国泰君安证券数据中心总经理 曾宏祥
国泰君安证券数据中心副总经理 毛梦非
国泰君安证券数据中心 冯一欣 叶璞钰
顺应数字化转型趋势,本文结合证券行业智能运维发展现状与趋势,以智能运维算法创新为关键切入点,总结梳理了证券业运维转型面临的算法挑战,并以构建复杂系统的全维观测能力为目标,创新提出了数字孪生系统分析体系解决方案,同时详细介绍了落地路径与适用场景。数字化转型网www.szhzxw.cn
当前,证券业正处于快速发展的历史机遇期,资本市场改革和金融体系开放在为各家券商带来业务增量的同时,也对其金融科技水平和抗风险能力提出了更高要求,而证券交易系统的平稳、健康运行不仅与广大投资者的合法权益密切相关,更是涉及金融安全、社会稳定的重要课题。实际场景中,证券业务具有交易时段集中、交易规模巨大等显著特点,对IT系统的可用性和响应效率均有着非常严苛的要求,给系统运维工作带来了巨大压力。在此背景下,证券业运维工作急需开展智能化转型,以更为高效地支撑业务发展。
一、证券业运维转型面临的算法挑战
现阶段,智能运维的主流方案一般基于“大数据+机器学习”技术实现,即应用统计学方法来分析告警、事件、指标、日志等大数据样本,并结合机器学习算法进一步预测系统行为,这一模式的主要特点是应用驱动、事后分析、数据拟合。然而,伴随智能化运维需求的持续提升,智能算法出现了一些难以解决的问题,并导致其在复杂系统全维度监控、故障定位等工作中面临着诸多挑战。
1、盲人摸象式算法无法洞见系统整体运行情况
在传统的监控系统中,运维人员通常更关注基础监控、应用服务的接口请求量等指标,但在复杂系统中,仅仅关注单点日志或者单个维度指标并不足以帮助其掌握系统的整体运行状况。例如,当行情火爆时,单指标异常检测算法可能会基于访问并发数产生CPU告警,但通过分析日志可以发现,这一情况在证券业属于正常现象。数字化转型网www.szhzxw.cn
2、数据缺陷无法得到有效补偿
在运维领域,故障数据的稀疏性会导致算法没有足够的样本,使其只能在有限的数据范畴内进行建模、拟合、预测,从而影响智能算法的实际效果。但在实际工作中,由于证券行业对后台服务运行的稳定性和安全性要求极高,系统故障本身是一个小概率、低频事件,而算法需要基于大量历史数据来学习规律,并借此实现优化提升,如果之前发现的故障后来不再出现了,那么实际上是形成了一个悖论。
3、算法适应性不足
由于运维系统架构复杂,关联关系呈网状发展,数据驱动的算法很难做到适应性演进。与此同时,如果使用一个缺乏观测、分析系统内部运行机制的结构化模型,意味着必须开展大量的数据采集、模型适配、参数调优等工作来确保分析准确性,而一旦过分依赖大数据,会导致模型对黑天鹅事件等难以形成有效预测。此外,证券业系统变更频繁,基于历史大数据样本得到的经验规律和特征模型经常难以再复用,也无法准确分析和预测当前系统行为,而针对不同类型的问题场景定制专门的分析解决方案,将大幅提升运维人员的技能学习成本。
4、算法缺乏有效的反馈和修正机制
在实际应用中,智能运维算法并非“开箱即用”,而是需要与运维数据、业务特点、运维目标等深度融合,不断进行打磨和适配。但是,目前大多数算法缺乏基于反馈的模板调整能力,难以应对“这种模板应该根据这个变量拆分”“这个变量应该被泛化”等个性化需求。此外,运维专家与算法设计人员对于“故障”的理解也不尽相同,从而导致算法可能进行了无效学习或是错误学习,并直接影响了算法的有效性。
二、数字孪生系统分析体系建设路径
针对上述难点,证券业急需以实现复杂IT平台可观、可测、可控为目标,从实时、在线维度还原系统工作机制并构建系统分析模型,研究、设计和验证具有系统性、鲁棒性、自适应、自学习的智能运维新算法,以更好满足复杂系统潜在故障检测以及系统稳定性分析等运维需求。数字化转型网www.szhzxw.cn
1、总体规划
围绕上述目标,笔者团队以实现复杂系统的整体可观测性为核心,从系统内部的白盒化思路出发,提出了数字孪生系统分析体系建设规划,并进一步细分为两个阶段:
第一阶段是自上而下建立多层次指标体系,即通过描述系统内不同组件、模块之间的依赖关系,构建系统内各指标间的非线性影响权重量化模型,以更为准确地展现IT系统运行状态,同时为数据管理、数据分析、智能运维等场景提供基础数据;并在此基础上,结合数据融合、特征工程、智能分析等手段,全面、准确、及时把握高维复杂状态空间,满足IT平台的全维度观测需求。
第二阶段是自下而上构建数字孪生镜像模型,通过降低数据依赖性、提升算法适应性,使得在系统结构或业务环境发生改变时,可基于数据动态输入、算法动态调整,让数字孪生镜像模型快速适应系统变化,最终在整体保持系统稳定性与可靠性的同时,高效解决大规模、多尺度时变平台的实时调控问题,实现对IT平台能力的量化评估。数字化转型网www.szhzxw.cn
2、算法设计
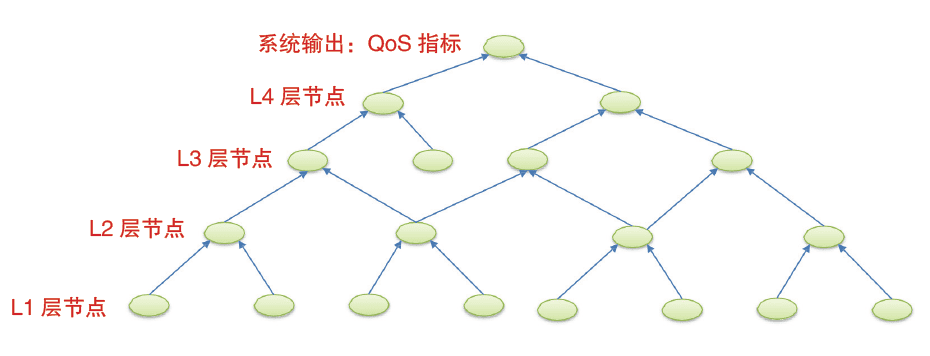
IT系统中各类资源构成的参数空间具有数量庞大、参数间存在复杂的非线性交互影响等特点。为分析IT系统不同模块之间的关联交互作用,首先需要量化分析不同模块相关参数对相邻模块以及服务质量关键指标(Quality of Service,QoS)的贡献程度,从而建立模块之间的量化交互模型。为此,笔者团队将平台中不同层级的功能模块抽象为不同的逻辑功能节点,并构建了分层影响作用树(如图1所示)。其中,每个节点根据不同的模型类型,均可以代表系统转移函数、特定性能指标等具体含义,节点间的连线则可用于表示模块间接口变量、指标之间的非线性影响权重。
