
近日,来自研究团队的一项新成果引起了广泛关注 ——CoMPaSS-FLUX.1模型。这是一种基于 FLUX.1文本到图像扩散模型的 LoRA 适配器,旨在显著提升生成图像时对物体空间关系的理解能力。该模型在处理物体的特定空间关系方面取得了显著进展,为图像生成领域带来了新的可能性。
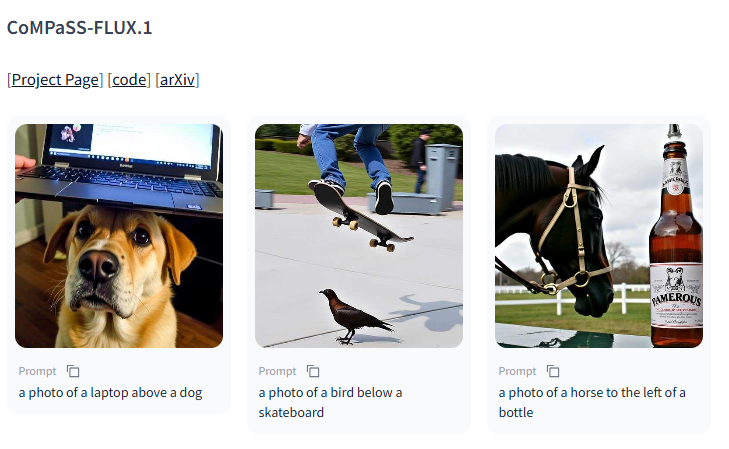
CoMPaSS-FLUX.1的基础模型为 FLUX.1-dev,其 LoRA 等级为16,文件大小约为50MB,使用了 Diffusers 框架。它的主要用途是生成具有准确空间关系的图像,能够创造需要特定空间排列的构图,同时在保持其他能力的基础上增强空间理解能力。
在性能表现上,CoMPaSS-FLUX.1的关键改进令人瞩目。根据 VISOR 基准测试,该模型的相对提升达到了98%;在 T2I-CompBench 空间测试中,提升幅度为67%;而在 GenEval 位置评估中,更是达到了131% 的相对改善。此外,CoMPaSS-FLUX.1在图像保真度上也表现不俗,FID 和 CMMD 分数均低于基础模型,表明其在生成质量上有所提升。
使用该模型时,用户可以参考其有效提示。模型在描述空间关系时表现最佳,特别是当提示中包含清晰的空间关系描述(如 “左边”、“右边”、“上面”、“下面”)时,或者是包含两个不同物体的明确空间关系描述(例如 “照片中 A 在 B 的右边”)。
在训练过程中,CoMPaSS-FLUX.1使用了来自 SCOP(空间约束导向配对)数据引擎的数据,涵盖了约28,000个经过精心挑选的物体对。这些数据在视觉重要性、语义区别、空间清晰度、物体关系和视觉平衡等方面都有严格的标准。
训练过程持续了24,000步,使用了批量大小为4的配置,学习率设定为1e-4,并采用了 AdamW 优化器,权重衰减设定为1e-2。
声明:本文来自AI新闻资讯,版权归作者所有。文章内容仅代表作者独立观点,不代表数字化转型网立场,转载目的在于传递更多信息。如有侵权,请联系我们。数字化转型网www.szhzxw.cn

本文由数字化转型网(www.szhzxw.cn)转载而成,来源于AI新闻资讯;编辑/翻译:数字化转型网(Professionalism Achieves Leadership 专业造就领导者)萍水

