
数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入!

专题导读
当前,新一代人工智能(AI)技术蓬勃兴起,同时与大数据、区块链、云计算等技术融合,应用于社会各个领域,给人类生产、生活带来了深刻变化,为经济社会尤其是数字经济发展注入新动能。基于此,洞见特推出人工智能专题。 数字化转型网www.szhzxw.cn
随着互联网的普及和大数据的蓬勃发展,各大企业的云服务不断扩张,其所涉数据量与计算需求呈爆发式增长。但企业采用的原有Hadoop架构,即计算(查询解析、查询优化等)与存储(数据持久化、备份、故障恢复等)在物理层面上紧密耦合的模式,逐渐显现出存储与计算性能相互制约、资源相互竞争等问题。存算分离为各企业的海量数据分布式存储和计算提供新的思路,本文将围绕存算分离概念、支撑技术、业内应用和农业银行场景探索等方面展开探讨。
一、引言
人工智能服务平台(AI平台)是服务于农业银行数据分析师的一站式人工智能平台,采用存算耦合的Hadoop+Spark技术架构,集中支持所有数据分析类项目,承载分析师自助数据探索、机器学习建模与训练、MLOps三大类业务需求场景。随着农业银行数字化转型的不断深入,其所涉数据存储与计算需求呈爆发式增长,且计算需求增长更为迅速。但原有Hadoop基础架构不利于单方面进行计算或存储资源的扩展,存在存储与计算性能相互制约、资源相互竞争、资源难以快速弹性扩展、系统调度性能低、运维成本高和多租户支持能力较差等一系列问题。基于此,AI平台尝试采用存算分离的思想进行架构设计。
计算存储分离是一种分层结构设计思想,将计算能力与存储能力封装成独立的服务,相互之间的数据通过高速网络进行传输。存算分离架构具有以下优点:一是用户可针对计算或存储不足的问题,单独进行扩展,提高资源使用效率;二是计算集群出现异常时,可单独进行集群维护,降低运维成本;三是计算负载上云后,可借助K8s的名称空间和HDFS Space Quota等逻辑方式进行租户配额管理,更贴近大数据发展趋势。 数字化转型网www.szhzxw.cn
二、存算分离技术剖析
计算存储分离的理论概念出现很早,但是受限于网络带宽,大数据发展初期业界大多使用计算存储耦合的设计思想,这种设计思想采取了“移动计算到存储”的方式来减少数据在运算节点间的移动,通过运算的本地化来节约网络通信开销。
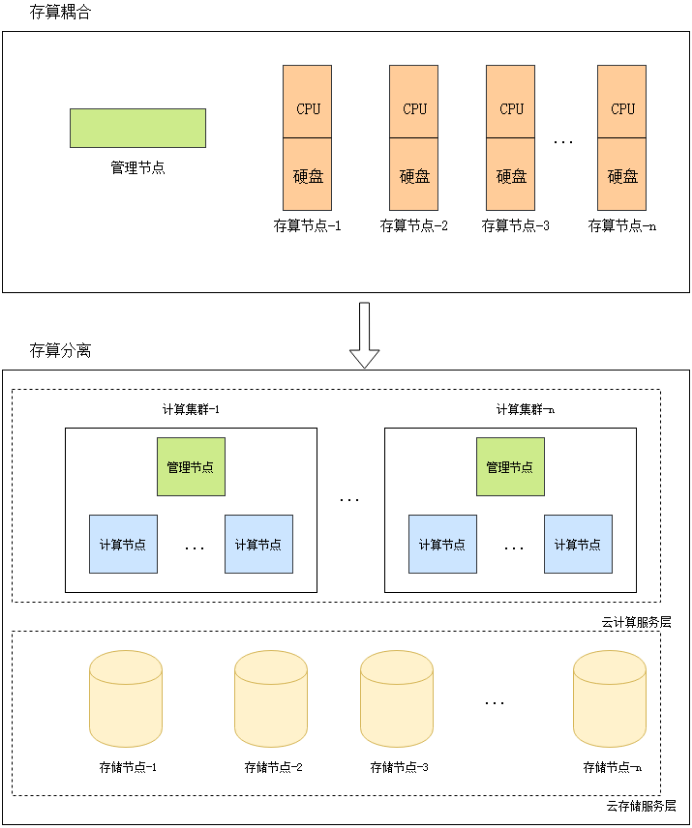
传统的的大数据分布式架构存在机器浪费、机器配比频繁更新、扩展周期长和运维成本高等问题,而云计算时代对大数据分布式架构提出了更高要求。近年来,随着局域网技术的快速发展,集群中网络IO能力远超普通磁盘IO能力,这一变化为分布式系统设计的革新提供了新的可行路线,很多基础结构向计算和存储分离这一方向重新开始发展。新模式下的存算分离具有计算存储资源按需扩展、系统更加强壮、多租户支持更完善等优点。如图1所示,对Hadoop服务进行计算存储分离,将计算层无状态上云,统一集中管理存储层,可充分提升系统灵活性、降低运维成本。
