
万亿商业帝国,往往始于一个简单的共识。
回溯电商之王亚马逊的历史,必然有经典的一幕:
2001年,先后经历了各类重大历史事件的美国,正处于低谷之中,所有公司都在经受严峻的环境考验。
而后,亚马逊CEO贝索斯迅速找到《从优秀到卓越》的作者吉姆·柯林斯,向他寻求关于亚马逊的战略发展建议,最后,贝索斯带着高管团队提出一个著名的模型:
通过低价策略,吸引更多的客户;更多的客户,则可以增加销量,吸引更多的第三方卖家来亚马逊网站开店,从而可以让亚马逊将物流和运营网站的成本降低;效率提升,则再度促进低价。
其中,每个环节如同齿轮一样互相吻合,每个环节的改善,都可以让整个系统加速运行——这便是亚马逊著名的“飞轮”效应,也是其业务增长的“秘密”所在。 数字化转型网(www.szhzxw.cn)
建立起与之匹配的业务和战略体系之后,亚马逊走上了高速增长之路。从2001年至今,亚马逊已经建立起包括电商、云计算、流媒体等业务的庞大商业版图。
“飞轮效应”的目标,其实是找到驱动增长的关键因素——本质上,某种程度上也意味着企业如何找到起自己的PMF(Product Market Fit),并且迅速扩大规模,这是所有企业都在寻找的永续经营的模式。而在当下的数智化时代,人们对“飞轮”效应的探索,从未停止。现在,这个关键因素几乎无法与“数据”脱离关系。
一、中台降温,对大数据的一次反思
数据是构建起互联网世界的“地基”。而大数据行业的历史,正是探索如何存储、应用海量数据的宏伟道路。
开源分布式计算平台Hadoop的出现,则改变了一切——让企业拥有存储海量数据的能力,从而建立起了数据资产。
在云计算时代到来之前的2000年左右,互联网世界还处于单机时代。雅虎、Linkedin、Facebook等新兴互联网公司为了应对高速发展的业务需求,纷纷采用以Hadoop为主的系统爬取、存储巨量数据的新技术,这也成为大数据和云计算行业的基础。
国内也有类似的数字化实践,在2015年前后兴起的火热的“中台”,正是国内企业数字化进程中的重要里程碑。 数字化转型网(www.szhzxw.cn)

“中台”一词最早来自阿里巴巴。2015年,阿里巴巴参考芬兰游戏公司Supercell的爆款游戏生产机制,建立起了“大中台,小前台”的架构:将通用的IT能力抽取出来组成一个大中台,为前端的业务部门赋能。
阿里巴巴以这套机制建立了大量中台,减少了IT资源的浪费。当中,数据中台的建设最为业界追捧,阿里巴巴凭借打造数据中台实现了统一融合的数据建设,进一步释放数据价值,这也引发了一轮效仿——在当时数字化的热潮之下,国内无论大小企业,不惜一掷千金,花费百万乃至千万元,也开始“大建数据中台”。
但苦涩的事实是,短短五年后,企业对于数据中台的热情却逐渐降温,不约而同进入“冷静期”。
听起来,数据中台极其符合商业逻辑。比如,前端的电商部门需要一套比价系统,中台部门调动资源开发对应的数据平台后,还能把这套系统模块化,等到其他部门需要的时候,经过轻量二次开发,就能迅速地复用其他业务之上,减少部门间“重复造轮子”的行为,数据在统一口径之后也能进行相对应复用。
但实际落地到企业当中,这套逻辑并不一定奏效。
“为做而做”,“求大求全”,使得数据中台难以为业务所用,也是许多数据中台项目失败的原因。
在数据中台建设的早期,业内还没有成熟的建设规则或者方法论,部分企业直接套用阿里的数据建设方法论,建设了许多不必要的功能。而在真正启用后,却发现功能和数据并不符合实际的业务场景需求,最终的结果就是“难用”,数据中台并不能被真正用起来,也就加难以收获业务端的认可。
在之前2020年的报道中,曾有IT从业者抛出一个精彩比喻:“中台不是万能药,大象吃这个药,强身健体;蚂蚁吃这个药,一击毙命。” 数字化转型网(www.szhzxw.cn)
对于业务体量够大的企业来说,照搬互联网大厂的方法论,也有可能也会水土不服。这类企业往往在建立数据中台的过程中用力过猛,将大量注意力放在数据资产基础设施的建设上,又“大而全”地对各类数据进行整理和统一,却忽略了自身业务的实际需求。数千万甚至亿级的资源和人力投入,却使得数据中台逐渐成为一个“为做而做”的项目,最终被巨大的建设成本拖累。
2021年开始,中台的发起者阿里巴巴推出了一系列将中台“打薄”的措施——主导阿里巴巴中台战略的前集团首席执行官张勇,开始持续发声:要把中台做得越来越薄,要让阿里的业务变得敏捷,取代阿里“大中台”战略。
这意味着,原来“什么都能往里装”的中台,如今要摆脱厚重的架构,与业务链接得更为紧密。
与此同时,在数据中台的建设中,企业愈发开始意识到,建中台不是本质目的,让数据真正被用起来,与业务产生紧密的关联才是数据中台成功的关键。
在这种趋势之下,“数据飞轮”的概念也随之兴起——围绕业务进行数据消费,从原来的“重点关注数据资产”,到“同步关注数据流与业务流的融合”,即充分考虑数据在业务中的应用,数据资产与业务应用形成闭环。 数字化转型网(www.szhzxw.cn)
数据飞轮的出现,意味着“中台”理论失效了吗?
