埋点,进而基于轨迹分析推断当前的异常原因,并将其通过可视化的方式集成到前端界面,使运维人员即使不熟悉底层原理也可以自行进行问题定位。截至目前,企业级调度系统已可以覆盖80%左右的任务运行故障,且通过任务的血缘分析功能,该系统还可以快速定位整个受影响的加工链路,并在类似数据重供、系统异常等情况下进行批量自动链路重跑。此外,企业级调度系统为全局批处理加工提供了按应用和场景分类的多级监控维度,并实现了核心加工链路的关键路径自动推算。在系统层面,通过提前预定义各类异常,企业级调度系统支持在业务流程中将各类异常推送到MQ,由专门的模块进行实时分析,进而实现了智能化预警与告警,使运维人员可以在第一时间感知系统的健康状况。
四、主机与开放平台一体化解决方案
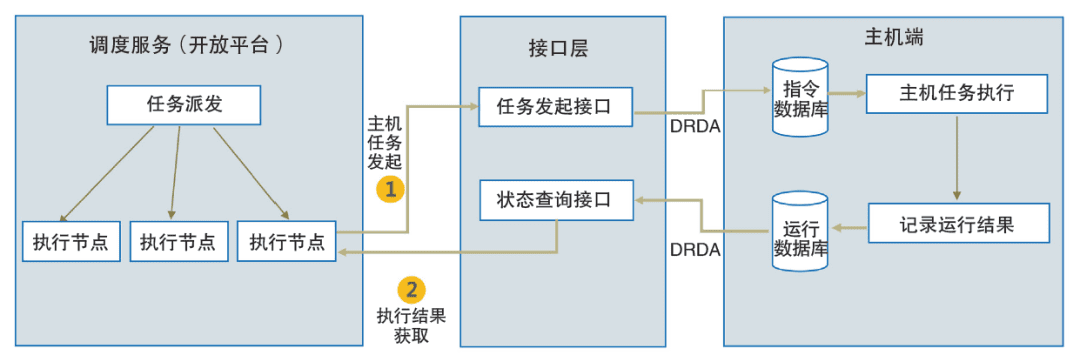
在信息系统建设初期,建设银行选择通过部署主机版调度工具来实现主机任务的调度执行,这一方式不仅占用了宝贵的主机资源,而且难以和开放平台形成统一的企业级管理视图。为解决上述问题,建设银行选择利用接口层来封装主机平台的操作(如任务发起、状态查询等),调度服务则通过接口层与主机进行交互。此模式既保证了两者之间的松耦合,也使得任务配置、任务下发和任务执行的流程与开放平台的任务调度流程完全一致,从而实现了对主机和开放平台任务的一体化支持,形成了企业级统一管理视图。主机与开放平台一体化解决方案如图3所示。
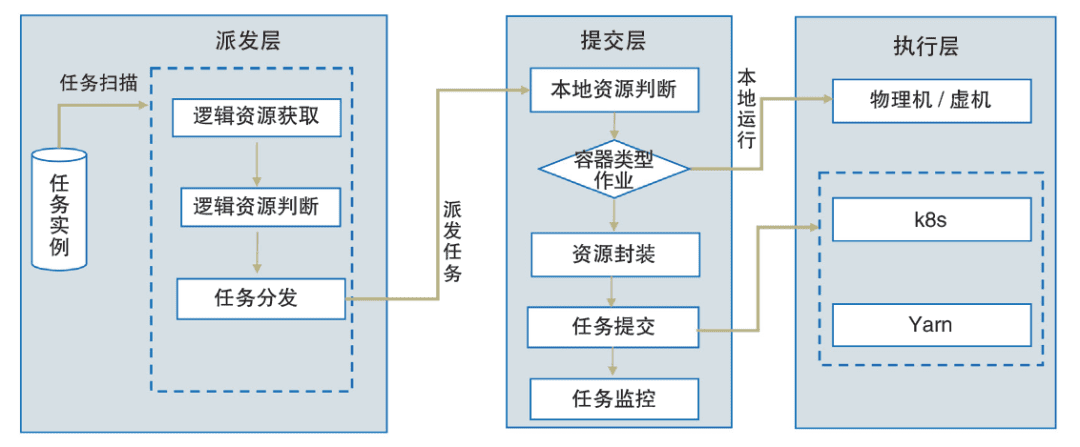
五、统一资源调度解决方案
随着大数据技术的快速发展,混合异构计算平台已成为业界的主流应用之一,并要求调度系统能更好地发挥底层计算平台的能力,提高资源利用率。对此,为提高在不同运行环境下的资源精细化管理能力(包括执行机本地、容器、Yarn等),建设银行在总体设计上将资源划分为了逻辑资源和物理资源两类。其中,逻辑资源代表任务并发度,可由应用灵活定义,在任务派发环节进行控制;物理资源代表任务所使用的CPU、内存等具体硬件资源,主要在任务运行环节进行控制。此外,对于物理资源的控制,建设银行还提供了统一的资源调度框架,涵盖资源的封装、申请、提交和监控等环节,实现了按任务维度的资源管控,较好地满足了大数据类任务的资源控制需求,并对上层应用屏蔽了底层框架的复杂度。统一资源调度方案如图4所示。数字化转型网www.szhzxw.cn
六、后续展望
目前,建设银行企业级调度系统已经在k8s的基础上实现了一层使用封装,但采用的仍是原生k8s调度器,而原生k8s调度器更偏向于离散型的调度模式,在诸如以大数据任务为主的场景下,缺乏类似多租户、容量调度等对离线计算任务比较重要的功能,同时也难以满足高并发、大容量调度场景。对此,建设银行后续拟结合k8s自身机制(如scheduling framework等)实现对原生k8s调度器的增强。此外,在众多数据类系统中,调度加工链路中的任务最终要产生供上层系统使用的表数据,其中热点表数据的加工时效问题往往会带来较大的业务影响。对此,建设银行考虑在企业级调度系统引入相关AI算法模型,对产生热点数据的加工链路的任务配置合理性(如优先级、依赖关系等)、任务运行趋势和资源使用率等进行自动分析,并提供优化建议。从发展趋势上看,调度系统需要更好融合任务调度和资源调度能力,实现“两驾马车”并跑,才能更好满足金融行业在传统批处理、大数据、AI等领域的调度使用需求。数字

化转型网wzhzxw.cn
翻译:
With the continuous growth of traditional batch processing and big data processing services of financial institutions, scheduling tools play an increasingly important role in supporting the safe and stable operation of data processing tasks on platforms. Based on the construction process of self-developed enterprise-level scheduling system of China Construction Bank, this paper proposes feasible paths and methods for large financial institutions to build enterprise-level scheduling capability, and introduces the scheduling system’s scheme design in the subdivisions of performance improvement, reliability, intelligence, integration of host and open platform, unified resource scheduling and so on in detail.
As one of the essential core tools of data platform, scheduling tool has been playing a very important role in the process of traditional data batch processing and emerging big data processing. Especially with the rapid growth of bank business volume, the overall task scheduling volume of China Construction Bank has approached more than one million times per day. Under this background, in order to solve the early pain points and meet the needs of business development, China Construction Bank focuses on performance improvement, reliability, intelligence, integration of host and open platform, and unified resource scheduling. 数字化转型网www.szhzxw.cn
