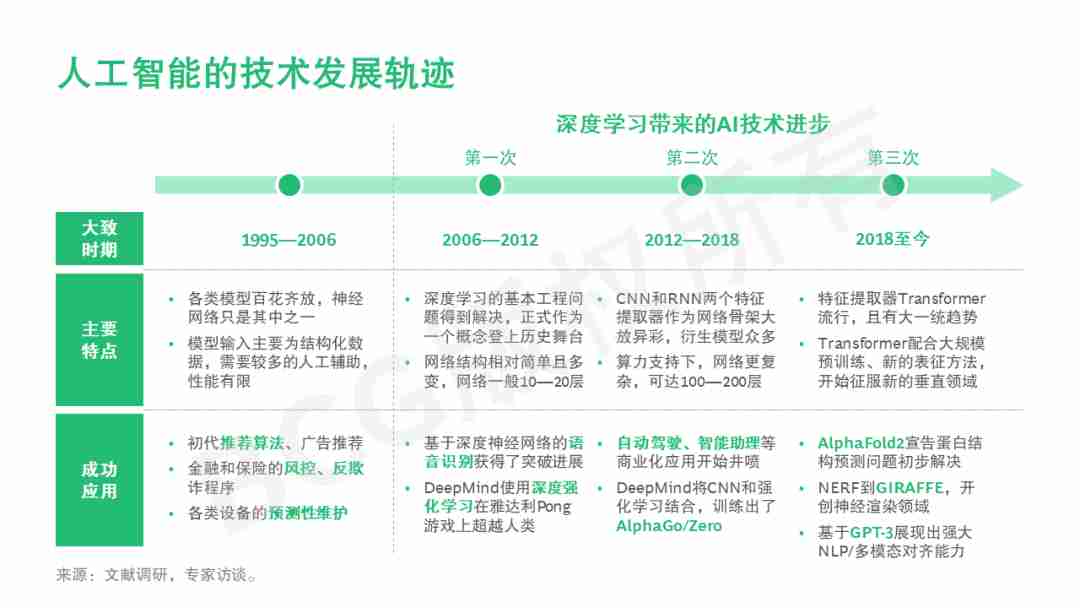
深度学习是人工智能这个领域从1956年开创以来一次重大的技术突破。从新千年开始,深度学习技术每五到七年就会有一个较大的技术进步,以2017/2018年Transformer和预训练大模型为代表,我们目前正处于由深度学习带来的第三次AI技术发展的高潮期,今天我们要谈的话题,正是本次技术进步中的一个代表性产品。
一、生成式AI的创新之处
最近以ChatGPT为代表的“生成式AI”(Generative AI)技术得到了广泛关注。和传统的对话机器人(Chatbot)不同,OpenAI的ChatGPT确实有独特的技术创新,在人工智能的发展史上会是一个里程碑,甚至有可能和2016年谷歌的AIphaGo相提并论。而且目前看来ChatGPT比AIphaGo应用落地的前景会更好更广泛,可以有力地持续推动这一波AI技术高潮的发展。
让我们首先来介绍一下对话机器人的工作机理
首先用户需要通过文字或语音向对话机器人输入一段信息,紧接着机器人会识别并理解这段信息,判断由该信息开启的对话任务,并给出相应的回复内容。最早期的对话机器人更像一个基于数据库或者知识库的查询系统,根据用户输入的信息查询到对应的答复。可以说这些答案基于不同的索引(index),已经事先存入对话机器人的数据库或者知识库。当对话机器人收到用户输入的信息以后,主要工作是处理信息中的关键词来生成最匹配的索引,再基于一定规则找到最匹配的答复。后来发展的对话机器人也可以利用训练数据,通过机器学习来产生答复,比如2014年的深度学习模型Seq2Seq被成功地用到了对话机器人上面。这些机器学习模型最喜欢的训练数据就是事先采集和标注好的在相同场景下(比如智能客服)的对话记录。
1、早期最有影响力的生成式AI技术是2014年发明的生成式对抗网络(Generative Adversarial Networks)
其本质是一种深度学习模型,原理上有两个神经网络相互对立,一个生成器和一个判别器。生成器或生成网络负责生成类似于源数据的新数据或内容,判别器或判别网络负责评价源数据和生成数据之间的区别并向生成器提供反馈。生成式对抗网络被成功用于计算机视觉技术,比如图像的生成和合成,但是在对话机器人技术上的成功应用并不多。
2、ChatGPT的核心是2017年出现的新生成式AI技术Transformer和随后产生的基于Transformer的大规模预训练技术,并引入了一些新的强化学习算法
其中的核心技术Transformer是2017年谷歌发明的,它来源于2017年谷歌的一篇科研论文《Attention Is All Your Need》。原本这篇论文聚焦的是自然语言处理领域,但由于其出色的解释性和计算性能,Transformer开始被广泛使用在AI各个领域和不同数据类型,成为最近几年最流行的AI算法模型。
3、在Transformer之前,主要的自然语言处理算法是RNN(循环神经网络),它的原理是每个单词(字)计算之后将结果继承给第二个单词(字)
算法的弊病是需要大量的串行计算,效率低。而且当遇到比较长的句子时,前面的信息很有可能会被稀释掉,造成模型不准确。而Transformer模型将每个句子中的所有单词进行计算,算出这个词与词之间的相关度,从而确定单词在句子里的更准确意义。Transformer模型的结果不仅仅包含了每个单词的含义、单词在句子中位置信息,更包含了词与词之间的关系和价值信息。这种方法可以在长句子中发挥优势,而且最关键的是突破了RNN时序序列的限制,所以Transformer可以用到文字图像等不同的数据。
4、Transformer的另一个巨大贡献是产生了预训练语言模型,比如GPT、BERT和ERNIE等