对尚处在数字化初期的国内市场而言,数据中台对数字化概念的普及和落地功不可没。如今,“中台”并不能被称为失效,而是企业对数字化的认识来到了新阶段。“数据飞轮”,则可以看作这一概念演变的新一阶段。
在宏观环境变幻莫测之时,企业主更注重业务增量。数据中台的建设,不能作为成本中心而存在,而是要为业务带来实际效用,才能算得清这笔商业账。
这也能解释,为何近年来“数据飞轮”一词频频出现在人们的视野——“数据飞轮”更关注与业务之间的动态关联,强调“用数据”而非“存数据”。
企业数字化技术服务公司云徙科技是“中台”理论的重要实践者,如今也开始了对“数据飞轮”的探索。其副总裁在去年的数据飞轮消费行业研讨会上提到,尽管企业对数据消费有强烈的需求,但实际操作中却往往面临诸多挑战,真正将数据资产量化为业务价值,势必触及到对数据的精准把控与分析。对于新兴的数据飞轮理念,云徙科技和其他厂商一样,正在拥抱和认可其中的内涵。从这个维度来说,数据飞轮和数据中台并不对立。相反,数据飞轮可以说是中台理论的升级。
二、“数据消费时代”来临
“中台”时期,业界对数据仓库、湖仓一体等新兴技术的应用,为企业带来了十分珍贵的数据资产。中台强调“统一”——统一的技术、数据,相当于在传统IT架构下孤立的一个个软件之间搭建起了桥梁,有助于数据在底层的高频流通。 数字化转型网(www.szhzxw.cn)
但这一时期的关键问题在于,建立了数据资产后,企业的数据利用率却不高。
如今,全球数据以惊人速度增长,且没有任何放缓的迹象。根据福布斯专栏作家Bernard Marr的观点,全球超过90%的数据,都是在过去几年中被创建。但据Gartner的研究报告显示,如今还有68%的企业数据没有被用来分析、使用;而高达82%的企业仍处于数据孤岛之中。
电商是一个典型例子——购物大促时,会产生许多高并发的计算需求,并且需要实时取用数据,而数据也不只是报表等结构性数据,而是拥有包括图像、音视频在内的非结构化数据。
而在过去,传统意义上的数据仓库主要处理的是T+1数据,即今天产生的数据分析结果,明天才能看到。但现在,企业客户的数据需求,已经不是单纯的静态数据,而是实时、且有洞察的数据。
因此,中台为企业内部的数据资产“建立桥梁”远远不够。更重要的,是要在企业内部建立起一套数据流通的有效模式。
“数据消费”这一概念,正是在这一语境下被提出。
领克汽车就是成功从“数据困境”中走出的企业——此前,和其他的技术密集型企业一样,领克也建立起了一套完善的企业数据底座。
“我们手上也有APP的日活、月活等数据,但对于数据背后的意义、价值,我们是并不明确的。”吉利汽车集团营销数字中心负责人沈稳杰表示。
为了搞明白这些数据,领克汽车的运营团队选择了与火山引擎达成合作,基于火山引擎旗下的数据产品增长分析DataFinder,开展了一次创新的降价拍卖直播活动——拿出一辆车,在规定时间内,用户来参与直播出价拍卖。 数字化转型网(www.szhzxw.cn)
“通过直播拍卖活动,我们拿到了非常有趣的一组数据:围观的用户接近2万,而出价用户超过1000左右。我们再继续对出价的用户进行打标签、细分,确认有意购车的用户。”后面的两个月里,领克对出价的用户持续给予一些优惠、优惠激励——最终,达成汽车订单数超过200。
其中,火山引擎数智平台VeDI的产品不仅能够帮助领克实时观测到这些数据,并且还能够在这一创新场景里,帮助业务人员实现数据消费的全流程。如今,基于增长分析DataFinder,领克能够清楚地了解到领克APP每天的日活用户从哪来、又去了哪里,他们更关注什么等等。基于用户的关注点,团队再动态对业务策略进行调整。
领克的例子正是说明,“数据消费”是构建数据飞轮的必要前提,一切数据资产建设都需要围绕数据消费进行建设——才能有效地驱动增长。
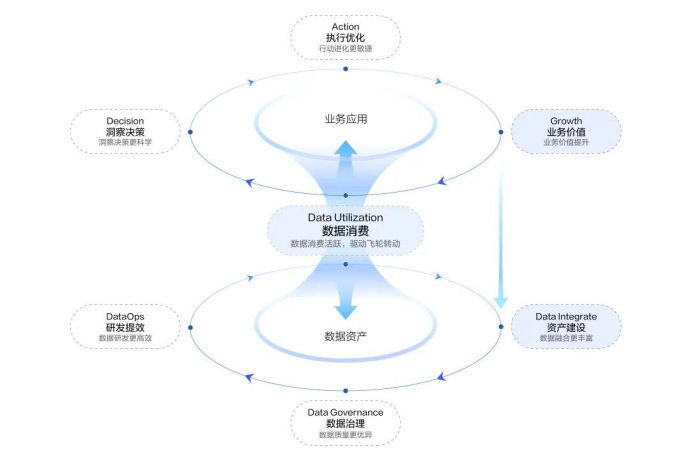
在建设数据底座时,企业就得想明白“把数据消费作为目标”,建设符合自己业务形态的数据基础设施。企业内的各项应用,应该是当场景、业务需要之时,才开发相应的数据工具,而非照搬大公司的方案、模版。 数字化转型网(www.szhzxw.cn)
那么,为何企业现在需要格外强调“数据消费”?这由互联网的发展阶段所决定。
在以往的粗放增长时期,企业可以用投放、买量实现增长,增长可以掩盖很多数据问题;但在存量竞争时代,拼的是精细化运营,精细化的策略则来自对数据的洞察。在这一阶段,企业数字化的终点,不是数据资产的建设,而是数据在业务场景的频繁应用。