在此基础上,笔者团队搭建了一种非线性影响权重量化模型,该模型能够通过多个源指标构成的幂集元素对目标指标的影响程度来描述IT系统的基础特性。同时,结合非线性叠加测度理论,笔者团队在模型中引入了全新方法来量化模块间参数的相互作用,即通过分析各个参数相互作用下的影响重要性,以此来定量表征模型参数间的相互作用,该模型的突出特点是能够用广义非线性非可加积分(Choquet积分)来定量评测模型变量之间的相互作用对QoS的贡献度。例如,当给定一组观测数据,模型可以通过评估系统变量的非叠加测度来发掘变量之间的复杂依赖关系,并量化单一变量及变量组合对目标函数(系统性能)的贡献大小。
此外,考虑IT系统本身具有复杂行为模式、冗余设计、反馈和滞后响应机制、临界点行为、系统持续演进等特点,而上述因素都会对准确评估IT系统健康度产生影响,笔者团队针对性建立了基于马尔科夫链的状态转移概率模型,用于探索IT系统内在可辨识的隐结构。具体而言,隐结构具有一定的稳定性,可反映出IT系统特有的工作模式、运动规律,同时还具有足够的灵敏性,可在系统出现异常时实现及时感知。
最后,笔者团队通过记录节点在状态迁移过程中的性能指标,基于节点的正常、异常状态比例,根据特定标准实现了对节点健康度的统计评分。该健康度评分方法基于节点不同状态下的期望输出指标,能够有效区分节点在不同输入激励条件下的实际工作能力,为全面评估节点在复杂系统中的复杂行为提供了一种新的视角。在此模式下,基于输入特征和输出特征的统计建模规律,将能够准确反映出节点在较长时间跨度以及不同业务模型输入条件下的服务能力和水平。数字化转型网www.szhzxw.cn
综上,前述算法主要具有以下三大特点:一是训练样本仅需准备一定量的测量指标、日志等数据,无需与历史数据强耦合,即可以构建相对稳定的量化模型;二是通过指标间非线性交互影响量化模型,可提供输入和输出的相互影响权重,使模型比基于AI的黑盒模型具备更好的可解释性;三是在泛化和可迁移性方面,由于构建了量化相互影响权重模型,模型比纯数据方法具备更好的泛化和迁移能力。
3、数据底座建设
为打破数据孤岛,实现数据统一采集、统一存储、统一管理与统一视图展示,笔者团队从能感知、会表述、自执行等维度入手,创新搭建了综合性智能化数据底座(如图2所示),以进一步拓展数据应用的深度和空间,充分发挥数据价值。
在能感知(可观)方面,笔者团队应用数字孪生技术,针对运维对象构建了数字孪生可视化界面,并引入系统健康度评估体系和方法论,实现了系统健康度可视化管理,使运维人员通过该界面能够直观了解系统健康度以及关联影响。同时,监控平台覆盖运维全领域,拥有维度丰富的各类数据,并结合智能运维算法支持快速发现故障,从而可实现对数据中心所有运行组件的全感知。
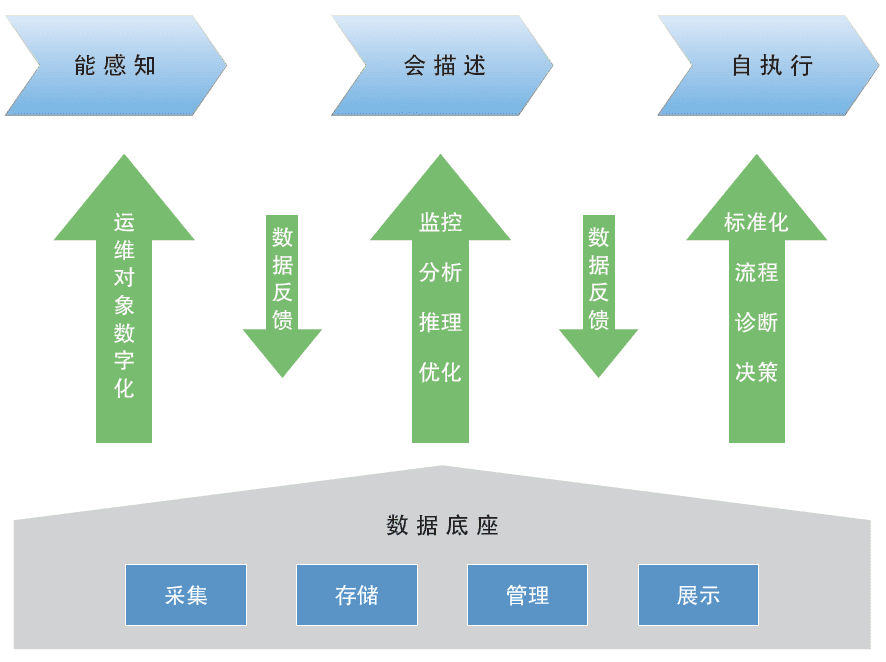
在会描述(可测)方面,智能化数据底座基于数字孪生技术中的数字虚体,可细致描述物理实体的可视化模型和内在机理,并对物理实体的状态数据进行监测、分析,进而通过不断优化模型参数,提供智能化的决策辅助功能。数字化转型网www.szhzxw.cn
在自执行(可控)方面,“知其然,并知其所以然”是数字孪生的核心理念。基于智能化数据底座,运维人员可详细了解系统内部的各种影响及互动关联机制,进而有目的地快速解决问题,实现真正的安全可控。
三、后续研究展望
当前,智能运维领域存在算法黑箱、算法同质化、模型缺陷等多种潜在风险,但业界尚未针对智能运维算法的规范性、可靠性、可迁移性、有效性等制定统一的评估方法,从而在一定程度上影响了智能运维技术的应用和发展。国泰君安作为智能运维国家标准编订单位之一,已连续多年参与智能运维领域的研究与实践,积极为智能运维国标编制建言献策。未来,国泰君安将继续作为牵头单位研制智能运维算法的治理标准,推动智能运维系列标准推广落地。在此基础上,国泰君安将携手业内同仁共同探索智能运维体系的落地路径,深入推进各项运维能力建设和场景应用:
一是不断提升感知能力的时效性,在运维对象全生命周期的初始环节,就将其纳入数据中心感知体系中进行管理。
二是持续构建“白盒”模型,运用数字孪生方法论实时还原复杂系统的运行状态,使核心业务在业务组件中的流动过程更加清晰可见,让运维决策更具时效性和可解释性。
三是提升故障预测能力,通过建立系统画像和运维基线,构建不同技术领域的故障模型,分析研判故障数据之间的相关性。数字化转型网www.szhzxw.cn
四是将标准的故障处置流程、动作及场景固化到自动化运维平台,精准识别故障场景特征,自动化实现业务快速恢复。
此外,国泰君安还将着力打造具备知识梳理、机器学习、运维决策等功能的“运维大脑”,辅助自动化处置,形成优化反馈机制,并借此打造业界优秀案例,加速推动智能运维算法在行业中的推广应用。

翻译:
Zeng Hongxiang, general manager of Guotai Junan Securities Data Center
Guotai Junan Securities data center Feng Yixin Yip Puyu
