

人工智能(AI)技术是数字经济的核心驱动力。各国政府均在布局 AI 领域的全栈能力,并出资引导建设智能算力基础设施。我国也已进入智能化时代。“十四五”期间,各部委积极推动智能计算中心(简称智算中心)的建设和发展,旨在为 AI 应用提供公共算力服务。智算中心是以 GPU 等智能计算芯片为核心、集约化建设的新型算力基础设施,提供软硬件全栈环境,主要承载模型训练、集中推理和多媒体渲染等业务,支撑各行业数智化转型升级。
一、AI 大模型
生成式人工智能(AIGC)可谓是现阶段最热门的AI 大模型。AIGC 的前身是 OpenAI 公司发布的通用人工智能网络 GPT3,拥有 1 750 亿个参数量和 45 TB的预训练数据量,其后基于 GPT3 发布商业化产品ChatGPT。ChatGPT 可以回答问题、写诗、作词,甚至可以创作论文、音乐和电视剧等,在部分领域的能力甚至超越人类的基准水平。 数字化转型网(www.szhzxw.cn)
AI 大模型计算主要包含模型预训练、模型微调和模型推理 3 个步骤。模型预训练阶段进行算法架构搭建,基于大数据集对模型进行自监督式训练,生成基础大模型 ;模型微调阶段基于小数据集和 RLHF 等对模型进行调优和对齐,生成行业大模型或垂类模型 ;模型推理阶段基于用户调用需求,输出计算结果。
GPT 类 AI 大模型属于大规模语言模型,参数量巨大,对算力的需求呈指数级的增长。训练模型所需的时间与消耗的资源成反比,训练时长越短,所需消耗的资源量越大。据估算,3 个月内训练出一个 GPT3 模型,需要消耗 3 000 多张单卡算力不小于 300 TFLOPS(半精度 FP16)的 GPU 卡,而如果想在 1 个月内训练出GPT3 模型,则需要 10 000 多张同类型 GPU 卡。同时,推理此类模型也无法在 1 张 GPU 卡进行,最少需要 8卡同时进行推理才能保证延迟在 1 秒以内。
随着语言类模型的大获成功,相关技术方法被引入图像、视频和语音等多个应用场景。如构建用于目标检测和图像分类等的视觉类大模型,可广泛应用于自动驾驶和智慧城市等领域。多模态大模型可以同时覆盖众多场景,与此同时,参数规模进一步迅速增长,可达百万亿级别,对智算中心的算力、数据和网络等能力提出了更高的要求。
二、智能计算芯片选型分析
GPU 芯片按形态可以分为 PCIe 标卡和扣卡模组两种。两种形态的 GPU与 CPU之间通信均通过 PCIe总线。CPU 会参与训练中的数据集加载和处理等工作,主要差异在于 GPU 的卡间通信方式和卡间互联带宽不同。
对于大多数标准的服务器来讲,受服务器 PCIe 总线设计和插槽数量的限制,通常 1 台服务器内部最多可以部署 8 张 GPU 芯片。 数字化转型网(www.szhzxw.cn)
1. PCIe 标卡
采用 PCIe 标卡形态的 GPU 芯片,服务器内部 8 卡之间通过 PCIe Switch 进行连接。PCIe Switch 是一种用于拓展 PCIe 接口的芯片,可以实现 1 个 PCIe 接口对接多个 PCIe 设备,1 台部署 8 张 GPU 卡的服务器,1 个 PCIe Switch 可以对接 4 张 GPU 卡,服务器设置 2 个 PCIe Switch 可以实现 8张卡的互联通信。采用 PCIe 4.0 协议,卡间双向带宽为 64 Gbit/s ;采用 PCIe 5.0 协议,卡间双向带宽为 128 Gbit/s。具体卡间通信方式根据业务场景和部署的模型不同,有 3 种模式可选,具体如图 1 所示。

第 1 种为均衡模式。PCIe Switch 分别通过 2 个 CPU 进行连接,远端 GPU 卡之间通过 PCIe Switch 跨 CPU 进行通信。这种模式下,CPU 利用率最大化,可以提供更大的上行链路带宽,但远端卡间通信受限于 CPU 之间的 UPI 通信带宽。均衡模式可以保证每个 GPU 的性能均衡,适用于公有云场景,以及 CPU 和 GPU 同时参与任务的算法模型,如 Inception3 等。
第 2 种 为 普 通 模 式。PCIe Switch 通 过 同 一 个CPU 进行连接,远端 GPU 卡之间无需跨 CPU 之间进行 UPI 通信,可以提供较大的点对点卡间带宽,并且 CPU 到 GPU 之间有 2 条 PCIe 通道,吞吐量高。普通模式可以提供较好的 GPU 与 CPU 之间的通信性能,适用于 CPU 参与较多任务的通信密集型算法模型,如Resnet101 和 Resnet50 等。 数字化转型网(www.szhzxw.cn)
第 3 种为级联模式。PCIe Switch 不通过 CPU 直接连接,远端 GPU 卡之间直接通过 PCIe Switch 级联通信,点对点卡间带宽最大,但 CPU 到 GPU 之间只有 1 条 PCIe 通道,吞吐量相对较小。级联模式可以为大参数量模型提供最优的点对点卡间通信性能,适用于CPU 参与较少任务的计算密集型算法模型,如 VGG-16 等。