这些预训练语言模型用到的对语言的编码器和解码器都是由一个个的Transformer组件拼接在一起形成的。比如,预训练语言模型BERT 所做的就是从大规模上亿的无标注文本语料中,随机抠掉一部分单词,形成类似完形填空的题型,不断学习空格处到底该填写什么。BERT的训练是从大量无标注数据中学习复杂的上下文联系。BERT和GPT(Generative Pre-Training)最主要的区别在于,BERT仅仅使用编码器部分进行模型训练,GPT仅仅使用解码器部分,所以GPT更适用于生成文本。
总的来说,预训练的第一步是在大规模无标注数据(如网上文本)上进行模型预训练,学习通用的语言模式;第二步在给定自然语言处理任务的小规模有标注数据上进行模型微调,快速提升模型完成这些任务的能力,最终形成可部署应用的模型。预训练模型已经在大规模语料上训练好了参数,用户在用的时候只需要在这个基础上训练更新参数。用户可以在神经网络加的最后的一层上进行分类或者更多的语言推理任务(比如对话等)。预训练技术成功激活了深度神经网络对大规模无标注数据的自监督学习能力,而Transformer和基于它的GPT、BERT、ERNIE等模型奠定了自然语言处理领域大模型的基础,证明了通过大规模语料的预训练技术,能够大幅度提升各类文本阅读理解的效果,开启了自然语言处理的新时代。
从Transformer的提出到“大规模预训练模型”GPT和BERT的诞生,再到GPT-2的迭代,以及到GPT-3和ChatGPT的出现,标志着OpenAI成为营利性公司。ChatGPT可以说是OpenAI公司利用最新生成式AI技术(Transformer)和最新大规模预训练模型(GPT-3.5)在对话机器人上的成功应用。GPT-3的模型所采用的数据量多达上万亿,主要使用的是公共爬虫数据集和有着超过万亿单词的人类语言数据集,对应的模型参数量也达到1,750亿。另外,ChatGPT还采用了新的强化学习算法RLHF(Reinforcement Learning from Human Feedback,从人类反馈中强化学习)来对模型进行训练,具体是让一些外包人员不断从模型的输出结果中筛选,判断哪些句子是好的,哪些是低质量的,这样就可以训练得到一个强化学习中的奖励(reward)模型。
ChatGPT属于现象级应用,大家都可以有直观感受,未来这类应用的体验提升和更新速度只会更快,理解其背后的技术有助于我们把握这个趋势。从大量用户在网上分享的反馈来看,与同类对话机器人相比,ChatGPT具有几个明显的优点:
- 更有“对话”的感觉:ChatGPT在语言组织的逻辑性和系统性方面有了显著提高,感觉像是一个助理,甚至是老师在回答问题。
- 回答理性又全面:不像网上搜索问题那样,很可能碰到一些固执的回答者,只站在一个角度回答问题,ChatGPT能做到多角度全方位回答。
- 可以理解上下文:例如,在提出一个问题之后,可以用“就刚才的回答中,你指的xx到底是什么意思?”等形式,进行追问。
- 会根据用户的反馈,持续优化模型:ChatGPT答案的质量、完整性每天都有一定提高。这是新的强化学习算法和几十名外包人员每天筛选答案的贡献。
- 可以协助创作内容,甚至对计算机代码进行指导:注意,ChatGPT并不是简单地从某个模版中选择内容,而是根据实时计算的结果提供答案。你给的信息越精准,回复就越有针对性。
二、生成式AI有待改进之处
前面提到,ChatGPT的优势是基于新的生成式AI技术Transformer和大规模预训练技术,并引入了一个新的强化学习算法。ChatGPT可以实现符合基本逻辑的对话生成,并能够在较短时间里生成大量高质量的文本内容,并给予相对准确的答案和自我修正。所以ChatGPT可以根据对话而优化,具有记忆能力,可以完成连续性对话。可以说ChatGPT是现阶段全球所发布的功能最全面的生成式AI对话机器人。
ChatGPT强的是逻辑分析和语言组织能力,适合询问观点和态度。但目前ChatGPT对事实是完全不检查的,所以不适合用来查询信息,特别是在需要查询信息的对错和真实性的应用场景。ChatGPT提供的答案只能被认为是不保证100%可靠的建议。因为ChatGPT是基于大规模预训练这样的无监督学习,我们无法分辨预训练信息的来源和真实性。ChatGPT给出答案的精确度取决于预训练样本规模(目前预训练样本只限2021年之前的数据)和样本本身的准确度。OpenAI也在其官方资料中说明了ChatGPT的局限性:
