
报告简介
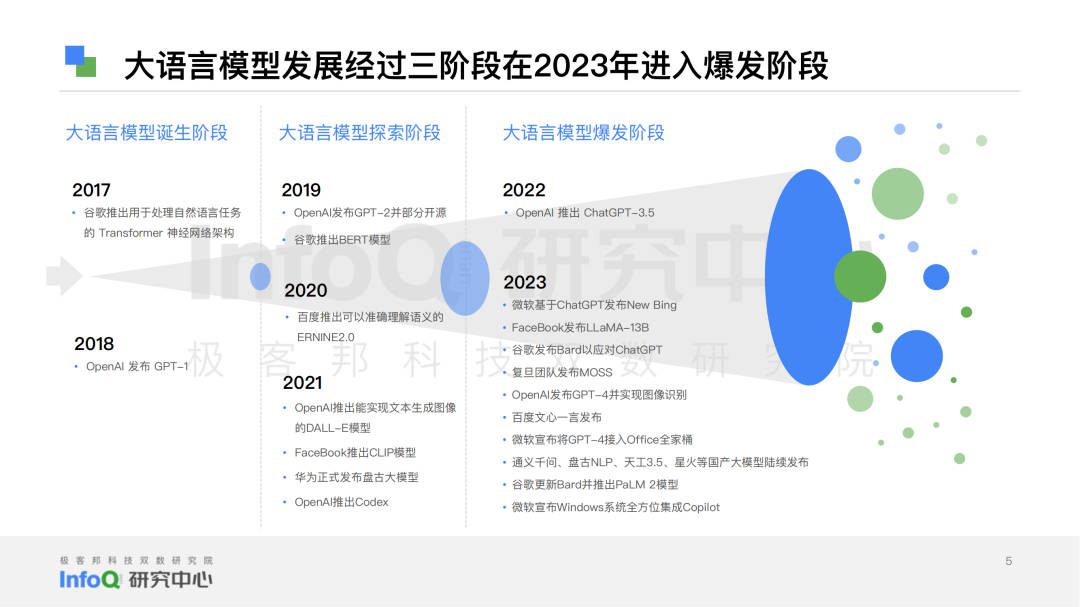
ChatGPT 这一现象级产品横空出世,拉开了大语言模型技术蓬勃发展的序幕。但实际上,自 2017 年大语言模型诞生,OpenAI、微软、谷歌、Facebook、百度、华为等科技巨头在大语言模型领域的探索持续不断,ChatGPT 只是将大语言模型技术推进至了爆发阶段,当下大模型产品格局更是呈现出了新形势——国外基础模型积累深厚,国内应用侧优先发力。
2022年年末以来,人工智能大模型成为技术领域乃至全球创新领域最炙手可热的话题。以ChatGPT引领的大模型产品发展日新月异,有预测数据显示,到2030年,AIGC的市场规模或将超过万亿人民币。2023年国内主要厂商也相继推出自研的大语言模型产品,另外国内也推出了大量的大语言模型应用,逐步构建起基于中文语言特色的大语言模型生态。
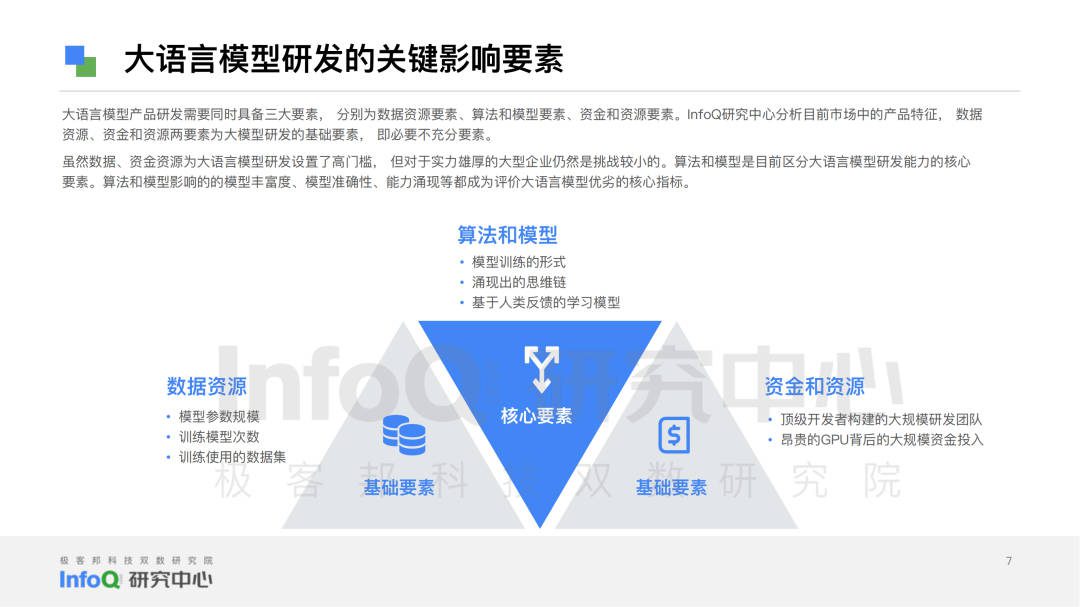
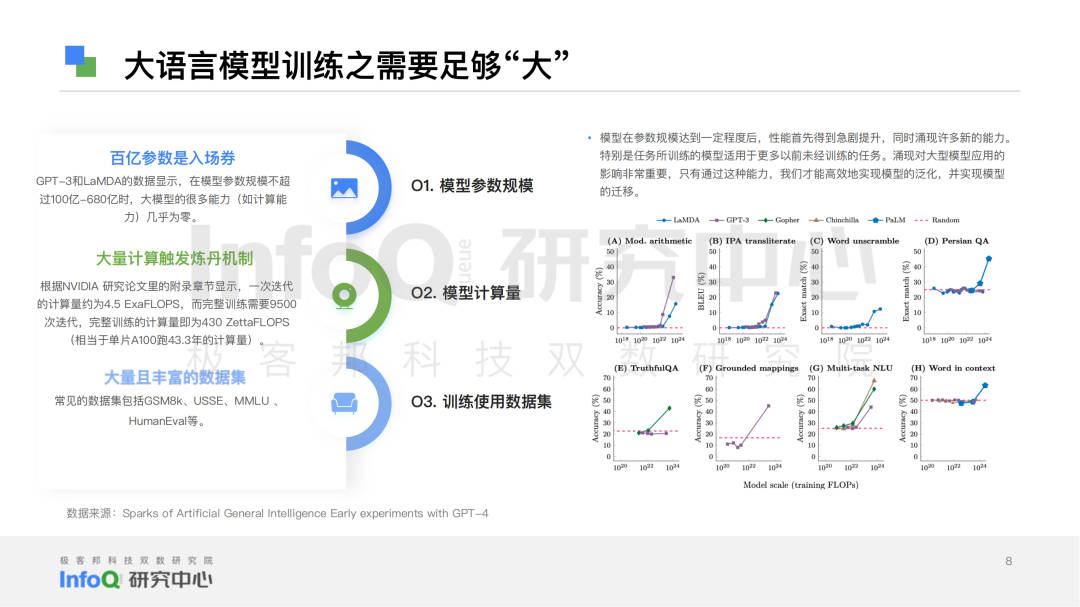
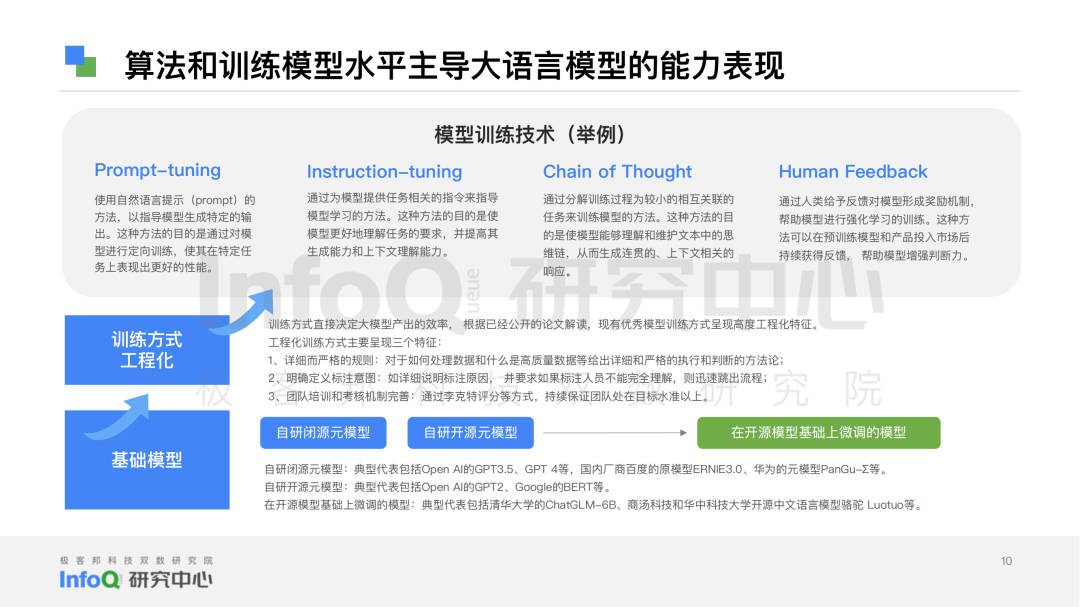
为此InfoQ研究中心基于桌面研究、专家访谈、科学分析三个研究方法,查找了大量文献及资料,采访了10+位领域内的技术专家,同时围绕语言模型准确性、数据基础、模型和算法的能力、安全和隐私四个大维度,拆分出语义理解、语法结构、知识问答、逻辑推理、代码能力、上下文理解、语境感知、多语言能力、多模态能力、数据基础、模型和算法的能力、安全和隐私12个细分维度。
分别对ChatGPTgpt-3.5-turbo、Claude-instant、Sagegpt-3.5-turbo、天工3.5、文心一言V2.0.1、通义千问V1.0.1、讯飞星火认知大模型、Moss-16B、ChatGLM-6B、vicuna-13B进行了超过3000+道题的评测,根据测评结果发布了《大语言模型综合能力测评报告2023》。
以下是报告节选。








翻译:
Introduction to the report
ChatGPT, a phenomenon product, was born and opened the prelude to the vigorous development of large language model technology. But in fact, since the birth of the big language model in 