还是以字节跳动为例。多数人关注字节的组织战略,往往从扁平、透明的组织架构开始,还有一部分不可忽视,则是内部对“把数据用起来”的极度重视。
据了解,字节跳动内部关于“数据消费”有2个“80%”,一是80%的企业员工能够直接使用数据产品,二是数据资产能覆盖到80%的分析场景。
这造成一个神奇的景象。80%的字节员工每天在通过各种各样的数据产品使用数据,进行数据消费,既包括以往主要和数据打交道的专业人员——数据工程师、数据分析师等等,也包含产品、运营、市场,甚至行政、HR、UED这些离IT、数据比较远的人。这也能解释,数据驱动为何会成为字节跳动的文化之一——因为几乎大部分人都能够高效地获取自己需要的数据,辅助自身的业务,而不需要等待来自上级的决策再进行实施。以数据消费驱动企业增长,并且达到业务目标后,如此反复,成为闭环。数据消费,已经逐步成为企业经营的必备一环。
三、大模型时代,用数据飞轮重塑数智化逻辑
从2023年开始的生成式AI(Gen AI)热潮,则会加速“数据消费”这一认知成为共识,对大数据领域影响深远。 数字化转型网(www.szhzxw.cn)
生成式AI的训练和应用都重度依赖数据,这本身就是一种“数据消费”,而要想让模型质量更高,AI在实际业务中应用落地的数据反哺又至关重要。
数据库巨头Databricks就在2023的年末总结里提出:“未来的大数据架构将是一个高度集成、智能化和自动化的系统,它能够有效地处理和分析大量数据,同时简化数据管理和AI应用的开发过程,为企业提供竞争优势……在不久的未来,每个领域的赢家,都是那些最有效利用数据和AI的企业。”
如今,大模型想在企业侧落地,意味着企业自身的数据和算力规模都会不断加大——未来,企业不仅是需要更多数据,更重要的是要更会使用数据。而数据消费,又会反哺到应用和底层的数据基建建设之中。
百度董事长李彦宏就曾表示:“AI原生应用会驱动模型、芯片等AI技术栈的发展,只有通过更多的场景落地应用,才能够形成更大的数据飞轮,才能够让芯片做到够用和好用。”
幸运的是,在数据应用上,大模型未来会成为用户的有力助手。大模型使得人与机器的交互形式发生根本性的变化,这会有效地降低用户的数据消费门槛。
传统数据分析方式将会发生巨大变化——从前,如果业务人员需要找一个分析数据,轻则需要学习BI等分析工具,重则需要找专业的IT人员提需求。
但在大模型诞生后,垂直领域的数据搜索将会变得更容易,只要用自然语言和模型交互,模型即可提取相应数据,大大提升在数据分析上的人效。
但这也意味着,未来使用数据的门槛会降低,而对数据质量的要求则会进一步提高,企业要想真正享受到生成式AI带来的业务红利,需要更加强健的数据基础设施,以及建立起良性的数据消费模式,挖掘业务数据中更深层次的价值。 数字化转型网(www.szhzxw.cn)
更多的人使用大模型提取和分析数据,这对企业的数据基础设施提出了更高的要求——OpenAI每次发布新功能后,宕机现象仍然频发,则是当前底层设施尚未很好适配大模型的证明。
数据基础设施如同土壤,只有足够强大,才能够孵化出有爆发潜力的AI原生应用。对此,企业需要更精细化地建设数据基础设施,配合业务流建立起数据采集、存储、分析层面的工具。而在数据上,更需要高质量且完整的数据,更好加以治理,统一标准和口径,为数据的使用做好准备。
最后,企业需要找到一个数据消费场景,让大量用户使用,模型才能不断迭代,让性能更强——这与数据飞轮理论,也不谋而合。
早在2013年,《大数据时代》一书作者维克托·尔耶·舍恩伯格就表示,大数据开启了一次重大的“时代转型”,其带来的信息风暴正在变革我们的生活、工作和思维,社会也将经历类似的地壳运动。
十年过后,随着数字化进程的深入,“数据飞轮”成为一个新的阶段,帮助企业构建数智化竞争力的边界——谁能更好地转动起数据飞轮,谁就能真正掌握未来。
翻译:
After the data center | cools down, how to solve the next game of enterprise data intelligence?
Trillions of business empires often start with a simple consensus.
Looking back at the history of Amazon, the king of e-commerce, there is bound to be a classic scene:
In 2001, the United States, which has experienced various major historical events, is at a low point, and all companies are undergoing severe environmental tests.
Then, Amazon CEO Bezos quickly found Jim Collins, the author of “From Good to Great,” to seek his advice on Amazon’s strategic development, and finally, Bezos took the senior management team to propose a famous model: 数字化转型网(www.szhzxw.cn)
Attract more customers through low price strategy; More customers can increase sales and attract more third-party sellers to set up shop on Amazon’s website, so that Amazon can reduce the cost of logistics and website operation; Efficiency gains, in turn, promote lower prices again.
Among them, each link is like a gear, and the improvement of each link can speed up the entire system – this is the famous “flywheel” effect of Amazon, and the “secret” of its business growth.
After establishing a business and strategic system to match it, Amazon embarked on a path of rapid growth. Since 2001, Amazon has established a huge business territory including e-commerce, cloud computing, streaming media and other businesses.
The goal of the flywheel effect is to find the key drivers of growth – in essence, it means to some extent how companies can find their own PMF (Product Market Fit) and scale rapidly, which is the sustainable business model that all companies are looking for. In the current era of digital intelligence, people’s exploration of the “flywheel” effect has never stopped. Now, this key factor can hardly be divorced from “data.” 数字化转型网(www.szhzxw.cn)
First, the central cooling, a reflection on big data
Data is the “foundation” that builds the Internet world. The history of the big data industry is a grand road to explore how to store and apply massive data.
The advent of Hadoop, an open-source distributed computing platform, changed everything – giving companies the ability to store massive amounts of data, thereby building data assets.