- 答案可能是错误的。
- 可能会产生有害的指引或者有偏见的内容。
- 因为数据样本仅限于2021年之前,所以对于世界的认知并不全面。
为什么ChatGPT会有这些局限性呢?简单来说,ChatGPT和很多深度学习模型一样是一个概率生成模型,其回答是从一个概率分布中采样的结果。根据你的问题,有些回答的概率更高,有些较低。当然ChatGPT还会根据人类的喜好来修正权重,从而增加输出人类想要的答案的概率。即使这样,同一个人多次询问同一个问题,不一定会获得相同的答案。有些答案有可能包含错误的信息。
当然,ChatGPT的核心技术里面有强化学习的reward模型,实际上是由大量人工进行标注训练的,不是完全的无监督学习。可以说目前ChatGPT模型的某些能力上的不足,很大程度是由这个reward模型决定的。Reward模型拟合不好的地方,也成为人们观察到 ChatGPT模型不足的地方之一。另外,由于ChatGPT数据更新延迟、还需要更多学习,常无法支持时效性答案,用户及ChatGPT都需要时间逐渐去提供反馈和学习,才能逐渐获得更准确的回复和对话。
最明显待改进的地方是,由于ChatGPT处于测试阶段,其知识库还很不完善。在模型进行大规模预训练过程中,即使训练语料包含了真实的、正确的信息,但是在推理阶段,ChatGPT还是可能输出错误信息。而且这样的错误,随着大量的用户测试,会更多地暴露出来。所以很明显,ChatGPT并没有连接一个稳妥可靠的知识库,这也说明目前这个版本无法完全替代搜索引擎,而更适用于一些务虚的任务,比如写小说、写诗歌、搞辩论。我们认为给ChatGPT连接一个高质量的知识库会极大提高ChatGPT的准确性。一个可以考虑的方向是,让ChatGPT能够持续更新知识、查询知识,从而带领搜索引擎和互联网的发展。目前看来,至少ChatGPT可以做到将搜索引擎上的信息润色、组织成最适合人阅读的形式,直接反馈给用户。
三、生成式AI的商业应用
直接应用生成式AI(Generative AI )的场景是人机互动的文本、图像、语音、视频,也可以生成软件代码、音乐、虚拟世界的三维模型等,在消费领域可以用来做艺术创作、游戏开发、人员陪护等,它为商业领域里也带来很多数字化创新的机会。
企业级解决方案的创新是用户界面的变化,采用自然语言进行交互。无论是交易型应用还是分析型应用,基于AI采用自然语言进行互动的方式早有所探索,例如企业级商业智能可以采用持续的自然语言问答进行数据查询,并自动生成自然语言回答或者直观的图表;利用生成式AI可以进一步提升用户界面生成效率和质量。
能够自动用文字或语音互动,并且在互动中采撷信息输入业务系统的智能机器人早已用在企业的销售、客服、采购、报销、员工服务等流程,例如BCG开发了“智能采购助手”,采购人员在跟供应商互动中,智能助手能够从大数据中实时解析采购物资的市场信息以及供应商产能、资信等状态,结合供应商反馈和公司的采购策略、协作流程,为采购人员生成行动建议,例如价格谈判或者发送征询函等。
聊天机器人在很多业务场景下并不能完全替代人工,这种方式不仅存在AI准确性的问题,而且在用户体验上缺乏沟通的温度,然而,AI具有超越人脑的信息处理能力,可以提供辅助人员互动的智慧,支持人与人之间有温度的沟通。近年来,辅助人员互动的“对话式AI”产生了广泛商业应用,例如BCG为汽车、保险、地产等高价值销售行业开发的“智能销售助理”,不仅具有前文所述的行动计划推荐能力,而且能够实时分析销售人员的行为和话术,提出有针对性的辅导、改进建议,提升销售成功率,生成式AI进一步提升了此类智能化辅助程度。
可以预见,企业数字化应用可能会有以下变化:
- 传统AI技术学习消化的信息资源有限,通过大模型提供更为丰富的业务情景的上下文信息,加深决策的智能深度。通俗地说,普通人下棋想三步,高手下棋想五步,例如:明天我要去见哪个客户会更有助于达成我这个月的销售指标?用什么手段能降低5%的费用而不影响员工满意度?
- 实现业务流程的全自动导航,例如,根据用户反馈,通过生成式AI自动改进产品设计,这将改变传统的产品开发相关企业软件(例如PLM、CAD)的应用流程。
- 2B软件架构简化,强调前端开发,进一步实现“数字技术民主化”,降低工作中对数据、信息和知识的访问门槛,用户能够更好地使用数字化技术和AI。传统企业软件架构是应用软件访问集中的数据库,需要用代码来连接用户请求和数据,而未来数据和算法都是服务,利用生成式AI产生代码的过程将极为简化,企业软件将完全聚焦于业务运营和用户体验的持续创新。
生成式AI还将改变企业软件行业的商业生态——AI算法和工程等技术平台的开源社区蓬勃发展,利用开源技术开发基础模型越来越普遍。然而,体现企业差异化能力的是喂给AI的原料,所以数据资源的价值将更为凸显,具有独特know-how和来源的数据将成为AI背后的能力。
在ChatGPT爆火的同时,我们还需要思考负责任AI(Responsible AI)的意义和重要性,这亦是BCG关注并钻研的领域。我们认为,落实负责任的AI实践已成为企业的当务之急。BCG近期发布了两篇相关英文读物,希望能够帮助读者更好地了解和思考。
翻译:
ChatGPT on generative AI principles and commercial applications
Deep learning is a major technological breakthrough in the field of artificial intelligence since its inception in 1956. From the beginning of the new millennium, deep learning technology will see a great technological progress every five to seven years. Transformer and pre-training model in 2017/2018 are the representative examples. We are currently in the third high tide of AI technology development brought by deep learning. It is a representative product of this technological progress.
Innovation of generative AI
Recently, ChatGPT was the poster child for “Generative AI” generative AI. Unlike the traditional Chatbot, OpenAI’s ChatGPT does have a unique technological innovation that could be a milestone in the history of artificial intelligence, possibly even comparable to Google’s AIphaGo in 2016. And for now, ChatGPT seems to have a better and more widespread application prospect than AIphaGo, which could be a powerful way to continue the development of this wave of AI technology.