In line with the trend of digital transformation, this paper combined with the current situation and trend of the development of intelligent operation and maintenance in the securities industry, took the innovation of intelligent operation and maintenance algorithm as the key entry point, summarized and sorted out the algorithm challenges faced by the operation and maintenance transformation of the securities industry, and innovatively proposed the digital twin system analysis system solution with the goal of building the full-dimensional observation capability of complex systems. At the same time, the landing path and application scenario are introduced in detail.
At present, the securities industry is in a period of historical opportunity for rapid development. The reform of the capital market and the opening up of the financial system not only bring business increase to various securities brokerages, but also put forward higher requirements for their fintech level and anti-risk ability. The stable and healthy operation of the securities trading system is not only closely related to the legitimate rights and interests of investors. It is also an important subject concerning financial security and social stability. In actual scenarios, securities business is characterized by concentrated trading hours and huge trading scale, which imposes strict requirements on the availability and response efficiency of IT systems, bringing great pressure to system operation and maintenance. In this context, it is urgent to carry out intelligent transformation in the operation and maintenance of securities industry, so as to support business development more efficiently.
Algorithmic challenges faced by operation and maintenance transformation of securities industry
At present, the mainstream scheme of intelligent operation and maintenance is generally implemented based on “big data + machine learning” technology, that is, statistical methods are applied to analyze big data samples such as alarms, events, indicators and logs, and machine learning algorithms are combined to further predict system behavior. The main characteristics of this model are application driven, post-analysis and data fitting. However, with the continuous increase of intelligent operation and maintenance requirements, intelligent algorithms appear some problems that are difficult to solve, and lead to many challenges in complex system full-dimensional monitoring, fault location and other work.
The blind man’s feeling the elephant algorithm cannot see the overall operation of the system