PCIe 标卡服务器机型主要用于单机单卡或单机多卡训练场景。3 种卡间通信模式支持按需配置,对 CPU核心数和虚拟化要求较高的云化场景通常选用均衡模式。在分布式训练场景下,不同算法模型选用合适的通信模式可获得最优的 GPU 线性加速比,在有限条件下可实现 GPU 卡的最大化利用。
2. 扣卡模组
采用扣卡模组形态的 GPU 芯片,服务器内部的 8张卡集成在 1 块基板上,GPU 卡间可以实现端到端全互联。扣卡模组服务器机型搭配外部的高速互联网络可有效满足大规模的多机多卡并行训练任务。
扣卡模组基板主要分为 SXM 和 OAM 两种标准。SXM 是独家私有标准,需要配合私有的 NVLink 接口实现卡间高速互联 ;OAM 是开放模组标准,对外提供标准接口,打破对独家的供应依赖。OAM 提供的接口具有高度灵活性,卡间互联可有多个变种拓扑结构。 数字化转型网(www.szhzxw.cn)
(1)SXM 扣卡模组
NVLink 是为解决 PCIe 总线带宽限制提出的一种 GPU 互连总线协议。目前 NVLink协议演进到第 4 代,每张 GPU 最大支持 18个 NVLink 连接,GPU 卡之间双向带宽可达900 Gbit/s。
PCIe 标卡服务器可通过选配 NVLink 桥接器,实现相邻 2 张卡之间的高速互联,采用桥接器可实现的最高双向带宽为 600 Gbit/s。但 NVLink 桥接器无法实现服务器内部所有 GPU 卡之间的全互联,在大模型训练场景下仍无法满足多机多卡之间的并行通信需求。采用 NVLink 桥接器的卡间互联架构示意如图 2 所示。

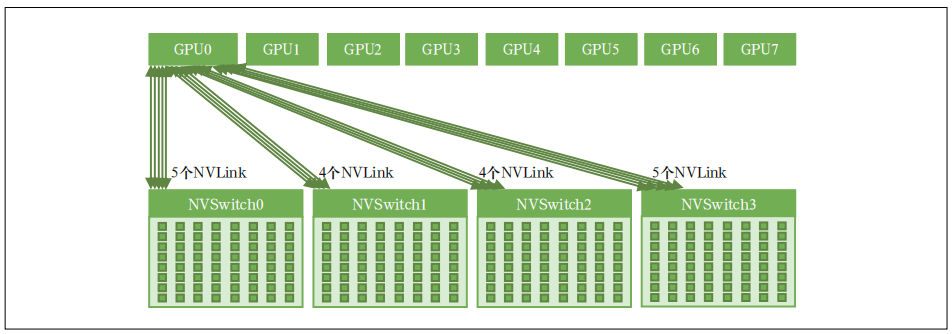
SXM 扣卡模组是芯片厂商自有设计标准,基板不仅集成了 8 张 GPU 卡,同时还集成了 NVSwitch 芯片,每个 NVSwitch(第 4 代)都有 64 个 NVLink 网络端口,可以将 8 张 GPU 卡全部连接起来,是实现 8 卡之间端到端全互联的关键组件。卡间互联架构示意如图 3 所示。
(2)OAM 扣卡模组
OAM 是开源组织 OCP 定义的用来指导 GPU 模组系统设计的标准。其对标 SXM 模组,可以帮助 GPU服务器实现更好的类似 NVLink 的卡间互联通信。目前国产 GPU 服务器普遍采用 OAM 扣卡模组形态。
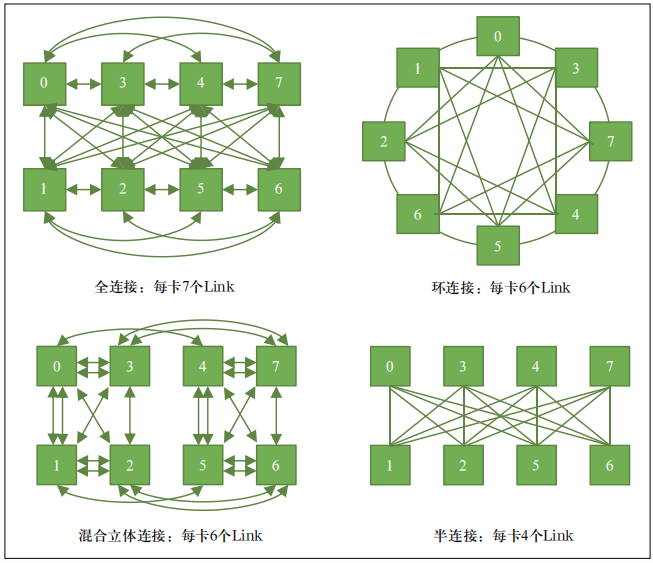
OAM 标准定义了 GPU 服务器内部的扣卡模组、主板、机箱、供电、制冷、I/O 交互和系统管理等一系列规范。不同厂商设计的扣卡模组只要符合 OAM 标准,卡间互联通信有多种方案可以灵活选择。典型的有全连接、混合立体连接、环连接和半连接等。卡间互联架构示意如图 4 所示。OAM除了需要考虑卡间互联链路以外,还需要同步考虑与 CPU、网卡等部件的连接,以及预留对外的扩展端口。全连接是未来趋势,但当前国产 GPU 芯片产品设计定位和方式不同,多采用混合立体连接和半连接方式。
当前,AI 大模型逐步由单模态向多模态转变,涉及视觉问答、情感分析、跨媒体检索和生成任务等多种应用场景。多模态模型算法更加复杂、数据规模更加庞大。扣卡模组形态的 GPU 芯片,卡间互联通信不受 PCIe 接口带宽限制,可提供更高的卡间带宽和更低的传输时延,在多模态大模型训练应用中可以提供更出色的性能。
三、智能计算服务器散热选型分析
扣卡模组机型和 PCIe 标卡机型的整机服务器散热方式选型需结合服务器功耗情况、内部构造特点和服务器整机厂家支持情况综合决定。
首先,扣卡模组机型功耗较高,PCIe 标卡机型功耗相对较低,配置 8 卡的扣卡模组机型整机功耗约为7 ~ 11 kW,而 PCIe 标卡机型整机功耗约为 3 ~ 4 kW。其次,扣卡模组插卡在同一个平面上,更适合冷板结构设计,而 PCIe 标卡采用独立竖插方式,每个插卡需要单独设计冷板,且冷板间互联结构复杂。另外,从厂家支撑情况来看,扣卡模组机型整机服务器厂家大多具备液冷方案,而 PCIe 标卡机型的整机服务器厂家液冷方案较少。 数字化转型网(www.szhzxw.cn)
液冷散热方式又分为冷板式液冷和浸没式液冷两种,具体差异见表 1。
表1 服务器液冷选型对比
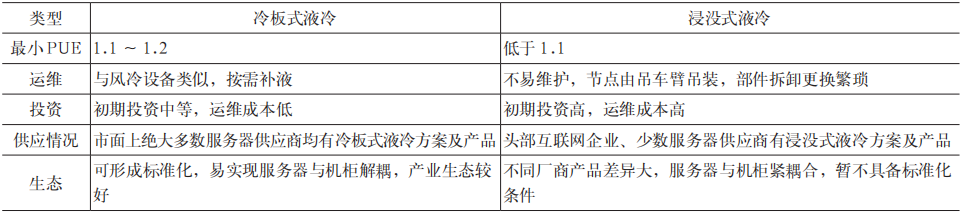
相较浸没式液冷技术,当前冷板式液冷在初始投资成本、网络运维模式、生态成熟度、机房改造难度和工程实施进度等方面更具有优势。
同时,冷板式液冷服务器存在整机柜交付和服务器与机柜解耦交付两种方式,具体差异见表 2。
表2 冷板式液冷机柜交付方式对比

考虑液冷技术特点、竞争生态和运维界面等问题,在尚未建立机柜解耦标准的情况下,更适合选择整机柜交付方式。
综上分析,PCIe 标卡机型采用风冷散热方式即可满足使用需求,使用数据中心通用机柜安装,无需整机柜配置。扣卡模组机型需采用液冷散热方式,结合当前技术和生态情况,优选冷板式液冷和整机柜交付模式。 数字化转型网(www.szhzxw.cn)