1. Spark
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。自2010年开源以来,Spark逐渐形成一个高速发展且应用广泛的生态系统,吸引来自全球570多个地区超过1600余名贡献者参与开发。其使用内存优化、查询优化等特性,可对任何规模的数据进行快速查询分析。
Spark提出基于RDD的一系列解决方案,将MapReduce、Streaming、SQL、Machine Learning、Graph Processing等算法统一在同一平台下,对外提供统一API信息,具有高效性、易用性、通用性和兼容性等优势。 数字化转型网www.szhzxw.cn
随着Kubernetes(K8s)社区的不断发展扩大,各大公司逐渐在业务生产环境中应用微服务、容器化等相关技术。大数据社区在容器化进程中也紧跟技术发展潮流,Spark 3.x正式在业务生产环境中集成K8s,通过K8s动态编排Spark计算资源,隔离不同用户信息。Spark与K8s的结合应用为计算层上云、存算分离架构设计、多租户设计等提供可行技术方案。
2. Alluxio
Alluxio是一个开源的基于内存的分布式存储系统,诞生于AMP实验室,并于2013年4月开源。Alluxio现已成为开源社区中成长最快的大数据开源项目之一,已经吸引超过300个组织结构的1000多名贡献者参与到Alluxio的开发中,包括阿里巴巴、百度、CMU、Google、IBM、Intel、南京大学、Red hat、腾讯和雅虎等。 数字化转型网www.szhzxw.cn
在大数据生态系统中,Alluxio位于数据驱动框架(如Apache Spark、Presto、Tensorflow、Pytorch、Hadoop MapReduce或Apache Flink等)和存储系统(如Amazon S3、Google Cloud Storage、 HDFS、NFS和Alibaba OSS等)之间,统一了存储在这些不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端API和全局命名空间。
Alluxio作为存算分离架构栈核心技术之一,对于多数据源信息的获取,可借助alluxio进行统一访问,简化数据访问操作。此外,对于Spark Shuffle计算过程中产生的临时数据,Alluxio提出云端缓存的策略,将临时数据缓存到计算层节点中,避免对网络、HDFS等资源的占用。具有内存速度I/O优化、简化云存储和对象存储接入、应用程序部署容易等优势。
3. Kubernetes(K8s)
Kubernetes(K8s)是一个可移植的、可扩展的开源平台,是为容器服务而生的一个可移植容器的编排管理工具。自2014年6月开源以来,K8s在众多厂商和开源爱好者的共同努力下迅速崛起,时至今日,已成长为容器管理领域的事实标准,极大推动了云原生领域的发展。K8s提供一个可弹性运行分布式系统的框架,可随时满足用户的扩展、故障转移和部署模式等需求;为用户提供服务发现和负载均衡、存储编排、自动部署和回滚、自动完成装箱计算、自我修复和密钥与配置管理等高保障服务。