In traditional monitoring systems, operation and maintenance personnel usually pay more attention to indicators such as basic monitoring and application service interface requests. However, in complex systems, only paying attention to single point logs or single dimension indicators is not enough to help them grasp the overall running status of the system. For example, when the market is hot, the single-indicator anomaly detection algorithm may generate CPU alarms based on the number of concurrent access requests. However, the analysis of logs shows that this is a normal phenomenon in the securities industry.数字化转型网www.szhzxw.cn
Data defects cannot be effectively compensated
In the field of operation and maintenance, the sparsity of fault data will lead to insufficient samples for the algorithm, so that it can only carry out modeling, fitting and prediction in a limited data category, thus affecting the actual effect of the intelligent algorithm. However, in practice, since the security industry has extremely high requirements on the stability and security of background service operation, the system failure itself is a low probability and low frequency event, and the algorithm needs to learn the rule based on a large amount of historical data, and thus realize optimization and improvement. If the fault discovered before no longer appears later, it actually forms a paradox.
Insufficient algorithm adaptability
Due to the complex architecture of operation and maintenance system and the network development of association relations, it is difficult for data-driven algorithms to achieve adaptive evolution. At the same time, if a structured model is used which lacks the internal operation mechanism of observation and analysis system, it means that a lot of data collection, model adaptation and parameter tuning must be carried out to ensure the accuracy of analysis.
However, excessive reliance on big data will make it difficult for the model to effectively predict black swan events. In addition, the securities industry system changes frequently, and the empirical rules and characteristic models obtained based on historical big data samples are often difficult to be reused, nor can they accurately analyze and predict the current system behavior. Moreover, customized special analysis solutions for different types of problem scenarios will greatly increase the skill learning cost of operation and maintenance personnel.