四、结束语
智算中心在大模型训练、AI+ 视频、自动驾驶和智慧城市等业务场景都有较大的智能算力需求和发展空间。目前国内智算中心建设如火如荼,全国有 30 多个城市已建成或正在建设智算中心。但建设智算中心与传统云计算平台不同,在计算、存储、网络、应用、平台等各方面都有较高要求和挑战,后续将持续关注并研究智算全栈技术,为建设技术领先、绿色节能、服务全局的大型智算中心提供可行性方案。

翻译:
Selection analysis of intelligent computing technology in AI large model scenario
Artificial intelligence (AI) technology is a core driver of the digital economy. Governments are laying out full stack capabilities in the field of AI, and funding to guide the construction of intelligent computing infrastructure. China has also entered the era of intelligence. During the “14th Five-Year Plan” period, various ministries and commissions actively promoted the construction and development of intelligent computing centers (referred to as intelligent computing centers), aiming to provide public computing services for AI applications. The intelligent computing center is a new intensive computing infrastructure with GPU and other intelligent computing chips as the core. It provides a full-stack environment for hardware and software, mainly carries model training, centralized reasoning, multimedia rendering and other services, and supports the transformation and upgrading of digital intelligence in various industries.
First, AI large model
Generative Artificial Intelligence (AIGC) is the most popular AI model at this stage. AIGC is the predecessor of OpenAI’s general artificial intelligence network GPT3, with 175 billion references and 45 terabytes of pre-training data, followed by the release of ChatGPT, a commercial product based on GPT3. ChatGPT can answer questions, write poems and lyrics, and even compose essays, music and TV dramas, surpassing human standards in some areas.
AI large model calculation mainly includes three steps: model pre-training, model fine-tuning and model inference. In the pre-training stage, the algorithm architecture is built, and the self-supervised training of the model is carried out based on the big data set to generate the basic large model. In the model fine-tuning stage, the model is optimized and aligned based on small data sets and RLHF, etc., and the industry large model or vertical model is generated. The model inference stage outputs the calculation result based on the user’s call requirements.