Innovatively started the self-developed project of enterprise-level scheduling system, gradually promoted the migration from Control-M platform to self-developed scheduling platform, realized the daily scheduling volume of 1.7 million for a single set of scheduling, and applied for 15 related patents in total. This paper combs and analyzes the design scheme of enterprise-level scheduling system from different perspectives, aiming at providing typical cases and path reference for the large-scale distributed scheduling work of the industry.
Ten million level task scheduling solution
In order to meet the capacity requirements of tens of millions of tasks scheduling, China Construction Bank designed an event-driven scheduling model at the overall architecture level and made full use of the computing power of mature open source middleware to improve scheduling performance.
Completely distributed architecture
Most traditional scheduling software adopts the “central” scheduling architecture, that is, the two-layer model of server and executor, but the server node is easy to become the bottleneck of large-scale task scheduling under this mode. In this regard, China Construction Bank adopts a completely “decentralized” distributed architecture and follows the design principle of “high cohesion and low coupling”. It decoupling back-end core components through middleware Redis or RocketMQ (from event reception, condition conversion and workflow instantiation to task distribution, execution and state management, with clear division of labor among components). There is no need to rely on the database for distributed control, and when performance bottlenecks occur, simple node expansion is needed to achieve performance expansion. Figure 1 shows the distributed scheduling architecture.
Figure 1 Distributed scheduling architecture数字化转型网www.szhzxw.cn
Event-driven scheduling
Traditional scheduling software usually uses polling trigger mode, such as polling to judge condition arrival and polling to modify task state, which greatly affects scheduling performance. In order to avoid polling operation, the construction bank abstracts a series of scenarios involved in the scheduling process, such as workflow instantiation, condition readiness, resource release and alarm triggering, into specific “events”. Among them, one is the task running events related to the task running, such as custom events, file arrival events, time ready events, task dependent events, etc.