About 2000 years before the advent of the cloud computing era, the Internet world was still in the single-machine era. In order to cope with the rapid development of business needs, emerging Internet companies such as Yahoo, Linkedin and Facebook have adopted the new technology of system crawling and storing huge amounts of data based on Hadoop, which has also become the basis of big data and cloud computing industry.
There are similar digital practices in China, and the hot “middle Taiwan” that emerged around 2015 is an important milestone in the digitization process of domestic enterprises.
The term “Zhongtai” first came from Alibaba. In 2015, with reference to the production mechanism of blockbuster games of the Finnish game company Supercell, Alibaba established the architecture of “big middle desk, small front desk” : IT extracted general IT capabilities to form a big middle desk, enabling the front-end business departments.
Alibaba has established a large number of middle desks with this mechanism, reducing the waste of IT resources. Among them, the construction of the data center is the most sought after by the industry, Alibaba with the creation of data center to achieve a unified integration of data construction, further release the value of data, which also triggered a round of imitation – under the digital boom at that time, domestic enterprises, regardless of size, at no cost, spending millions or even tens of millions of yuan, also began to “build data center”. 数字化转型网(www.szhzxw.cn)
But the bitter fact is that just five years later, the enthusiasm of enterprises for data center has gradually cooled, and coincidentally entered the “cooling-off period”.
It sounds like a data center makes perfect business sense. For example, the front-end e-commerce department needs a set of price comparison system, and the middle department can mobilize resources to develop the corresponding data platform, but also the modular system, until other departments need, after lightweight secondary development, it can be quickly reused on other businesses, reduce the “repetitive wheel” behavior between departments, and the data can also be reused correspondingly after a unified caliber.
But the actual landing in the enterprise, this logic does not necessarily work.
“Do it for the sake of doing it” and “seek greater perfection” make it difficult for the data center to be used by the business, and it is also the reason for the failure of many data center projects.
In the early stage of data center construction, there was no mature construction rules or methodology in the industry, and some enterprises directly applied Ali’s data construction methodology to build many unnecessary functions. After it is really enabled, it is found that the functions and data do not meet the actual requirements of the business scenario, and the final result is “difficult to use”, and the data center can not be really used, which is difficult to gain the recognition of the business side.
In the previous report in 2020, there was an IT practitioner who threw out a wonderful metaphor: “Middle Taiwan is not a panacea, elephants eat this medicine, physical health; Ants eat this medicine and kill themselves with one shot.” 数字化转型网(www.szhzxw.cn)
For enterprises with large enough business volume, copying the methodology of the Internet factory may also be unadaptable. Such enterprises often exert too much force in the process of establishing the data center, pay a lot of attention to the construction of data asset infrastructure, and organize and unify all kinds of data “large and comprehensive”, but ignore the actual needs of their own business. Tens of millions or even billions of resources and manpower investment, but the data center gradually become a “do to do” project, and eventually be dragged down by huge construction costs.
Starting in 2021, Alibaba, the initiator of Middle Taiwan, launched a series of measures to “thin” middle Taiwan – Zhang Yong, the former group CEO who dominated Alibaba’s Middle Taiwan strategy, began to continue to voice: to make Middle Taiwan thinner and thinner, to make Ali’s business become agile, and to replace Ali’s “big Middle Taiwan” strategy.
This means that the original “everything can be installed” in the middle, and now to get rid of the heavy structure, and more closely linked to the business.
At the same time, in the construction of the data center, enterprises are increasingly beginning to realize that the construction of the data center is not the essential purpose, so that the data is really used and has a close relationship with the business is the key to the success of the data center.
Under this trend, the concept of “data flywheel” has also emerged – data consumption around the business, from the original “focus on data assets” to “synchronously focus on the integration of data flow and business flow”, that is, fully consider the application of data in the business, data assets and business applications form a closed loop. 数字化转型网(www.szhzxw.cn)
Does the emergence of the data flywheel mean that the “mid-table” theory has failed?
For the domestic market, which is still in the early stage of digitalization, the popularization and landing of the digital concept of the data center is indispensable. Today, the “middle desk” cannot be called ineffective, but the enterprise’s understanding of digitalization has come to a new stage. The “data flywheel” can be seen as a new stage in the evolution of this concept.
When the macro environment is changing, business owners are more focused on incremental business. The construction of the data center cannot exist as a cost center, but it must bring practical utility to the business in order to calculate the business account.