2017, OpenAI, Microsoft, Google, Facebook, Baidu, Huawei and other technology giants continue to explore the field of big language model. ChatGPT only pushed the big language model technology to the explosive stage. At present, the pattern of large model products is showing a new situation – the accumulation of foreign basic models is profound. And the domestic application side gives priority to force.
Since the end of 2022, AI large models have become the hottest topic in the technology field and even in the global innovation field. Large model products led by ChatGPT are developing rapidly. And it is predicted that by 2030, the market size of AIGC will exceed one trillion yuan. In 2023, major domestic manufacturers have also launched self-developed large language model products. And a large number of large language model applications have been launched in China. Gradually building a large language model ecology based on Chinese language characteristics.
Based on three research methods: desktop research, expert interview and scientific analysis
To this end, InfoQ Research Center based on three research methods: desktop research, expert interview and scientific analysis, searched a large amount of literature and materials, and interviewed 10+ technical experts in the field. At the same time, it focused on four major dimensions: language model accuracy, data basis, model and algorithm capability, security and privacy. It is divided into 12 sub-dimensions: semantic understanding, grammatical structure, knowledge question answering, logical reasoning, code ability, context understanding, context perception, multilingual ability, multimodal ability, data foundation, model and algorithm ability, security and privacy.
ChatGPTgpt-3.5-turbo, Claude instant, Sagegpt-3.5-turbo, Tiangong 3.5, Wenxin Yiyi V2.0.1, Tongyi Qianwen V1.0.1, IFlytek Spark Cognition model, Moss-16B, ChatGLM-6B, vicun, respectively a-13B evaluated more than 3,000 + questions, and based on the results of the evaluation, published the Comprehensive Ability Assessment Report of Large Language Models 2023.
Here are excerpts from the report.
本文由数字化转型网(www.szhzxw.cn)转载而成,来源于首席数字官;编辑:数字化转型网宁檬树。

免责声明: 本网站(https://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。