The other type of events is control events for specific functional scenarios. Such as resource release events and alarm triggering events. These events are first stored in RocketMQ by the producer and then consumed by other components in a distributed manner, greatly improving event processing efficiency. Up to now, the total number of messages processed by the entire system is close to 10 million per day, and has achieved millisecond latency.数字化转型网www.szhzxw.cn
Efficient caching
Considering the complexity of the scheduling system itself, with the continuous increase of scheduling tasks. A large number of state flow and logical control can easily make the database become the bottleneck of the whole system. While the traditional solution of database and table will increase the complexity of logical control. In this regard, based on the rich data structure of Redis, China Construction Bank chooses to convert high-frequency operations in the database into Redis operations to further reduce the operation frequency of the database hot table and improve the performance of the whole system.
For example, in the common scenario task rerun, the ordered set (Zset) provided by Redis is used to take the task rerun time as the score value, and each time the timing thread only needs to process the records whose time score exceeds the current time. This avoids the large number of sorting and invalid scanning operations caused by the rerun scanning of the whole library by the timing thread in the common practice.
Financial reliability solutions
The reliability of dispatch system is directly related to the timeliness of upper business processing. (Such as bank opening report generation, regulatory data submission, etc.). Therefore, in addition to the advantages of no single point of failure brought by the distributed architecture, China Construction Bank focuses on the exception handling mechanism of the enterprise-level scheduling system, and realizes multiple features such as multi-tenant isolation, high reliability of the middleware and task breakpoint recovery.数字化转型网www.szhzxw.cn
Multi-tenant isolation
Multi-tenant isolation mainly consists of two levels: one is multi-tenant isolation of task instances, that is. The tasks of different tenants are placed in different tenant queues after the conditions are ready. And concurrently processed by multiple threads. After the queues are divided by tenant, the task instance information of different tenants can be isolated and different processing policies can be adopted for queues of different tenants. Second, the computing resources running at the bottom realize multi-tenant resource isolation. Take container tasks as an example, you can use different resource groups for different tenant tasks and Namespace to manage and control the resource group tasks.
High reliability of middleware
Each component of the scheduling system carries out message flow through RocketMQ. So it is necessary to focus on the impact of RocketMQ anomalies on the reliability of business processing. That is, while fully measuring the reliability of RocketMQ itself. It is also necessary to consider the reliability of messages when they encounter anomalies during processing. Such as database connection anomalies, IO anomalies, etc. At this point, if the MQ message is directly acknowledged, it means that the message is “lost.” In response to the above challenges, China Construction Bank chooses to use the confirmation mechanism of MQ to automatically retry in the case of non-business logic exception. And strives to ensure the idempotency of retry.
For example, when the database exception is encountered in the process of message processing. The transaction will be automatically rolled back to ensure that the process can continue after re-pulling. In addition, for the reliability of Redis. In addition to the reliability guarantee brought by the persistence of Redis itself, when the Redis data is lost. The enterprise-class scheduling system can also automatically rebuild from the database to Redis to ensure that the service is not interrupted.
Task breakpoint recovery
When a task is running locally or in a container. The scheduling service may interrupt itself due to various abnormal conditions. In view of the above situation, the construction bank chooses to record temporary status files (such as execution phase and process information) in real time according to the task running status in the system. And directly restores to the latest status of the current task according to the information when the dispatching service is restored. So as to realize the breakpoint recovery of the task. In addition, the scheduling service continuously reports heartbeat information. If the heartbeat update time exceeds the threshold. The enterprise-level scheduling system can quickly detect service exceptions and restore the task status in time.数字化转型网www.szhzxw.cn
Intelligent solutions
The scheduling system combined with intelligent design can effectively meet many requirements in the process of task operation and operation and maintenance. Such as the distribution strategy of high and low priority tasks in the distribution process. And assist operation and maintenance personnel to timely perceive system faults. In this regard, the Construction Bank emphasizes the realization of intelligent task scheduling, intelligent operation and maintenance in the enterprise dispatching system.
Intelligent task scheduling
Task distribution (that is. The task is distributed to the execution node) is the core part of the whole task scheduling control. Many factors need to be considered in the distribution process, such as scanning policy and priority. In the specific design process, while focusing on multi-tenant fairness, task priority and task parallelism. In order to avoid invalid scanning to the maximum extent. The construction Bank selected to temporarily move the tasks that could not be dispatched due to abnormal circumstances (such as task delivery failure, insufficient hardware resources of execution nodes, etc.) to the abnormal queue, and then to the normal queue after the penalty time.