This can also explain why the term “data flywheel” has appeared frequently in people’s field of view in recent years – “data flywheel” focuses more on the dynamic relationship between the business and the emphasis on “using data” rather than “storing data”.
Cloud Migration Technology, an enterprise digital technology service company, is an important practitioner of the “middle platform” theory, and now it has also begun to explore the “data flywheel”. Its vice president mentioned at the data flywheel consumer industry seminar last year that although enterprises have a strong demand for data consumption, they often face many challenges in actual operation, and the real quantification of data assets into business value is bound to touch the accurate control and analysis of data. For the emerging data flywheel concept, cloud migration technology, like other manufacturers, is embracing and recognizing its connotation. In this dimension, the data flywheel and the data center are not opposites. On the contrary, the data flywheel can be said to be an upgrade of the mid-table theory.
Second, the “era of data consumption” is coming
During the “Taiwan” period, the industry’s application of emerging technologies such as data warehouse and lake warehouse integration has brought valuable data assets to enterprises. Zhongtai emphasizes “unity” – unified technology and data, which is equivalent to building a bridge between isolated software under the traditional IT architecture, helping to facilitate the high-frequency circulation of data at the bottom. 数字化转型网(www.szhzxw.cn)
But the key problem in this period is that once the data assets are established, the enterprise’s data utilization is not high.
Today, global data is growing at a phenomenal rate and shows no signs of slowing down. According to Forbes columnist Bernard Marr, more than 90 percent of the world’s data has been created in the past few years. According to Gartner, 68 percent of enterprise data is not being analyzed or used. A whopping 82% of enterprises are still in data silos.
E-commerce is a typical example – when shopping is promoted, it will produce a lot of highly concurrent computing needs, and it needs real-time access to data, and the data is not only structural data such as reports, but also has unstructured data including images, audio and video.
In the past, the traditional data warehouse mainly dealt with T+1 data, that is, the data analysis results produced today, can only be seen tomorrow. But now, the data needs of enterprise customers are not simply static data, but real-time and insightful data.
Therefore, it is not enough to “build Bridges” for data assets within the enterprise. More importantly, it is necessary to establish an effective model of data flow within the enterprise.
The concept of “data consumption” was put forward in this context.
Lynk & Co Automotive is the company that has successfully emerged from the “data dilemma” – before, like other technology-intensive enterprises, Lynk & Co has also established a complete set of enterprise data base. 数字化转型网(www.szhzxw.cn)
“We also have data on daily and monthly APP activity, but we are not clear about the meaning and value behind the data.” Geely Auto Group marketing digital center head Shen Wenjie said.
In order to understand these data, Lynk & Co’s operations team chose to cooperate with Volcanic Engine, based on Volcanic Engine’s data product growth analysis DataFinder, to carry out an innovative price auction live activity – take out a car, within a specified time, users to participate in the live bidding auction.
“Through the live auction, we got a very interesting set of data: nearly 20,000 spectators, and more than 1,000 bidders. We then continue to tag and segment the bidders to identify those who are interested in buying a car.” In the following two months, Lynk & Co continued to give some concessions and preferential incentives to users who bid – and finally reached a number of car orders of more than 200.
Among them, VeDI’s products can not only help Lynk & Co to observe these data in real time, but also help business personnel realize the whole process of data consumption in this innovative scenario. Today, based on growth analytics DataFinder, Lynk & Co can clearly understand where the daily active users of the Lynk & Co APP are coming from, where they are going, what they are paying more attention to, and more. Based on the concerns of the users, the team dynamically adjusts the business strategy.
Lynk & Co’s example illustrates that “data consumption” is a necessary prerequisite for building a data flywheel, and all data asset construction needs to be built around data consumption – in order to effectively drive growth. 数字化转型网(www.szhzxw.cn)
The “data flywheel” theory of volcanic engines
When building a data base, enterprises have to think about “taking data consumption as a goal” and build a data infrastructure that fits their business form. The various applications in the enterprise should develop corresponding data tools when the scene and business needs, rather than copying the schemes and templates of large companies.
So why do companies need to put more emphasis on “data consumption” now? This is determined by the development stage of the Internet.
In the past period of extensive growth, enterprises can use investment, purchase volume to achieve growth, growth can cover up a lot of data problems; However, in the era of stock competition, it is a fine operation, and the fine strategy comes from the insight of the data. At this stage, the end point of enterprise digitization is not the construction of data assets, but the frequent application of data in business scenarios.