GPT AI large model belongs to the large-scale language model, the number of parameters is huge, and the demand for computing power is increasing exponentially. The time required to train the model is inversely proportional to the resources consumed, and the shorter the training time, the greater the amount of resources required to be consumed. It is estimated that training a GPT3 model within 3 months needs to consume more than 3,000 GPU cards with a single card computing power of not less than 300 TFLOPS (semi-precision FP16), and if you want to train a GPT3 model within 1 month, you need more than 10,000 GPU cards of the same type. At the same time, reasoning such models cannot be performed on one GPU card, and at least eight cards need to be inferred at the same time to ensure that the latency is less than 1 second. 数字化转型网(www.szhzxw.cn)
With the great success of language class model, related technology methods are introduced into many application scenarios such as image, video and speech. For example, building large visual models for object detection and image classification can be widely used in fields such as autonomous driving and smart cities. The multi-modal large model can cover many scenes at the same time, and at the same time, the parameter scale has further grown rapidly, reaching the level of 100 trillion, which puts higher requirements on the computing power, data and network capabilities of the intelligent computing center.
Second, intelligent computing chip selection analysis
GPU chips can be divided into PCIe standard cards and card modules. The communication between the GPU and CPU in the two modes is through the PCIe bus. The CPU will participate in the data set loading and processing in the training, and the main difference is that the communication mode between GPU cards and the interconnection bandwidth between cards are different.