The algorithm lacks effective feedback and correction mechanism
In practical application, intelligent operation and maintenance algorithm is not “out of the box”, but needs to be deeply integrated with operation and maintenance data, business characteristics, operation and maintenance objectives, and constantly polished and adapted. However, most of the current algorithms lack the ability of template adjustment based on feedback, and it is difficult to deal with personalized requirements such as “this template should be split according to this variable” and “this variable should be generalized”. In addition, operation and maintenance experts and algorithm designers have different understandings of “fault”. Which may lead to ineffective or wrong learning of the algorithm, and directly affect the effectiveness of the algorithm.
Digital twin system analysis system construction path
In view of the above difficulties. IT is urgent for the securities industry to restore the working mechanism of the system from real-time and online dimensions, build the system analysis model, and research, design and verify the new intelligent operation and maintenance algorithm with systematic, robust, adaptive and self-learning, aiming at realizing the observable, measurable and controllable complex IT platform. To better meet the complex system potential fault detection and system stability analysis and other operation and maintenance requirements.
Master plan数字化转型网www.szhzxw.cn
Centering on the above goals, the author’s team, with the realization of the overall observability of complex systems as the core, proposed the construction plan of digital twin system analysis system from the idea of white box inside the system, and further subdivided into two stages:
The first stage is to establish a multi-level index system from top to bottom. That is, by describing the dependency between different components and modules in the system, to build a nonlinear influence weight quantization model among indicators in the system, so as to show the running state of the IT system more accurately and provide basic data for data management, data analysis, intelligent operation and maintenance and other scenarios. And on this basis, combined with data fusion, feature engineering, intelligent analysis and other means, comprehensively. Accurately and timely grasp the high-dimensional complex state space, to meet the IT platform’s full-dimensional observation requirements.
The second stage is to build the digital twin image model from the bottom up. By reducing data dependence and improving algorithm adaptability. The digital twin image model can adapt to system changes quickly based on dynamic data input and algorithm adjustment when the system structure or business environment changes. Finally, while maintaining the stability and reliability of the system as a whole, Effectively solve the real-time regulation problem of large-scale and multi-scale time-varying platforms, and realize the quantitative evaluation of IT platform capabilities.
Algorithm design
The parameter space composed of all kinds of resources in IT system has the characteristics of large quantity and complex nonlinear interaction among parameters. In order to analyze the correlation interaction between different modules of the IT system. The contribution degree of related parameters of different modules to adjacent modules and Quality of Service (QoS) should first be quantitatively analyzed. So as to establish a quantitative interaction model between modules. To this end, the author’s team abstracts functional modules at different levels of the platform into different logical functional nodes. And constructs hierarchical influence tree (as shown in Figure 1). According to different model types, each node can represent the system transfer function, specific performance indicators and other specific meanings. And the lines between nodes can be used to represent the nonlinear influence weight between module indirect port variables and indicators.数字化转型网www.szhzxw.cn
Figure 1 Hierarchical impact tree based on QoS indicators
On this basis, the author’s team built a nonlinear influence weight quantization model
On this basis, the author’s team built a nonlinear influence weight quantization model. Which can describe the basic characteristics of IT system through the influence degree of power set elements composed of multiple source indicators on target indicators. At the same time, combined with the nonlinear superposition measurement theory. The author’s team introduced a new method to quantify the interaction of parameters between modules in the model. That is, to quantitatively characterize the interaction between parameters of the model by analyzing the importance of influence under the interaction of each parameter.
The outstanding feature of this model is that it can use the generalized nonlinear non-additive integral (Choquet integral) to quantitatively evaluate the contribution of the interaction between model variables to QoS. For example, given a set of observed data, the model can explore complex dependencies between variables by evaluating non-superposition measures of system variables, and quantify the contribution of a single variable and a combination of variables to the objective function (system performance).
In addition, considering the characteristics of IT system itself. Such as complex behavior pattern, redundant design, feedback and delayed response mechanism, critical point behavior. And system continuous evolution, and the above factors will have an impact on the accurate evaluation of IT system health. The author’s team established a state transition probability model based on Markov chain to explore the internal discernable hidden structure of IT system. Specifically, the hidden structure has a certain stability, can reflect the IT system’s unique working mode, movement law. But also has enough sensitivity, can realize the timely perception when the system abnormal.