Again, take Bytedance. Most people focus on the byte-oriented organizational strategy, often starting with a flat, transparent organizational structure, and part of the important is the internal emphasis on “putting data to work.” 数字化转型网(www.szhzxw.cn)
It is understood that there are two “80%” in Bytedance’s internal “data consumption”, one is that 80% of enterprise employees can directly use data products, and the other is that data assets can cover 80% of analysis scenarios.
This makes for a magical sight. 80% of byte employees use data and consume data through a variety of data products every day, including professionals who mainly deal with data in the past – data engineers, data analysts, etc., but also products, operations, marketing, and even administration, HR, UED, which are far away from IT and data. This also explains why data-driven is part of Bytedance’s culture – almost everyone is able to efficiently access the data they need to support their business without waiting for a decision from a higher authority to implement it. Using data consumption to drive enterprise growth, and after reaching business goals, so repeated, become a closed loop. Data consumption has gradually become a necessary part of business operations.
Third, in the era of large models, using data flywheel to reshape data intelligence logic
The generative AI (Gen AI) boom starting in 2023 will accelerate the perception of “data consumption” and have a profound impact on the field of big data.
The training and application of generative AI are heavily dependent on data, which is itself a kind of “data consumption”, and in order to make the model quality higher, the data feeding of AI application in the actual business is crucial. 数字化转型网(www.szhzxw.cn)
Database giant Databricks put forward in the end of 2023 summary: “The future big data architecture will be a highly integrated, intelligent and automated system, which can effectively process and analyze large amounts of data, while simplifying the development process of data management and AI applications, providing enterprises with competitive advantages.” In the near future, the winners in every field will be those that make the most effective use of data and AI.”
Today, the large model wants to land on the enterprise side, which means that the scale of the enterprise’s own data and computing power will continue to increase – in the future, enterprises not only need more data, but more importantly, they will use data more. Data consumption, in turn, feeds back into applications and the underlying data infrastructure.
Robin Li, chairman of Baidu, said: “AI native applications will drive the development of AI technology stacks such as models and chips, and only through more scene landing applications can a larger data flywheel be formed, and the chip can be sufficient and easy to use.”
Fortunately, when it comes to data applications, big models will be a powerful assistant to users in the future. Large models enable a fundamental change in the way humans interact with machines, which will effectively lower the threshold for data consumption by users.
The traditional way of data analysis will change dramatically – in the past, if business personnel need to find an analysis of data, they need to learn analysis tools such as BI, and they need to find professional IT personnel to raise needs. 数字化转型网(www.szhzxw.cn)
However, after the birth of large models, vertical domain data search will become easier, as long as the natural language and model interaction, the model can extract the corresponding data, greatly improving the human efficiency in data analysis.
However, this also means that the threshold for the use of data in the future will be lowered, and the requirements for data quality will be further improved. In order for enterprises to truly enjoy the business dividends brought by generative AI, they need a more robust data infrastructure, as well as the establishment of a benign data consumption model, and the mining of deeper value in business data.
More people are using large models to extract and analyze data, which puts higher demands on the enterprise’s data infrastructure – downtime is still frequent after each OpenAI release of new features, which is proof that the current underlying infrastructure is not well adapted to the large model.
The data infrastructure, like the soil, has to be strong enough to incubate native AI applications with explosive potential. In this regard, enterprises need to build more refined data infrastructure, and build tools for data collection, storage, and analysis with business flow. In terms of data, there is a greater need for high-quality and complete data, better governance, unified standards and caliber, and preparation for the use of data.
Finally, enterprises need to find a data consumption scenario that allows a large number of users to use, so that the model can be iterated continuously and the performance is stronger – which coincides with the data flywheel theory. 数字化转型网(www.szhzxw.cn)
As early as 2013, Victor Yerye Schonberg, author of the Age of Big Data, said that big data has opened a major “transformation of The Times”, and the storm of information it brings is transforming our lives, work and thinking, and society will also experience a similar crustal movement.
Ten years later, with the deepening of the digital process, the “data flywheel” has become a new stage to help enterprises build the boundary of digital intelligence competitiveness – who can better turn the data flywheel, who can truly grasp the future.
本文由数字化转型网(www.szhzxw.cn)转载而成,来源于36氪;编辑/翻译:数字化转型网宁檬树。

免责声明: 本网站(https://www.szhzxw.cn/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等) 版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。