在存算分离架构设计中,可将计算资源以无状态服务形式上云,通过K8s对其进行资源编排,具有快速扩展、自动部署、回滚等特性。K8s通过namespace可对计算资源进行逻辑隔离,为平台多租户设计提供可行技术方案。存储层资源则统一依托于大数据存储基础设施,由平台方进行维护。
Spark计算引擎以无状态服务上云,统一由K8s进行调度、编排。对于异构分布式存储的统一管理问题,可借助alluxio进行统一访问,简化数据访问操作。利用以上三种关键技术,可将计算层与存储层完全分离,各自作为独立的模块为用户提供服务。新模式下的架构设计具有计算存储资源弹性扩展、更优资源隔离和多租户设计等优势,在各行业都有巨大的应用前景。
三、存算分离在行业中的应用
存算分离架构思想可以让大数据集群充分利用资源,实现弹性扩展,更贴近云计算主流趋势,在业内有广泛的应用,腾讯、阿里、工商银行、中国联通等公司均已落地相关成功案例。
中国工商银行联合华为FusionInsight MRS落地大数据存储计算分离解决方案,实现了大数据平台与OBS对象存储服务的对接,将原有的Hadoop分布式文件系统HDFS接入到OBS中,实现了计算与存储分离架构。计算层与存储层进行按需扩充,轻松应对业务数据爆发式增长浪涌。实现资源价值的最大化、存储计算层全面云端化、灵活配置、降本增效。
中国联通联合华为OceanStor Pacific系列产品落地大数据存算分离解决方案,在存储层构建原生HDFS能力,将存储从服务器本地盘剥离,实现了计算与存储分离架构,具备节约成本、运营效率提升、提升可靠性等优点。 数字化转型网www.szhzxw.cn
四、农业银行存算分离场景探索
1. AI平台落地
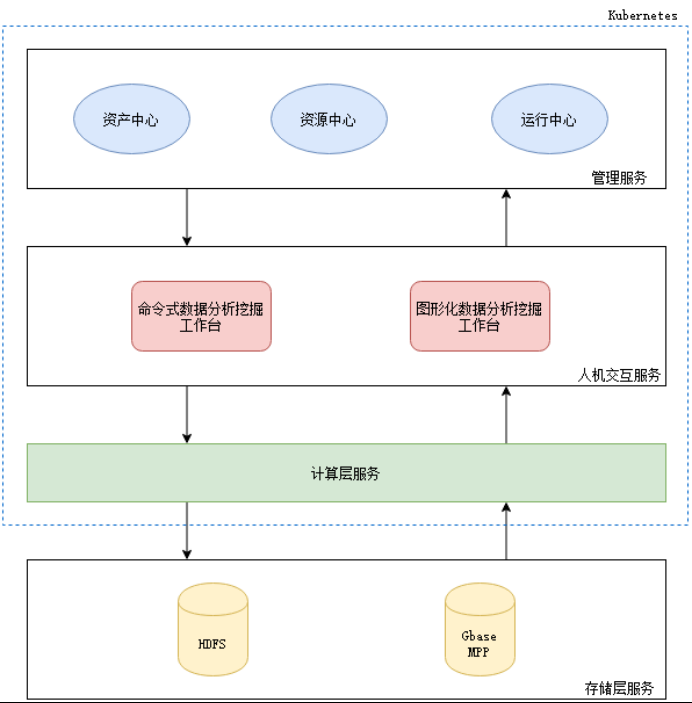
AI平台在农业银行IT基础架构中属于中后台版块,主要面向数据分析师提供数据探索、模型建模、模型生产部署等支持,具备完善的MLOps支撑能力。AI平台目前分为管理服务、人机交互服务、数据存储与计算服务三个部分,其中管理服务与人机交互服务已基于Kubernetes实现上云,而数据存储与计算依赖Gbase MPP与Hadoop集群属于云下部署。目前平台存在数据运维复杂度高,资源扩容不够灵活的问题,同时Gbase MPP与Hadoop对多租户资源隔离与生产运维支持也不够灵活。
计算存储分离架构将Hadoop服务拆分为计算层与存储层,计算层作为无状态服务上云,而存储层实现统一集中部署,架构设计如图2所示。计算存储分离架构完善了AI平台弹性多租户隔离机制、降低了数据运维复杂度、拆分了MLOps模式各参与方运维职责。
2. 新架构下的AI平台优势
(1)更优的多租户支持
基于逻辑模式设计的多租户模型实现了租户间的严格资源隔离。图3所示为AI平台租户在人机交互服务层、计算层、存储层均有逻辑资源池配额,其中人机交互服务为SaaS访问量配额,计算层通过K8s Namespace配额支持,存储层通过HDFS 目录SpaceQuota配额支持。同时,将数据分析项目资源管理权限下放至租户管理员,有效分摊管理成本。