Let’s start by introducing how conversation robots work
First, the user needs to input a message to the dialogue robot through text or voice, then the robot will recognize and understand the message, judge the conversation task started by the message, and give the corresponding reply content. The earliest conversational robots were more like a query system based on a database or a knowledge base, which queried the corresponding answers according to the information entered by the user. It can be said that these answers are based on different indexes, which are pre-stored in the conversational robot’s database or knowledge base.
When the dialog robot receives the information input by the user, its main job is to process the keywords in the information to generate the most matched index, and then find the most matched reply based on certain rules. Later developed dialogue robots can also use training data to generate replies through machine learning. For example, the deep learning model Seq2Seq was successfully applied to dialogue robots in 2014. The favorite training data for these machine learning models is pre-collected and annotated conversations in the same scenario (such as intelligent customer service).
The most influential early Generative AI technology was Generative Adversarial Networks, invented in 2014.
It is essentially a deep learning model with two neural networks in opposition to each other, a generator and a discriminator. The generator or generating network is responsible for generating new data or content similar to the source data, and the discriminator or discriminator network is responsible for evaluating the differences between the source and generated data and providing feedback to the generator. Generative adversarial networks have been successfully used in computer vision techniques, such as image generation and synthesis, but have had limited success in conversational robotics.
The core of ChatGPT is Transformer, a new generative AI technology that emerged in 2017, and the subsequent large-scale pre-training technology based on Transformer, and the introduction of some new reinforcement learning algorithms
The core technology, Transformer, was invented by Google in 2017. It comes from a Google research paper “Attention Is All Your Need” in 2017. This paper originally focused on natural language processing, but Transformer has been widely used in various AI fields and different data types due to its excellent explanatory and computational performance, and has become the most popular AI algorithm model in recent years.
Before Transformer, the main natural language processing algorithm is RNN (recurrent neural network), which is based on the principle that each word (word) is computed and the result is inherited to the second word (word).
The disadvantage of the algorithm is that it requires a large number of serial calculations and is inefficient. In addition, when encountering a long sentence, the previous information is likely to be diluted, resulting in an inaccurate model. The Transformer model calculates all the words in each sentence and calculates the degree of correlation between the words to determine the exact meaning of the words in the sentence. The result of the Transformer model includes not only the meaning of each word and its position in the sentence, but also the relationship and value between words. This approach works well with long sentences and, crucially, transcends the limitations of RNN sequences. So Transformer can use different data such as text images.
Another great contribution of Transformer is the generation of pre-trained language models such as GPT, BERT, ERNIE, etc
The language encoders and decoders used in these pre-training language models are all stitched together by Transformer components. For example, what pre-trained language model BERT does is to randomly pick out part of words from hundreds of millions of unmarked text corpus, form questions similar to cloze, and constantly learn what to fill in the blank. BERT’s training is to learn complex contextual associations from large amounts of unlabelled data. The main difference between BERT and GPT (Generative Pre-Training) is that BERT only uses the encoder part for model training, while GPT only uses the decoder part. Therefore, GPT is more suitable for text generation.
In general,.
The first step of pre-training is to conduct model pre-training on large-scale unmarked data (such as online text) to learn general language patterns. The second step is to fine-tune the model on the small scale labeled data of a given natural language processing task, quickly improve the ability of the model to complete these tasks, and finally form the model of deployable application. The pre-training model has trained parameters on large-scale corpus. And users only need to train and update parameters on this basis when using.
Users can classify or perform more verbal reasoning tasks (such as conversations) on the last layer added by the neural network. The pre-training technology has successfully activated the self-supervised learning ability of deep neural network for large-scale unlabeled data, and Transformer and its GPT, BERT, ERNIE and other models have laid the foundation for large models in natural language processing, proving that through the pre-training technology of large-scale corpus, It can greatly improve the effect of all kinds of text reading comprehension and open a new era of natural language processing.
From the introduction of Transformer to the “mass pre-training model” GPT and BERT, to the iteration of GPT-2, to GPT-3 and ChatGPT, OpenAI became a for-profit company.
