
数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!

写在开头:
AI网络技术在全球范围内迅速迭代。大规模网络的部署优化离不开产业链的每一个关键组件的升级和革新。无论是网络拓扑架构的优化、超节点内HBD高带宽域的创新还是单个计算卡性能的突破、网络协议与接口的改进等一系列的课题,整个AI网络产业链包括奇异摩尔在内的众多企业正携手共同应对AI网络迭代带来的多层次互联瓶颈。通过复用以太网设施,奇异摩尔依托Chiplet和Modernized RDMA技术,进一步升级涵盖从网间、GPU片间及片内算力扩展的多层次互联解决方案。

一、二十年磨一剑,科技巨头续写传奇
Meta Platforms, Inc.,昔日以Facebook之名崛起,如今已是一家在全球互联网领域内颇具影响力的科技巨头。其传奇始于2004年,在哈佛大学的宿舍里,马克·扎克伯格与爱德华多·萨维林携手打造了一个专属于校园的社交网络。公司于2021年迎来了一次重要的品牌重塑,更名为Meta,这一转变不仅仅是名称上的变更,更是公司战略方向和愿景的深刻体现,预示着它将从社交网络的基石迈向构建元宇宙的辽阔天地。
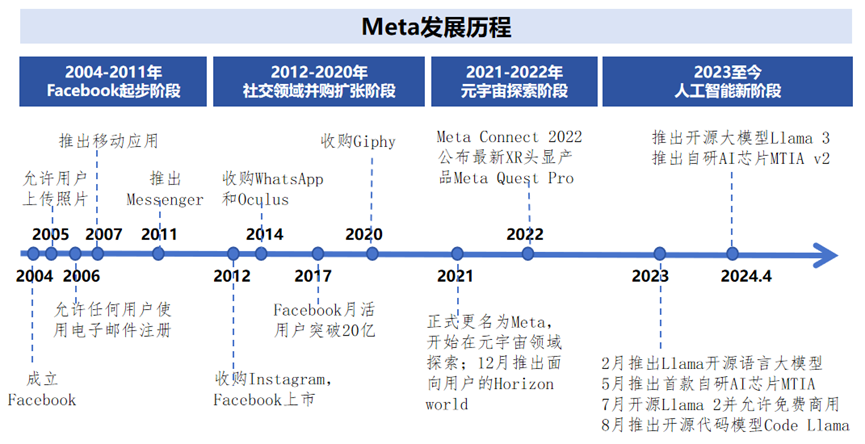
二、云巨头全面进军人工智能领域
在2023年,Meta在其企业演进中揭开了新的战略阶段,将业务焦点扩展至潜力无限的人工智能(AI)领域。公司确立以技术革新为核心驱动力,加快促进企业结构的转型与升级,旨在为公司的长期可持续增长注入活力。同年,Meta推出了Llama系列的开源大型预训练模型,及其衍生系列,如Alpaca、Vicuna等,这些模型的发布,在AI界引发了一场空前的技术创新浪潮。
Llama系列开源大模型的推出,象征着Meta在AI研究与应用领域取得了显著的进展。这些模型凭借其出色的表现、参数的高效运用以及对自然语言处理的深刻理解,在众多AI模型中显得格外突出。近日,Meta再放大招,宣布推出Llama 3.2模型,这是其免费AI模型系列中首次融入视觉识别能力的版本。这一创新扩展了模型在机器人技术、虚拟现实以及所谓的AI代理领域的应用广度和实用性。例如,Llama 3.2可以用于智能机器人,使其在复杂环境中更精准地识别和操纵物体,或者为虚拟现实游戏带来更逼真的交互体验。

三、AI网络基础设施重要性逐步凸显