(2)数据湖的直读支持
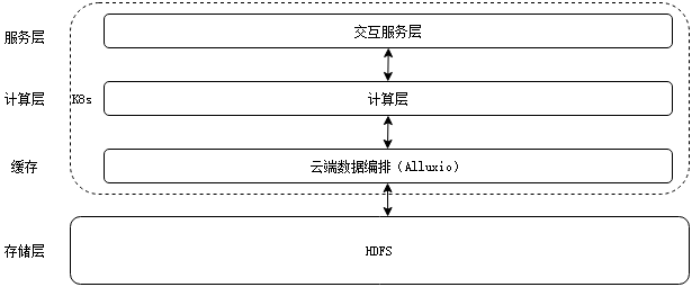
计算存储分离后,计算负载上云,存储端仅承担数据访问鉴权与数据IO负载,AI平台可以直接访问大数据平台数据湖和实时集市。在该模式下,各数据消费方无需再建设额外的数据同步系统,有效降低数据运维成本,最大程度保证数据消费实效性。如图4所示,Alluxio统一了存储在不同存储系统中的数据,为其上层数据驱动型应用(计算层)提供了统一的客户端API和全局命名空间。
(3)轻量化的MLOps运维支持
MLOps(Machine Learning Operations)是机器学习时代的DevOps,用来帮助机器学习有关人员更加高效的开发以及维护机器学习生产线。MLOps支持持续集成、持续交付和持续部署,具有更快地试验和开发模型、更快地将模型部署到生产环境和质量保证等特性。
计算存储分离架构将AI模型运行与数据运维解耦到K8s与HDFS两个基础设施中,助力进一步建立更轻量化的MLOps运维方案,各租户独立申请K8s计算资源来维护自己发布的模型,而存储层由平台方统一管理并运维。 数字化转型网www.szhzxw.cn
(4)AI模型的容器化支持
Python作为最流行的机器学习编程语言之一,被越来越多的业务研发人员用于AI模型建模开发。但Python版本与Hadoop中Spark版本通常依赖集群统一配置,这导致Python多版本支持与包管理较为复杂。计算层上云后,基于容器技术可以进行运行环境隔离从而实现Python运行环境多版本管理,提升系统灵活性,降低运维成本。 数字化转型网www.szhzxw.cn
五、总结展望
因为大数据运算过程涉及到CPU、内存、网络、存储等多种资源的巨大开销,大数据技术栈在K8s中的部署仍然处于起步阶段。为了适配K8s云原生接口,社区在不断完善计算引擎,以提供更好的租户支持、更弹性的资源管理与更优秀的性能。
存算分离的进一步发展可以为农业银行大数据基础架构带来一系列变革:
1. 存算分离后,各系统可以直接基于数据湖进行数据分析处理,减少系统间数据迁移同步,提升数据流水线时效性。 数字化转型网www.szhzxw.cn
2. 存算分离后,各计算引擎可兼容对象存储,从而进一步降低数据存储成本。
3. 存算分离后,可进行批量计算与在线服务的混合部署探索,基于两种负载的波峰时段不同,互相借用计算资源“削峰填谷”节省服务器成本。
未来,将在集成对象存储、云端数据编排、Spark Serverless等方面继续跟踪技术发展趋势,进一步完善农业银行云计算生态,助力数字化转型。
数字化转型网人工智能专题
与全球关注人工智能的顶尖精英一起学习!数字化转型网建立了一个专门讨论人工智能技术、产业、学术的研究学习社区,与各位研习社同学一起成长!欢迎扫码加入! 数字化转型网www.szhzxw.cn
本文由数字化转型网(www.szhzxw.cn)转载而成,来源于我们的开心;编辑/翻译:数字化转型网宁檬树。