ChatGPT is a successful application of OpenAI’s new generative AI technology (Transformer) and its latest large-scale pre-training model (GPT-3.5) in conversational robots. GPT-3’s model uses up to one trillion of data, mainly using public crawler data set and human language data set with more than one trillion words. And the corresponding number of model parameters also reaches 175 billion. In addition, ChatGPT also uses the new Reinforcement Learning from Human Feedback algorithm RLHF (Reinforcement Learning from Human Feedback) to train the model. Specifically, some outsourcing personnel are constantly screened from the output results of the model. Judge which sentences are good and which are of low quality. So that you can train a reward model in reinforcement learning.
ChatGPT is a phenomenal-level app, and it’s intuitive that in the future, these apps will only improve and update faster. And understanding the technology behind it will help us grasp this trend.
Based on the feedback shared by a large number of users online, ChatGPT has several distinct advantages over comparable conversational bots:
More “conversational” feel: ChatGPT has improved significantly in the logical and systematic organization of language, feeling like an assistant or even a teacher answering questions.
Answers are rational and comprehensive: Unlike online search queries, which are likely to be met with stubborn respondents who only answer from one Angle, ChatGPT can answer from many angles.
Understand the context: For example, after posing a question. You might say “What exactly did you mean by xx in your answer?” And so on, to ask questions.
The model is continuously optimized based on user feedback: The quality and completeness of ChatGPT’s answers improve daily. This is the contribution of new reinforcement learning algorithms and dozens of outsourcers sifting through the answers every day.
You can help create content and even guide computer code: note that ChatGPT does not simply select content from a template. But rather provides answers based on the results of real-time calculations. The more precise your message, the more targeted your response will be.
Generative AI needs to be improved
As mentioned earlier, ChatGPT’s strength is based on new generative AI technology Transformer and mass pre-training technology, and introduces a new reinforcement learning algorithm. ChatGPT enables conversation generation that follows basic logic and can generate large amounts of high quality text in a relatively short time, giving relatively accurate answers and self-correction. So ChatGPT can be optimized for conversations, has memory capabilities, and can complete continuous conversations. ChatGPT is the most comprehensive generative AI conversational robot released in the world.
ChatGPT is strong in logical analysis and verbal organization. It is suitable for inquiring about opinions and attitudes. At present, however, ChatGPT does not check facts at all, so it is not suitable for querying information. Especially in application scenarios where information is true or false. The answers provided by ChatGPT can only be considered advice that is not guaranteed to be 100% reliable. Because ChatGPT is based on unsupervised learning such as mass pre-training. We cannot tell the source and authenticity of pre-training information. The accuracy of ChatGPT’s answers depends on the size of the pre-training sample (currently available only before 2021) and the accuracy of the sample itself.
OpenAI also explains ChatGPT’s limitations in its official documentation:
1. The answer may be wrong.
2. Harmful guidance or biased content may be generated.
3. Because the data sample is only before 2021, the understanding of the world is not comprehensive.
Why does ChatGPT have these limitations? Simply put, ChatGPT, like many deep learning models, is a probabilistic generation model whose answers are sampled from a probability distribution. Depending on your question, some have a higher probability of being answered, and some have a lower probability. Of course, ChatGPT also adjusts the weights to suit the human’s preferences, increasing the probability of delivering the answer the human wants. Even so, the same person asking the same question many times may not get the same answer. Some answers may contain incorrect information.
Of course, ChatGPT’s core technology includes a reward model for reinforcement learning, which is actually trained by a large number of humans, not completely unsupervised learning.
It can be said that some of the limitations of the current ChatGPT model are largely determined by this reward model. Where the Reward model does not fit well. It is also one of the areas where the ChatGPT model is observed to be inadequate. In addition, since ChatGPT data update is delayed and requires more learning, time-sensitive answers are often not supported. Users and ChatGPT need time to provide feedback and learn gradually. So that they can gradually get more accurate responses and conversations.
The most obvious area for improvement is that since ChatGPT is in beta, its knowledge base is far from complete. In the large-scale pre-training process of the model, even though the training corpus contains true and correct information, ChatGPT may still output error information in the reasoning stage. And such errors, with a lot of user testing, will be more exposed. So it’s clear that ChatGPT isn’t connected to a solid repository of knowledge,. Which means that the current version isn’t a complete replacement for search engines. And is more suitable for mundane tasks like writing fiction, poetry, and debate.