For most standard servers, limited by the PCIe bus design and the number of slots, a server can deploy a maximum of eight GPU chips. 数字化转型网(www.szhzxw.cn)
1. Standard PCIe card
A GPU chip in the form of a standard PCIe card is used. The eight cards in the server are connected to each other through the PCIe Switch. PCIe Switch is a chip used to expand PCIe ports. One PCIe port can connect to multiple PCIe devices. A server with eight GPU cards can connect to one PCIe Switch with four GPU cards. Two PCIe switches on a server enable eight cards to communicate with each other. The PCIe 4.0 protocol provides 64 Gbit/s bidirectional bandwidth between cards. The PCIe 5.0 protocol provides 128 Gbit/s bidirectional bandwidth between cards. Based on different service scenarios and deployment models, three modes of inter-card communication are available, as shown in Figure 1.
Figure 1 Communication mode between remote cards of a standard PCIe card
The first is the equilibrium mode. PCIe switches are connected to two cpus. Remote GPU cards communicate with each other across cpus through PCIe Switches. In this mode, the CPU utilization is maximized and the uplink bandwidth is larger. However, the communication between remote cards is limited by the UPI communication bandwidth between cpus. The balancing mode ensures balanced performance of each GPU and applies to public cloud scenarios and algorithm models, such as Inception3, in which cpus and Gpus participate in tasks.
The second type is general mode. The PCIe Switch is connected to the same CPU and does not require cross-CPU UPI communication between remote GPU cards. The PCIe Switch provides a large point-to-point card bandwidth and provides two pcie channels between cpus and Gpus for high throughput. The common mode can provide better communication performance between the GPU and the CPU, and is suitable for the communication intensive algorithm model where the CPU participates in more tasks, such as Resnet101 and Resnet50.
The third type is cascade mode. The PCIe Switch is not directly connected to the CPU. Remote GPU cards are connected to each other through the PCIe Switch. The bandwidth between point-to-point cards is the largest, but there is only one PCIe channel between the CPU and GPU, and the throughput is relatively small. The cascading mode can provide the best point-to-point communication performance for the large parameter number model, and is suitable for computation-intensive algorithm models with less CPU involvement, such as VGG-16.
The standard PCIe card server is mainly used in single-card or multi-card training scenarios. The three inter-card communication modes can be configured on demand. The balanced mode is usually used in cloud scenarios that require high CPU cores and virtualization. In the distributed training scenario, the optimal GPU linear acceleration ratio can be obtained by selecting appropriate communication modes for different algorithm models, and the maximum utilization of GPU cards can be realized under limited conditions. 数字化转型网(www.szhzxw.cn)
2. Card module
The GPU chip in the form of a card module is used. Eight cards in the server are integrated on one substrate, and the GPU cards can be fully interconnected end-to-end. Card module server models with external high-speed interconnection network can effectively meet the large-scale multi-machine and multi-card parallel training tasks.
The card module substrate mainly includes SXM and OAM standards. SXM is an exclusive private standard, which needs to be combined with a private NVLink interface to achieve high-speed interconnection between cards. OAM is an open module standard that provides a standard interface to the outside world, breaking the dependence on exclusive supplies. The interface provided by OAM is highly flexible, and the interconnection between cards can have multiple topologies.
(1) SXM card module
NVLink is a GPU interconnect bus protocol proposed to solve the bandwidth limitation of PCIe bus. At present, the NVLink protocol has evolved to the 4th generation, and each GPU supports a maximum of 18 NVLink connections, and the two-way bandwidth between GPU cards can reach 900 Gbit/s.
A standard PCIe card server can be configured with an NVLink bridge to implement high-speed interconnection between two adjacent cards. The bridge provides a maximum bidirectional bandwidth of 600 Gbit/s. However, NVLink bridge can not realize the full interconnection between all GPU cards inside the server, and still can not meet the parallel communication needs between multiple machines and multiple cards in large model training scenarios. The interconnection architecture of cards using NVLink bridge is shown in Figure 2. 数字化转型网(www.szhzxw.cn)
Figure 2 Schematic diagram of the interconnection architecture between PCIe standard cards using NVLink bridge
The SXM card module is a chip manufacturer’s own design standard. The base board not only integrates eight GPU cards, but also integrates NVSwitch chips. Each NVSwitch (4th generation) has 64 NVLink network ports, which can connect all eight GPU cards. It is a key component to achieve full end-to-end interconnection between 8 cards. The interconnection architecture between cards is shown in Figure 3.