AI基础设施是推动大型模型实际应用的核心。要在人工智能开发领域保持领先地位,就必须在硬件基础设施方面进行前瞻性的投资。硬件设施在AI的未来发展中扮演着决定性角色。本年度上半年,Meta披露了其两个版本的、由24,576个GPU组成的庞大数据中心集群。这些集群不仅为当前的人工智能模型提供了强大支持,也为下一代模型做好了准备,包括作为Llama 2后续产品的Llama 3系列,以及公司公开发布的大型语言模型(LLM)。预计Meta的这一代模型在单个集群中跨越 32,768 个 GPU,其在AI网络基础设施的投入将继续扩大。 数字化转型网www.szhzxw.cn
网络基础设施作为AI的重要基石,直接决定了数据中心集群的能力、效率、可靠性和安全性。随着AI技术的持续进步,对网络基础设施的需求也在不断攀升,已成为推动AI智算中心发展的关键因素。
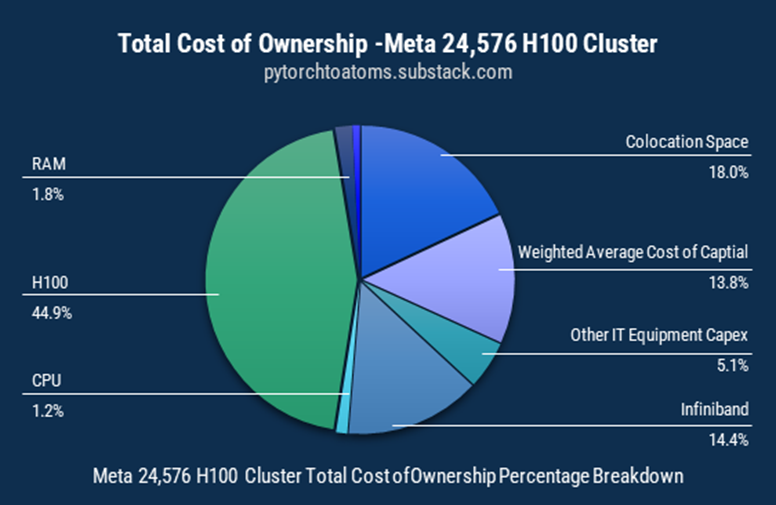
从Meta 部署的其中一个24K集群(基于Infiniband)投入占比来看,H100 GPU占比44.9%,InfiniBand投入占比14.4%,CPU仅为1.2%。整个网络设施的占比已经超过集群在计算上花费的三分之一。
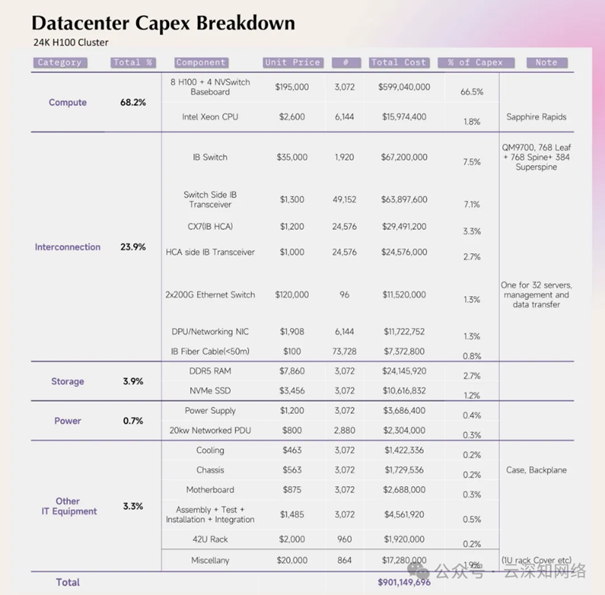
“从另一个视角审视资本支出(Capex),在24K H100集群中,网络互联的成本占到了整体资本支出的23.9%。这一开销涵盖了组网所需的交换机、光模块、DPU/智能网卡以及配套的线缆等。互联成本已经上升为继计算成本之后的第二大开支。
面对每日数百万亿次的AI模型运算需求,Meta的网络基础设施必须具备高度的前沿性和灵活性。从芯片、交换机、网卡、光模块到其他IT硬件,每一项组件都是网络枢纽不可或缺的部分,它们共同构筑了一个多层次而复杂的系统工程。
四、多层次的互联:下一代AI网络的瓶颈
成千上万的计算卡需要高效而稳定的运行,从而支持大模型指数级增长的训练/推理需求。Meta已成功扩展Infiniband和RoCE 网络,从原型发展到部署多个集群,每个集群可容纳数千个以上GPU。这些集群支持广泛的生产分布式 GPU 训练作业,包括排名、内容推荐、内容理解、自然语言处理和 GenAI 模型训练等工作负载。 数字化转型网www.szhzxw.cn
然而训练当中的故障似乎是很难避免的,据Meta前一段时间的一份研究表明,在包含 16,384 个 Nvidia H100 80GB GPU 的集群上运行的 Llama 3 405B 模型训练。训练运行持续了 54 天,在此期间,集群遇到了 419 个意外组件故障,平均每 3 小时发生一次故障。在一半的故障案例中,GPU 或其板载 HBM3 内存是罪魁祸首。如果故障没有得到正确缓解,单个 GPU 故障可能会中断整个训练作业,从而需要重新启动。然而,Llama 3 团队通过开发专有诊断工具来解决这类问题。PyTorch 的 NCCL 飞行记录器被广泛用于快速诊断和解决挂起和性能问题,尤其是与 NCCLX 相关的问题。该工具捕获集体元数据和堆栈跟踪,有助于快速解决问题。最终团队保持了超过 90% 的有效训练时间。