Finally, by recording the performance indicators of nodes in the process of state migration and based on the proportion of normal and abnormal state of nodes
Finally, by recording the performance indicators of nodes in the process of state migration and based on the proportion of normal and abnormal state of nodes. The author’s team achieved a statistical score of node health according to specific criteria. Based on the expected output indicators of nodes in different states. The health scoring method can effectively distinguish the actual working abilities of nodes under different input incentives. And provides a new perspective for comprehensively evaluating the complex behaviors of nodes in complex systems. In this mode, the statistical modeling rules based on input characteristics and output characteristics can accurately reflect the service capabilities and levels of nodes in a long time span and under different input conditions of business models.
To sum up, the above algorithm has the following three characteristics:. First, training samples only need to prepare a certain amount of measurement indicators, logs and other data. Without strong coupling with historical data, that is, a relatively stable quantitative model can be built. Second, through the nonlinear interaction quantization model among indicators. The mutual influence weights of input and output can be provided. Which makes the model more interpretable than the black box model based on AI. Third, in terms of generalization and migration, the model has better generalization and migration ability than the pure data method due to the construction of quantized mutual influence weight model.
Construction of data base
In order to break the data island and realize unified data collection, storage, management and view display. The author team innovatively built a comprehensive intelligent data base (as shown in Figure 2) from the perspectives of perception, presentation and self-execution. So as to further expand the depth and space of data application and give full play to the value of data.
In terms of perception (observable). The author’s team applied digital twin technology to construct a digital twin visual interface for operation and maintenance objects. And introduced the system health evaluation system and methodology to achieve visual system health management. So that operation and maintenance personnel can intuitively understand the system health and correlation impact through this interface. At the same time, the monitoring platform covers the whole field of operation and maintenance. Has various kinds of data with rich dimensions. And combines intelligent operation and maintenance algorithm to support rapid fault detection. So as to realize the full awareness of all operating components of the data center.数字化转型网www.szhzxw.cn
Figure 2 Intelligent data base
In terms of description (measurable), the intelligent data base is based on the digital virtual body in the digital twin technology. Which can describe the visual model and internal mechanism of the physical entity in detail. And monitor and analyze the state data of the physical entity. So as to provide intelligent decision-assisting functions through continuous optimization of model parameters.
In terms of self-execution (controllable), “know what it is and why it is” is the core concept of digital twin. Based on the intelligent data base, operation and maintenance personnel can understand the various influences and interaction mechanisms inside the system in detail. And then solve problems quickly and purposefully to achieve real safety and control.
Prospect of follow-up research
At present, there are many potential risks in the field of intelligent operation and maintenance. Such as algorithm black box, algorithm homogeneity and model defects. However, the industry has not yet developed a unified evaluation method for the standardization, reliability. Portability and effectiveness of intelligent operation and maintenance algorithms. Thus affecting the application and development of intelligent operation and maintenance technology to a certain extent. Guotai Junan, as one of the units compiling national standards for intelligent operation and maintenance. Has participated in the research and practice in the field of intelligent operation and maintenance for many years. And actively offered suggestions for the compilation of national standards for intelligent operation and maintenance. In the future, Guotai Junan will continue to be the leading unit to develop governance standards for intelligent operation and maintenance algorithms. And promote the implementation of intelligent operation and maintenance standards.
On this basis, Guotai Junan will join hands with colleagues in the industry to explore the landing path of intelligent operation and maintenance system, and further promote various operation and maintenance capacity construction and scene application:
One is to continuously improve the timeliness of the perception ability. In the initial stage of the whole life cycle of the operation and maintenance object. It is included in the perception system of data center for management.数字化转型网www.szhzxw.cn
The second is to continue to build a “white box” model and use digital twinning methodology to restore the running state of complex systems in real time. So that the flow process of core business in business components is more clearly visible. And operation and maintenance decisions are more efficient and interpretable.
The third is to improve the ability of fault prediction, through the establishment of system portrait and operation line. The construction of fault models in different technical fields, analysis and analysis of the correlation between fault data.
The fourth is to solidify the standard fault handling process, action and scene into the automated operation and maintenance platform. Accurately identify the fault scene characteristics, and automatically realize rapid business recovery.
In addition, Guotai Junan will also focus on creating the “operation and maintenance brain” with knowledge combing. Machine learning, operation and maintenance decision and other functions to assist automatic processing. Form an optimization feedback mechanism, and take this opportunity to create excellent cases in the industry and accelerate the promotion and application of intelligent operation and maintenance algorithm in the industry.
本文由数字化转型网(www.szhzxw.cn)转载而成,来源:中国金融电脑;编辑/翻译:数字化转型网宁檬树。
免责声明: 本网站(https://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。