In addition, you can set different scanning policies for each distributed service. Such as the number of threads, tenant scanning range, and so on. On this basis, China Construction Bank combined with Redis to build a multi-queue and multi-strategy intelligent distribution architecture, enabling the enterprise-level scheduling system to achieve distribution efficiency of 500 tasks per second and distribution delay of high-priority tasks at millisecond level, laying a solid foundation for mass task scheduling. Intelligent task scheduling is shown in Figure 2.
Figure 2 Intelligent task scheduling数字化转型网www.szhzxw.cn
Intelligent operation and maintenance
Considering that dispatching system is at the lower level in the whole data platform. Intelligent obstacle removal ability will directly affect operation and maintenance personnel’s experience. Therefore, China Construction Bank sorted out common problems in the current scheduling scenarios from the task dimension. Buried the core business process, inferred the current abnormal causes based on trajectory analysis. And integrated them into the front-end interface in a visual way. So that operation and maintenance personnel could locate problems by themselves even if they were not familiar with the underlying principles.
Up to now, the enterprise-level scheduling system has been able to cover about 80% of task operation faults. And through the task blood analysis function, the system can also quickly locate the entire affected processing link. And in the case of similar data resupply, system anomalies and other circumstances. The system can automatically run the link in batches. In addition, the enterprise-level scheduling system provides multi-level monitoring dimensions classified by application and scenario for global batch processing. And realizes the automatic calculation of the critical path of the core processing link. At the system level, by pre-defining various types of exceptions. The enterprise-level scheduling system can push various types of exceptions to MQ in business processes for real-time analysis by specialized modules, thus realizing intelligent early warning and alarm. So that operation and maintenance personnel can sense the system health status in the first time.
Integrated solution of host and open platform
In the early stage of information system construction. China Construction Bank chose to implement host task scheduling by deploying host version scheduling tool. This method not only occupied valuable host resources. But also was difficult to form a unified enterprise-level management view with the open platform. To solve the above problems, the construction Bank chooses to use the interface layer to encapsulate the operations of the host platform (such as task initiation, status query, etc.). And the scheduling service interacts with the host through the interface layer.
This mode not only ensures the loose coupling between the two. But also makes the process of task configuration, task delivery, and task execution completely consistent with the process of task scheduling on the open platform. In this way, the integrated support for host and open platform tasks is realized. And a unified enterprise-level management view is formed. The host and open platform integration solution is shown in Figure 3.
Figure 3. Integration solution of host and open platform
Unified resource scheduling solution
With the rapid development of big data technology, mixed heterogeneous computing platform has become one of the mainstream applications in the industry, and it is required that scheduling system can better play the capacity of the underlying computing platform and improve the utilization rate of resources. To improve resource refinement management capabilities (including executing machine local, container, and Yarn) in different running environments. CCB divides resources into logical resources and physical resources. Among them, logical resources represent the degree of task concurrency. Which can be flexibly defined by the application and controlled in the task distribution link.
Physical resources represent hardware resources, such as CPU and memory, used by tasks and are controlled during task running. In addition, for the control of physical resources, China Construction Bank also provides a unified resource scheduling framework, covering the links of encapsulation, application, submission and monitoring of resources, realizing resource management and control by task dimension, better meeting the resource control requirements of big data tasks. And shielding the complexity of the underlying framework from upper-layer applications. Figure 4 shows the unified resource scheduling scheme.
Figure 4 Unified resource scheduling scheme数字化转型网www.szhzxw.cn
Future Prospects
At present, the enterprise scheduling system of China Construction Bank has implemented a layer of use encapsulation on the basis of k8s. But it still uses the original k8s scheduler, which is more inclined to discrete scheduling mode. In the scenario dominated by big data tasks, the original k8s scheduler lacks functions that are more important for offline computing tasks. Such as multi-tenant and capacity scheduling. At the same time, it is difficult to meet the high concurrency and large capacity scheduling scenarios. Therefore, China Construction Bank plans to enhance the original k8s scheduler by combining k8s mechanism such as scheduling framework.
In addition, in many data systems. The tasks in the scheduling and processing link will eventually generate table data for the upper layer system. Among which the processing time of hot table data often brings great impact on the business. In this regard, China Construction Bank considered introducing relevant AI algorithm model into the enterprise-level scheduling system to automatically analyze the rationality of task configuration (such as priority, dependency, etc.), task operation trend and resource utilization rate of the processing link that generates hot data, and provide optimization suggestions. From the perspective of development trend. The scheduling system needs to better integrate task scheduling and resource scheduling capabilities to achieve “two chariots” and run together. So as to better meet the scheduling and use needs of the financial industry in traditional batch processing, big data, AI and other fields.
本文由数字化转型网(www.szhzxw.cn)转载而成,来源:中国金融电脑;编辑/翻译:数字化转型网宁檬树。
免责声明: 本网站(http://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。