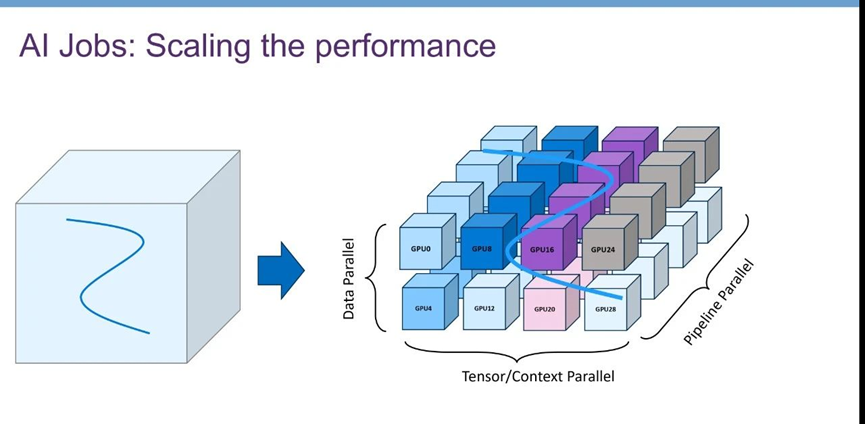
随着集群规模从万卡到十万卡方向演进,AI系统的重心已经从传统计算系统中的CPU转移到了GPU加速器。AI需求的指数级增长显著改变了数据中心基础设施的设计挑战,推动了以GPU为中心的设计发展。
五、单个GPU加速卡构成集群基础算力
理想情况下,人们希望拥有最强大的GPU加速器系统来运行整个AI任务,因为,AI任务作为一个单一实体运行。因此,直接获取最大能力的加速器似乎是合乎逻辑的选择。
“在智能计算集群的效能核心,GPU单卡的计算能力构成了集群整体算力的基石。单卡的算力、计算卡的数量、网络有效运行时间及节点内/节点间的运营效率等因素共同决定了整个集群的有效算力。
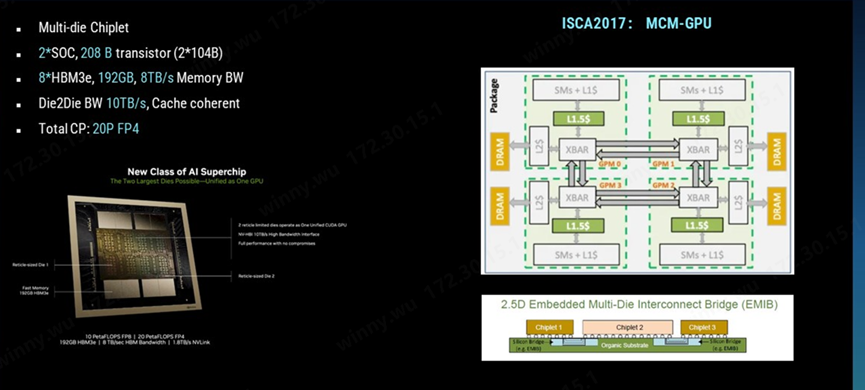
据悉,Meta是英伟达的最大客户之一,并成为首批订购英伟达Blackwell B200 AI GPU 的大型科技公司。B200采用了Chiplet Multi Die设计,4nm工艺,通过将两个GPU Die互联封装在单个芯片中,极大地提升了单卡的算力。 数字化转型网www.szhzxw.cn
如今,片内互联(Scale Inside)决定了AI网络的基础算力。单个芯片的算力和性能高度依赖于Chiplet的设计以及先进封装工艺,这些因素共同推动了单卡算力的提升。利用片内互联技术例如D2D的接口和IO Die芯粒来提升单卡算力已被证实为有效的发展途径。

六、AI网络迭代推动南北向互联技术演进
Meta 的硬件架构系统技术工程师Manoj Wadekar在5月份的SNIA Compute, Memory, and Storage Summit分享道,“使用Scale-up网络的紧密耦合任务需要极高的带宽和极低的延迟。目前,一些基于内存语义的互联技术(例如NVSwitch和Infinity Fabric)或基于消息语义的互联技术(例如RoCE)可以提供非常高的带宽和低延迟。” 数字化转型网www.szhzxw.cn