Figure 3 Schematic diagram of the interconnection between SXM modules
(2) OAM module
OAM is a standard defined by the open source organization OCP to guide the design of GPU module systems. Its benchmark SXM module can help GPU servers achieve better inter-card communication similar to NVLink. At present, domestic GPU server generally adopts OAM module form.
The OAM standard defines a series of specifications for GPU server modules, motherboards, chassis, power supply, cooling, I/O interaction, and system management. As long as the card modules designed by different manufacturers meet the OAM standard, there are many schemes for inter-card communication. The typical ones are full connection, mixed stereoscopic connection, ring connection and half connection. The interconnection architecture between cards is shown in Figure 4. In addition to the interconnection links between cards, the OAM also needs to consider the connection to cpus, network adapters, and reserved external expansion ports. Full connection is the future trend, but the current design positioning and methods of domestic GPU chip products are different, and most of them use hybrid three-dimensional connection and semi-connection.
Figure 4 Schematic diagram of interconnection between OAM modules
At present, AI large models are gradually changing from single mode to multi-mode, involving a variety of application scenarios such as visual question answering, sentiment analysis, cross-media retrieval and generation tasks. The multimodal model algorithm is more complex and the data scale is larger. The GPU chip in the form of a card module can provide higher inter-card bandwidth and lower transmission delay without restriction of PCIe interface bandwidth, and can provide better performance in multi-mode large-model training applications.
Third, intelligent computing server heat dissipation selection analysis
The server heat dissipation mode of the controller card module model and PCIe standard card model must be determined based on the server power consumption, internal structure features, and server manufacturer support. 数字化转型网(www.szhzxw.cn)
First of all, the power consumption of the controller card module is high, and the power consumption of the PCIe standard card model is relatively low. The power consumption of the controller card module model with 8 cards is about 7 to 11 kW, and the power consumption of the PCIe standard card model is about 3 to 4 kW. Secondly, the card module is inserted on the same plane, which is more suitable for the cold plate structure design. The PCIe standard card uses an independent vertical insertion mode, and each card needs to be designed separately for cold plates, and the interconnection structure between cold plates is complex. In addition, from the perspective of manufacturer support, most server manufacturers of card module models have liquid cooling solutions, while the server manufacturers of PCIe standard card models have fewer liquid cooling solutions.
The cooling method of liquid cooling is divided into two types: cold plate liquid cooling and submerged liquid cooling, the specific differences are shown in Table 1.
Table 1 Comparison of server liquid cooling selection
Compared with the submerged liquid cooling technology, the current cold plate liquid cooling has more advantages in initial investment cost, network operation and maintenance mode, ecological maturity, room renovation difficulty and project implementation schedule.
At the same time, the cold-plate liquid cooled server can be delivered by whole cabinet and decoupled server and cabinet. The specific differences are shown in Table 2.
Table 2 Comparison of delivery modes of slate-type liquid-cooled cabinets
Considering the characteristics of liquid cooling technology, competition ecology and operation and maintenance interface, it is more suitable to choose the whole cabinet delivery mode when the cabinet decoupling standard is not established.
In summary, PCIe standard cards can be installed in a common cabinet in the data center using air cooling and heat dissipation. The controller card module must use the liquid cooling cooling mode. Based on the current technical and ecological conditions, the cold-plate liquid cooling and whole-cabinet delivery modes are preferred. 数字化转型网(www.szhzxw.cn)
Fourth, concluding remarks
The intelligent computing center has a large demand and development space for intelligent computing power in large model training, AI+ video, autonomous driving and smart city and other business scenarios. At present, the construction of intelligent computing centers in China is in full swing, and more than 30 cities across the country have built or are building intelligent computing centers. However, the construction of intelligent computing center is different from the traditional cloud computing platform, which has higher requirements and challenges in computing, storage, network, application, platform and other aspects. In the future, we will continue to pay attention to and study the full-stack technology of intelligent computing, and provide feasible solutions for the construction of a large-scale intelligent computing center with leading technology, green energy saving and overall service.
本文由数字化转型网(www.szhzxw.cn)转载而成,来源于新工业网;编辑/翻译:数字化转型网宁檬树。
免责声明: 本网站(https://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。