We believe that connecting ChatGPT to a high-quality knowledge base will greatly improve ChatGPT’s accuracy. One way to look at ChatGPT is to make it possible to continually update and query knowledge, leading to the development of search engines and the Internet. At the very least, ChatGPT seems to be able to polish and organize information from search engines into the most human-readable form and feed it directly to users.
Commercial application of generative AI
The scene directly applied to Generative AI is the human-computer interaction of text, image, voice and video. As well as the generation of software code, music, 3D models of the virtual world, etc. In the consumer field, it can be used for art creation, game development, human care, etc. It also brings many digital innovation opportunities for the commercial field.
Innovation in enterprise-class solutions is a change in user interface that uses natural language for interaction. Whether transactional or analytical applications, AI-based interaction with natural language has long been explored. For example, enterprise business intelligence can use continuous natural language questions and answers for data query. And automatically generate natural language answers or intuitive charts. Using generative AI can further improve the efficiency and quality of user interface generation.
Intelligent robots that can automatically interact with text or voice and gather information into the business system have long been used in the process of sales, customer service, procurement, reimbursement and employee service of enterprises. For example, BCG has developed “Intelligent purchasing Assistant”. In the interaction between purchasing staff and suppliers. The intelligent assistant can analyze the market information of purchased materials and the production capacity and credit status of suppliers in real time from the big data, and combine the feedback of suppliers with the company’s procurement strategy and cooperation process to generate action suggestions for the purchasing staff, such as price negotiation or sending consultation letters.
Chatbots cannot completely replace human beings in many business scenarios.
This approach not only has problems with the accuracy of AI, but also lacks the temperature of communication in terms of user experience. However, AI has the information processing ability beyond the human brain. Which can provide wisdom to assist human interaction and support warm communication between people. In recent years, the “conversational AI” to assist personnel interaction has been widely used in business. For example, the “intelligent sales assistant” developed by BCG for high-value sales industries. Such as automobile, insurance and real estate not only has the ability to recommend action plans as mentioned above. But also can real-time analyze the behavior and speech of sales personnel, and put forward targeted guidance and improvement suggestions. To improve sales success rate, generative AI further improves the degree of such intelligent assistance.
It can be predicted that enterprise digital application may have the following changes:
1. Traditional AI technology learns and digests limited information resources, and provides richer contextual information of business scenarios through large models to deepen the intelligent depth of decision-making. In plain English, the average person thinks of three moves in chess, while the best player thinks of five. For example: Which client will I see tomorrow that will help me achieve my sales target this month? What can be done to reduce costs by 5% without affecting employee satisfaction?
2. The realization of fully automated navigation of business processes, for example, automatic improvement of product design through generative AI based on user feedback, will change the application process of traditional enterprise software related to product development (e.g. PLM, CAD).
3. 2B software architecture is simplified, emphasizing front-end development, further realizing the “democratization of digital technology”, lowering the threshold of access to data, information and knowledge at work, and enabling users to better use digital technology and AI. In traditional enterprise software architecture, application software accesses centralized database and needs to use code to connect user requests and data, while in the future, data and algorithms are services, and the process of using generative AI to generate code will be extremely simplified. Enterprise software will completely focus on continuous innovation of business operation and user experience.
Generative AI will also change the business ecology of the enterprise software industry — the open source community for technology platforms such as AI algorithms and engineering is thriving, and the use of open source technologies to develop basic models is becoming more common. However, it is the raw materials that are fed to the AI that reflect the differentiation ability of the enterprise. So the value of data resources will be more prominent. Data with unique know-hows and sources will become the capabilities behind the AI.
Conclusion
While ChatGPT goes viral, we also need to think about the significance and importance of Responsible AI, an area that BCG is focusing on and studying. We believe that implementing responsible AI practices has become a top priority for enterprises. BCG recently published two relevant English books, hoping to help readers better understand and think.
本文由数字化转型网(www.szhzxw.cn)转载而成,来源:BCG波士顿咨询;编辑/翻译:数字化转型网宁檬树。

免责声明: 本网站(http://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。