对于数据并行等松散耦合任务,Scale-out网络需要比典型的前端网络高得多的带宽,但与Scale-up网络相比略微宽松。Scale-out网络通常是基于RDMA的,例如RoCE或InfiniBand;然而,随着GPU计算卡的数量急剧上升,Scale-up网络对更高带宽的需求正在推动距离的物理极限,并催生紧密连接的集群拓扑。例如,如何确保每条链路的传输速度达到200Gbps 或400Gbps。根据Meta遇到的距离限制,这将继续推动加速器更加紧密地相互靠近。Scale-up互连网络需要承载大量内存访问,因为紧密耦合的系统将通过网络驱动非常高的带宽和低延迟需求。这也对整体系统设计产生了影响与改革。
对于Scale-out网络,随着系统扩展到更大的拓扑结构,如何保持高有效带宽,如何防止交换机、网卡和光模块产生故障,有效避免网络丢包、乱序和拥塞,尾延迟等一系列问题仍然是整个网络生态共同面临的挑战。AI领域的快速迭代速度无疑对所有构建集群的生态链构建了前所未有的挑战。Meta表示在过去的三四年里,网络技术体系经历了数次迭代包括针对AI不同应用场景的RoCE协议优化、面向大规模语言模型的定制化RoCE实现,以及InfiniBand等高速网络技术。

目前,业界包括奇异摩尔在内的UEC成员(共筑智算网络基石:奇异摩尔正式成为UEC 超以太联盟成员)正在呼唤下一代现代化高性能RDMA技术的诞生,携手云厂商、交换机、服务器及GPU厂商等共同解决现有RDMA环境下的丢包、网络死锁、拥塞、多路径传输局限、物理层及链路层的优化等各类问题。
“此外智能网卡对于AI网络的改善也起到关键作用:最新的智能网卡应该具备更高的速率带宽,自适应路由、选择性重传功能以及支持智能堆栈的可扩展性与灵活性都是下一代智能网卡的优选性能。这些创新技术为AI网络的未来奠定了坚实的基础,使得网络更加高效与可靠。
Kiwi NDSA-SNIC AI原生智能网卡
| 1 | 高性能RDMA引擎 |
| 2 | 自适应网络调度算法 |
| 3 | 基于Ethernet基础设施 |
| 4 | 实现Tb级万卡集群无损数据传输 |
| 5 | 可编程加速核心SDPU |
| 6 | 实现网络任务加速 |
七、Meta的最终愿景

随着时代的进步,Meta深知昨天乃至今天行之有效的手段,可能难以应对明日的挑战。在推动AI网络技术发展的道路上,Meta持续评估和优化其基础设施的每一个层面,从物理和虚拟层到软件层,甚至更广泛的领域。其最终愿景是打造一个既灵活又稳固的系统,以支撑不断涌现的新模型和研究,引领人工智能领域的持续进步。 数字化转型网www.szhzxw.cn
数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入! 数字化转型网www.szhzxw.cn
本文由数字化转型网(www.szhzxw.cn)转载而成,来源于网络;编辑/翻译:数字化转型网宁檬树。






